MedAlign
收藏arXiv2023-12-24 更新2024-06-21 收录
下载链接:
https://medalign.stanford.edu
下载链接
链接失效反馈官方服务:
资源简介:
MedAlign数据集是由斯坦福大学医学院的15名临床医生生成的,专门设计用于评估大型语言模型(LLMs)在处理电子健康记录(EHR)数据时的表现。该数据集包含983条自然语言指令,覆盖7个医学专业,旨在模拟临床环境中医生可能遇到的复杂信息需求和文档负担。数据集不仅包括指令,还提供了303条指令的临床医生编写的参考答案和276个纵向EHR,以便于评估LLMs的响应质量。MedAlign数据集的开发是为了解决现有EHR相关数据集未能充分捕捉临床医生实际工作中的信息需求和文档复杂性的问题。通过此数据集,研究者可以更准确地评估和改进LLMs在医疗领域的应用,从而减轻医生的行政负担,提高医疗质量。
The MedAlign dataset was generated by 15 clinicians from Stanford University School of Medicine, and is specifically designed to evaluate the performance of large language models (LLMs) when processing electronic health record (EHR) data. It contains 983 natural language instructions spanning 7 medical specialties, aiming to simulate the complex information needs and documentation burdens that clinicians may encounter in clinical settings. In addition to the instructions, the dataset also provides clinician-written reference answers for 303 of these instructions and 276 longitudinal EHRs, to facilitate the evaluation of LLM response quality. The MedAlign dataset was developed to address the gap that existing EHR-related datasets fail to fully capture the information needs and documentation complexity encountered in clinicians' actual clinical work. With this dataset, researchers can more accurately evaluate and improve the application of LLMs in the medical field, thereby alleviating clinicians' administrative burdens and enhancing healthcare quality.
提供机构:
斯坦福大学医学院生物医学数据科学系
创建时间:
2023-08-27
搜集汇总
数据集介绍
构建方式
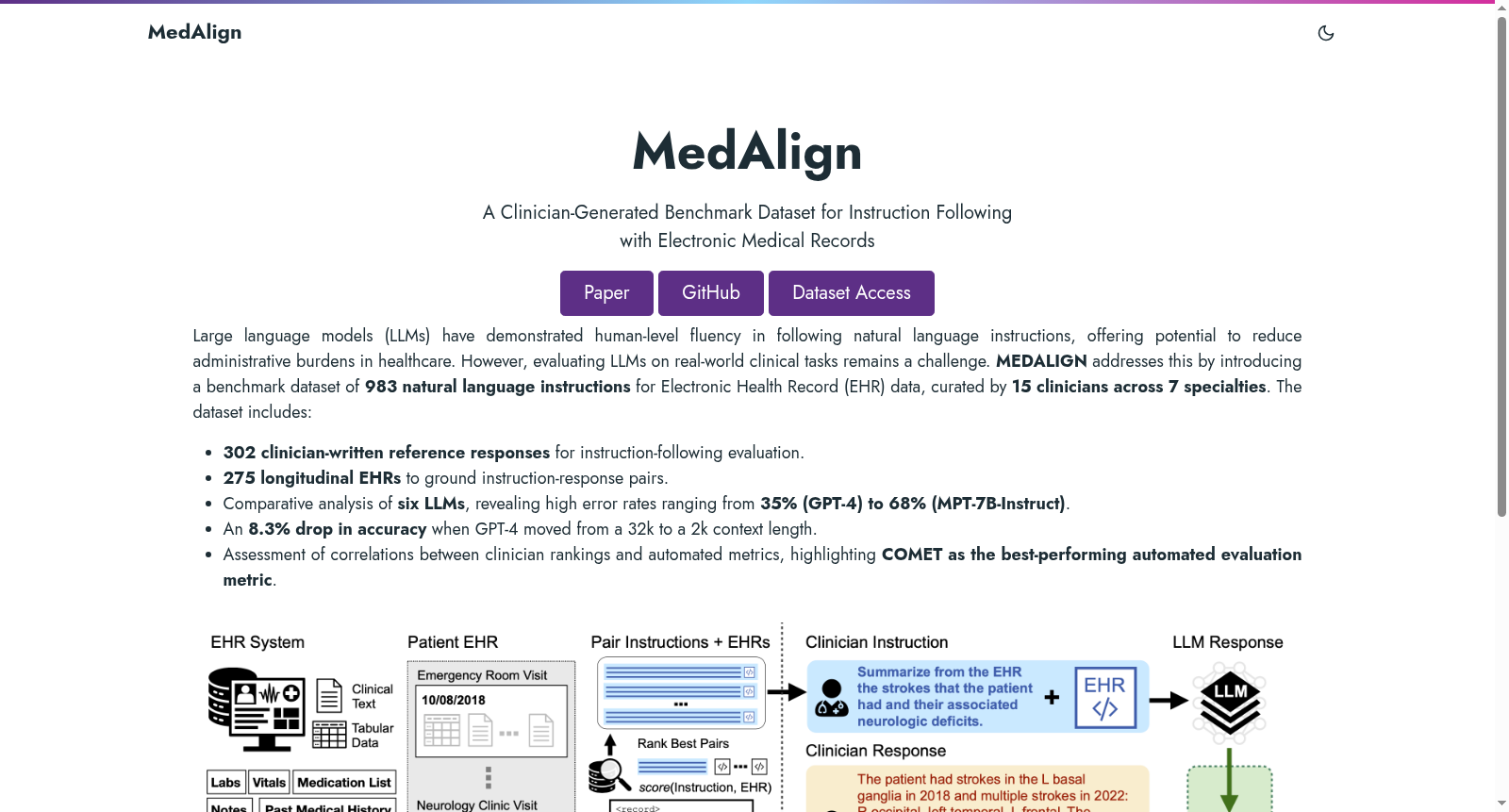
在电子健康记录(EHR)智能化应用日益受到关注的背景下,MedAlign数据集的构建采用了创新的模块化流程。首先,通过在线表单征集了来自7个医学专科的15名临床医生提交的983条自然语言指令,涵盖检索总结、诊疗规划等多种临床任务。随后,采用基于BM25算法的检索方法,将指令与来自276份纵向EHR的标准化XML标记进行匹配,确保74%的指令能关联到相关病历。最后,由临床医生对303条指令撰写黄金标准回答,并评估6种大语言模型的生成结果,形成完整的指令-病历-回答三元组基准。
特点
MedAlign数据集的核心特点在于其高度的临床真实性与复杂性。它首次整合了由临床医生实际撰写的多样化指令,覆盖从简单信息检索到复杂诊疗规划的全方位任务,突破了传统医学问答数据集局限于选择题或模板化问题的局限。数据集提供了完整的纵向EHR数据,包含结构化表格与非结构化文本,模拟了真实的临床信息环境。尤为重要的是,它包含了临床医生对模型输出的准确性评估与质量排名,为衡量大语言模型在真实医疗场景中的指令遵循能力提供了可靠依据。
使用方法
该数据集主要服务于医疗人工智能领域的模型评估与算法研究。研究者可利用其丰富的指令-病历对,系统评估大语言模型在理解复杂临床指令、整合多源EHR信息以及生成准确回答方面的性能。数据集提供的临床医生排名与多种自动评估指标(如COMET、BERTScore)的关联分析,为开发无需人工标注的自动化评估方法提供了基准。此外,MedAlign可用于探索检索增强生成、长上下文建模等技术在医疗领域的应用,推动开发能够真正减轻临床文书负担的智能辅助系统。
背景与挑战
背景概述
在医疗人工智能领域,大型语言模型(LLM)展现出遵循自然语言指令的潜力,有望减轻临床文档负担并提升医疗质量。然而,现有电子健康记录(EHR)问答数据集难以捕捉临床实践中复杂的信息需求与文档挑战。为此,斯坦福大学医学院等机构的研究团队于2023年推出了MedAlign数据集,该数据集由15名临床医生(涵盖7个专科)创建,包含983条自然语言指令、303条临床医生撰写的参考回答以及276份纵向EHR数据。其核心研究问题在于评估LLM在真实临床任务中的指令遵循能力,特别是针对EHR数据的复杂查询与生成任务。MedAlign通过提供首个由临床医生生成且基于全面EHR的指令-回答对基准,为医疗AI研究提供了关键评估工具,推动了LLM在临床环境中的可靠应用。
当前挑战
MedAlign数据集面临的挑战主要体现在两个方面:其一,在领域问题层面,该数据集旨在解决LLM在电子健康记录中执行复杂临床指令的挑战,例如从多源异构数据中检索与总结患者病史、制定护理计划或支持诊断决策。这些任务要求模型具备长上下文理解、医学知识融合与临床逻辑推理能力,而现有LLM在有限上下文长度下错误率较高(如GPT-4在2k上下文中的准确率较32k下降8.3%),且医疗指令调优模型在长上下文任务中表现显著退化。其二,在构建过程中,数据集创建面临临床医生参与的高成本与逻辑复杂性,包括指令与EHR的精准匹配难题(仅74%的指令通过检索方法与相关EHR成功配对),以及保护患者隐私与合规使用数据的安全要求,这些因素共同增加了高质量数据收集与标注的难度。
常用场景
经典使用场景
在临床信息学领域,MedAlign数据集为评估大型语言模型在电子健康记录指令遵循任务中的表现提供了基准。该数据集通过收集来自多个医学专科的临床医师生成的983条自然语言指令,并结合276份纵向EHR数据,构建了指令-响应对。其经典使用场景在于系统性地测试模型在真实临床环境下的信息检索、总结和任务执行能力,例如从复杂病历中提取卒中病史或生成哮喘护理计划。这种设计使得研究者能够量化模型在模拟实际工作流程中的准确性与可靠性,为医疗人工智能的效能评估奠定了实证基础。
实际应用
在实际医疗场景中,MedAlign数据集的应用直接关联到临床工作流的优化与自动化。通过评估模型在指令遵循任务中的表现,该数据集为开发智能临床辅助系统提供了关键验证工具。例如,模型可被用于自动生成患者病史摘要、辅助制定护理计划或支持诊断推理,从而减少医师在电子健康记录系统中的文档时间。研究表明,临床医师每日近半数时间耗费于计算机交互,而MedAlign通过量化模型在真实任务中的效能,为降低职业倦怠、提升诊疗效率提供了数据驱动的解决方案。
衍生相关工作
基于MedAlign数据集,多项经典研究工作得以衍生,进一步拓展了医疗语言模型的研究边界。该数据集启发了对模型上下文长度影响效能的深入分析,揭示了在长文档处理中扩展上下文窗口的重要性。同时,其构建的自动评估框架促进了如COMET等指标在临床文本生成任务中的适配与应用。此外,MedAlign为后续医疗指令微调模型的开发提供了基准,推动了AlpaCare、ClinicalCamel等专业模型在复杂临床任务上的性能优化,并引导研究社区关注超越传统医学问答的实用化评估范式。
以上内容由遇见数据集搜集并总结生成


