mikaberidze/belebele-ftp
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/mikaberidze/belebele-ftp
下载链接
链接失效反馈官方服务:
资源简介:
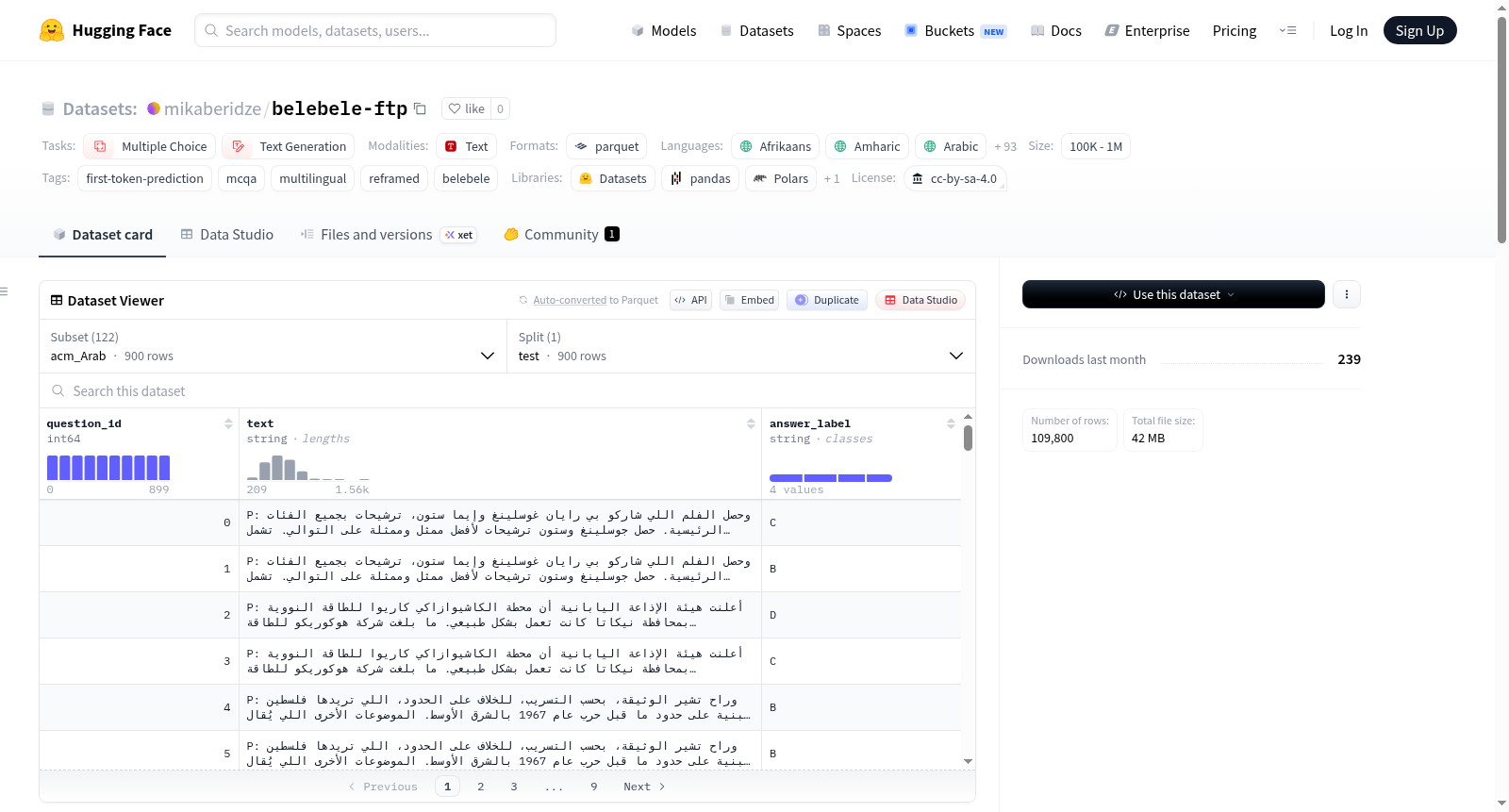
Belebele-FTP是一个基于facebook/belebele数据集重构的首词预测(FTP)任务数据集,支持122种语言变体。每个示例都是一个以Answer: 结尾的文本序列,模型需要预测一个标记(A/B/C/D)作为答案。数据集格式为多选问答(MCQA),包含问题ID、文本和答案标签。数据集仅包含测试集,没有训练集或验证集。
Belebele-FTP is a first-token-prediction (FTP) reframing of the facebook/belebele dataset, supporting 122 language variants. Each example is a single text sequence ending in Answer: so a model can predict the answer as one token (A/B/C/D). The dataset format is multiple-choice QA (MCQA), including question ID, text, and answer label. The dataset contains only the test set, with no training or validation sets.
提供机构:
mikaberidze
搜集汇总
数据集介绍
构建方式
Belebele-FTP数据集是对原始Belebele多语言阅读理解基准的重构,旨在适配首词预测(First-Token Prediction, FTP)范式。其构建过程将每条原始样本的篇章、问题及四个选项进行结构化拼接,形成以“P: ”引导的篇章文本、“Q: ”引导的问题内容,以及“A. ”至“D. ”排列的选项序列,并在末尾附加“Answer: ”标记,使得模型仅需预测一个令牌(A/B/C/D)即可输出答案。该转换通过Python脚本实现,保留了原始数据集的测试集划分,未新增额外标注。
特点
该数据集最显著的特点在于其极致的多语言覆盖范围,横跨122种语言变体,涵盖拉丁、阿拉伯、天城、西里尔等多种书写系统,为跨语言模型提供了宽广的评估维度。同时,其FTP重框架设计将多选问答任务简化为单令牌预测,大幅降低了输出结构的复杂性,特别适用于评估自回归语言模型在零样本或上下文学习场景下的推理能力。数据集仅包含测试集,体现了对原始Belebele基准的忠实继承。
使用方法
使用者可通过HuggingFace Datasets库按语言版本加载对应配置,例如加载英文变体时指定‘eng_Latn’。每个样本包含‘question_id’、‘text’和‘answer_label’三个字段,其中‘text’字段可直接作为模型输入。在推理时,模型需对“Answer: ”后的下一个令牌进行预测,并将输出概率最高的令牌(A/B/C/D)与‘answer_label’比对以计算准确率。该数据集适用于多语言问答能力的标杆测试,尤其适合评估大型语言模型在低资源语言上的表现。
背景与挑战
背景概述
Belebele-FTP数据集源自Meta AI研究团队于2024年发布的Belebele基准测试,由Lucas Bandarkar等人构建,旨在评估多语言机器阅读理解能力。该数据集对原始Belebele进行重构,将传统多项选择题转换为首词预测(First-Token Prediction)任务,覆盖122种语言变体,包括高资源与低资源语言。核心研究问题在于探索多语言模型在无需依赖复杂解码策略时,仅通过预测单标签(A/B/C/D)即完成阅读理解的能力,为跨语言自然语言理解提供了简洁而富有挑战性的评估范式。作为面向多语言、多脚本的标准化测试集,Belebele-FTP推动了多语言NLP模型的公平性研究,尤其对低资源语言的表现评价具有里程碑意义。
当前挑战
该数据集面临的核心挑战在于多语言覆盖的极不均衡性:尽管包含122种语言,但许多低资源语言(如班巴拉语、克丘亚语)在预训练语料中占比极小,导致模型处理这些语言时表现脆弱。构建过程中,原始Belebele仅提供测试集而无验证集,限制了模型训练过程中的调优能力;FTP重构虽简化了输出形式,却要求模型从单一文本序列末端精准预测答案标签,这对编码器与解码器间的对齐提出了更高要求。此外,不同语言的语法结构差异(如语序、形态丰富度)可能干扰首词预测的鲁棒性,现有模型对罕见脚本(如天城文、埃塞俄比亚音节文字)的泛化能力仍亟待提升。
常用场景
经典使用场景
Belebele-FTP是元人工智能团队对原始Belebele数据集进行重构的产物,其核心创新在于将传统的多项选择阅读理解任务转化为“首Token预测”格式。该数据集覆盖了122种语言变体,每一道题目均构造为衔接段落、问题与选项的连贯文本序列,并以“Answer:”作为结尾触发标记,迫使模型通过预测确切的单一标识符(A/B/C/D)来展现其对文本语义的深层把握。这种精巧的格式设计特别适用于评估预训练语言模型在零样本或少样本条件下的跨语言推理能力,成为衡量多语言模型阅读理解性能的理想试金石。
实际应用
在现实的工业应用场景中,Belebele-FTP所承载的理念与技术方案展现出非凡的价值。企业可以借助该数据集构建和优化支持多语种的知识问答系统、智能客服平台乃至教育辅助工具,为用户提供跨越语言障碍的精准信息检索服务。对于那些致力于全球化部署的大规模语言模型,利用Belebele-FTP进行微调或适配能够显著提升其在低资源语言上的响应质量,从而缩小数字鸿沟,让来自不同文化背景的人群都能享受到人工智能技术带来的便捷与普惠。
衍生相关工作
Belebele-FTP的诞生催生了一系列相关研究的蓬勃发展。在数据重构思路的启发下,后续学者提出了多种针对不同任务形态的“首Token预测”变体方案,构建了涵盖事实验证、情感分析等维度的跨语言评测套件。此外,该数据集也常被当作基线测试平台,用以对比诸如Chain-of-Thought推理、检索增强生成等高级方法论在多语言场景下的实际效能,为NLP共同体持续改进模型的认知边界提供了不可或缺的实证基础与迭代动力。
以上内容由遇见数据集搜集并总结生成


