patho-ssl-data-curation
收藏Hugging Face2025-06-02 更新2025-06-03 收录
下载链接:
https://huggingface.co/datasets/swiss-ai/patho-ssl-data-curation
下载链接
链接失效反馈官方服务:
资源简介:
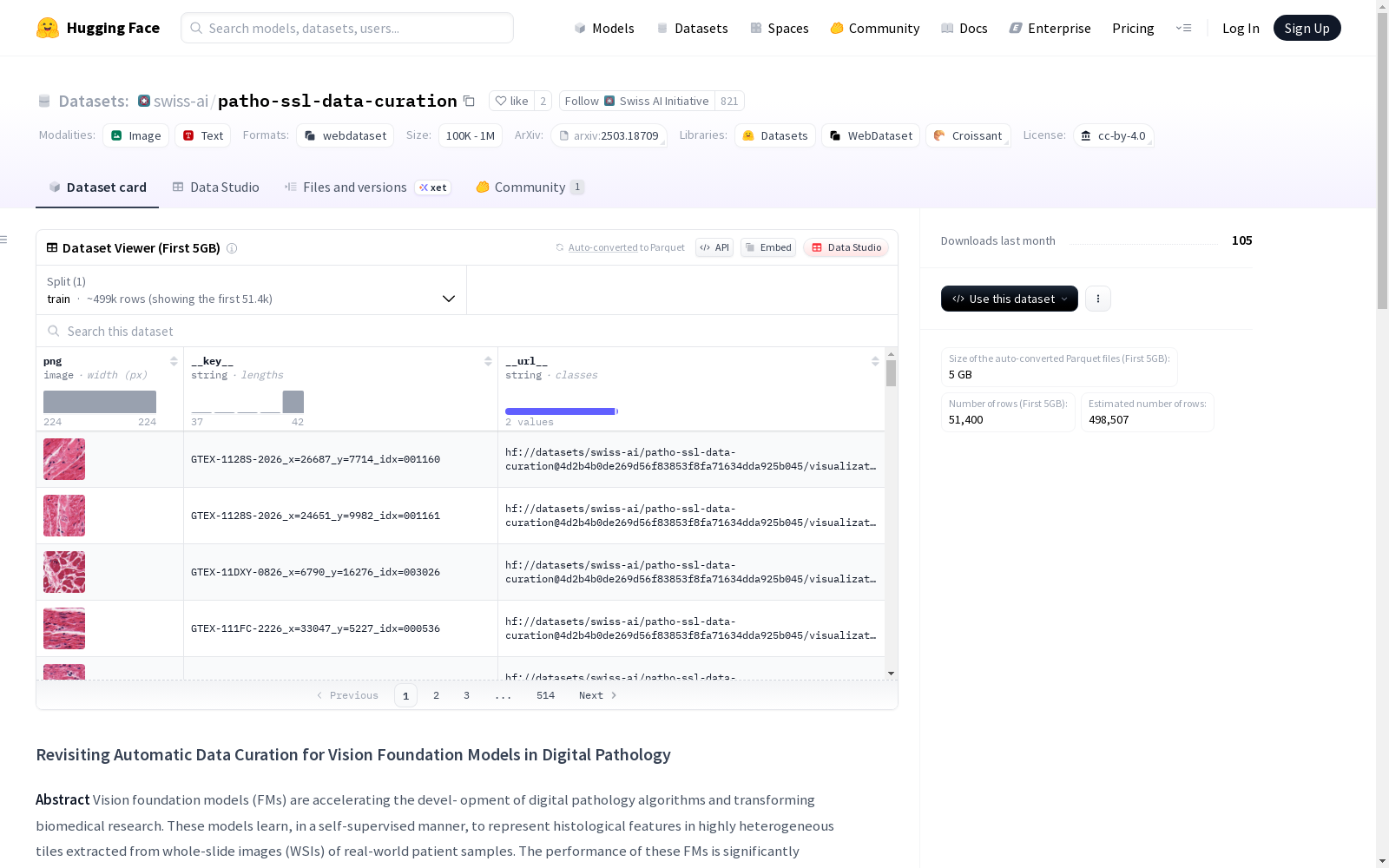
本研究提供了一个包含3500万个瓦片的聚类结果数据集,这些瓦片通过层次聚类树进行了聚类。数据集包括两个模式的聚类结果CSV文件,每个文件包含瓦片的唯一标识符、瓦片在玻片中的坐标以及每个级别的聚类标签。此外,数据集还提供了K-means聚类质心、UMAP坐标以及一个可视化工具,用于查看2百万个精选瓦片的子集和对应的元数据。
This study presents a clustering result dataset encompassing 35 million tiles, which were clustered using a hierarchical clustering tree. The dataset includes CSV files of clustering results under two modes, with each file containing the unique identifier of a tile, its coordinates on the glass sheet, and cluster labels at each hierarchical level. Additionally, the dataset provides K-means clustering centroids, UMAP coordinates, and a visualization tool for exploring a subset of 2 million selected tiles and their corresponding metadata.
创建时间:
2025-05-21
搜集汇总
数据集介绍
构建方式
在数字病理学领域,数据质量对视觉基础模型的性能具有决定性影响。该数据集通过无监督自动数据筛选方法,对来自TCGA和GTEx数据库的3.5亿个组织切片图块进行层级聚类分析。利用预训练的UNI模型提取图块嵌入特征后,采用分层聚类树算法将图块划分为四个层级结构,最终生成包含幻灯片标识、坐标信息及聚类标签的标准化数据表。
特点
该数据集的核心价值在于其多尺度聚类架构与大规模病理图像覆盖。通过四级聚类层级,能够精准捕捉组织学特征的微观差异,同时保持类间平衡性。数据集提供K-means聚类中心坐标,支持新图块的快速归类;配套的可视化工具包含200万图块的UMAP降维结果及50万代表性图片子集,为病理特征探索提供直观依据。
使用方法
研究人员可通过解析CSV文件中的聚类标签,实现病理图块的智能分类与采样。利用提供的聚类中心文件,可将新图块映射至现有特征空间。可视化组件需配合专用代码库使用,通过加载元数据文件与图包子集重构特征分布图谱。原始全幻灯片图像需从TCGA/GTEx平台获取,建议使用openslide工具进行图块提取以保持数据一致性。
背景与挑战
背景概述
数字病理学作为现代医学诊断的重要分支,其发展依赖于对全切片图像中组织学特征的精准解析。patho-ssl-data-curation数据集由瑞士人工智能实验室等机构于2025年联合构建,旨在通过自监督学习优化视觉基础模型在病理图像分析中的表征能力。该研究聚焦于从TCGA和GTEx数据库提取的3.5亿个图像块,通过层次聚类技术重构数据平衡策略,推动病理图像分析从依赖专家先验知识向自动化数据筛选转型,为癌症诊断和生物标志物发现提供了新的方法论支持。
当前挑战
数字病理领域面临组织切片异质性高、标注成本昂贵等核心难题,传统方法依赖WSI层级的专家知识,难以捕捉图像块级别的细微特征差异。数据集构建过程中需处理海量图像块的嵌入表示平衡问题,层次聚类算法在超大规模数据上面临计算复杂度挑战,同时需权衡数据规模与类别平衡对模型表征质量的影响。此外,病理图像中组织形态的多样性和病变区域的稀疏分布进一步增加了数据表征的难度。
常用场景
经典使用场景
在数字病理学领域,该数据集通过无监督的层次聚类方法对3.5亿个组织切片进行自动数据筛选,为视觉基础模型提供平衡且多样化的预训练数据。这一过程有效提升了模型在组织学特征表示学习中的性能,尤其在处理高度异质性的全切片图像时表现出色。数据集的应用使得研究人员能够从细粒度层面优化数据选择,从而增强模型对复杂病理结构的识别能力。
衍生相关工作
基于该数据集提出的层次聚类与均衡采样策略,衍生出多项针对病理视觉基础模型的优化研究,例如结合k-means聚类中心的嵌入空间映射方法,以及面向特定疾病的多尺度特征学习框架。这些工作进一步扩展了无监督数据筛选在病理图像分析中的应用边界,为后续研究提供了可复现的技术基准和数据集构建范式。
数据集最近研究
最新研究方向
在数字病理学领域,随着视觉基础模型的快速发展,数据自动管理成为提升模型性能的关键环节。当前研究聚焦于从全玻片图像中提取的3.5亿个组织切片的无监督层级聚类方法,通过嵌入空间均衡采样策略优化数据平衡性。这一方向突破了传统依赖专家知识的局限,将粒度分析延伸至切片级别,显著增强了模型对异构组织特征的表示能力。相关探索不仅推动了病理图像分析的自动化进程,还为临床下游任务提供了更稳健的算法基础,标志着数字病理学向数据驱动范式的重要转变。
以上内容由遇见数据集搜集并总结生成


