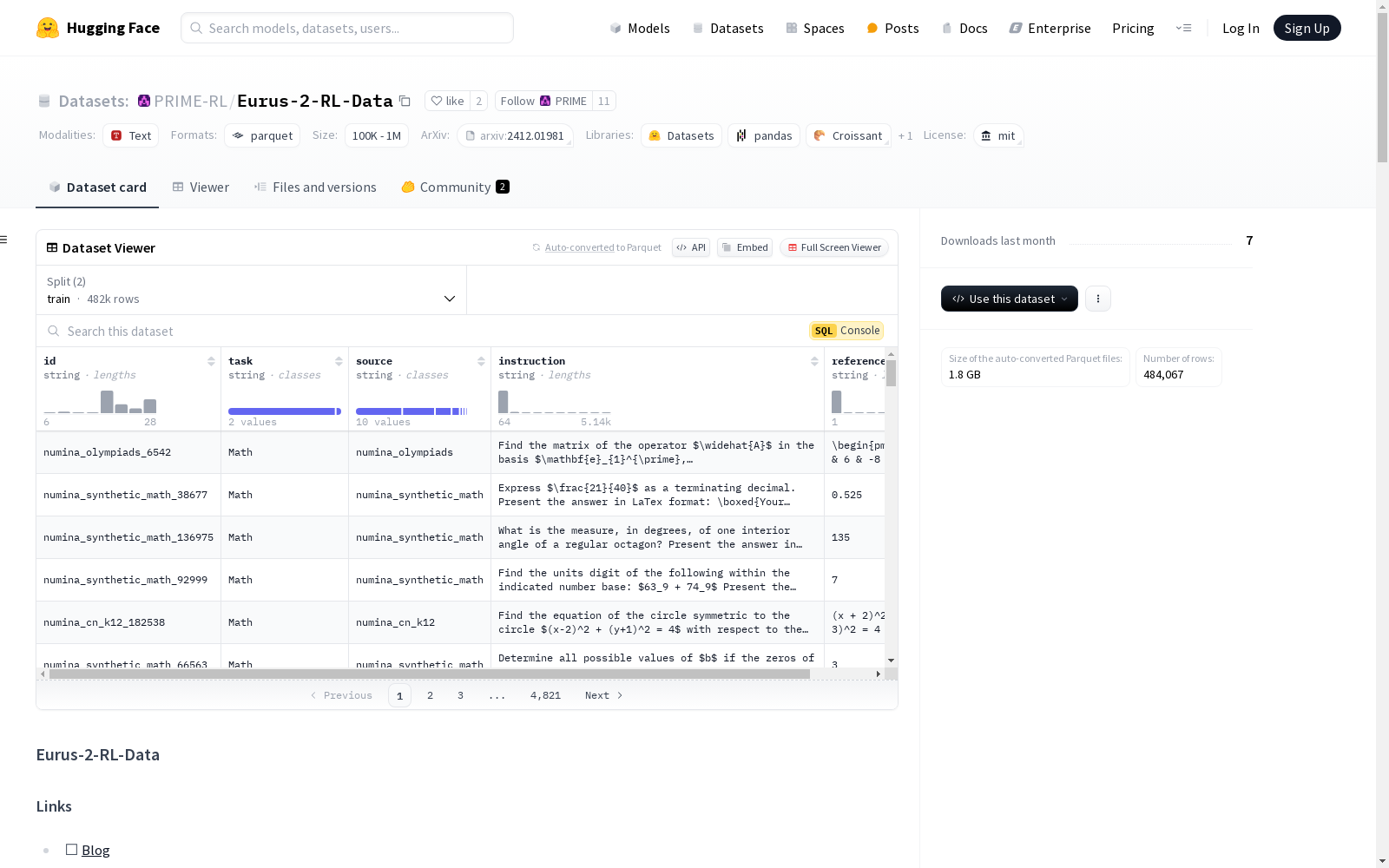
Eurus-2-RL-Data
收藏Eurus-2-RL-Data 数据集概述
数据集简介
Eurus-2-RL-Data 是一个高质量的强化学习训练数据集,包含数学和编程问题,并提供了结果验证器(数学问题的LaTeX答案和编程问题的测试用例)。
- 数学问题:数据来源于 NuminaMath-CoT,涵盖从中国高中数学到国际数学奥林匹克竞赛的题目。
- 编程问题:数据来源于 APPS、CodeContests、TACO 和 Codeforces,主要为编程竞赛级别的题目。
数据预处理
为了提高数据质量,数据集进行了详细的清洗和过滤。
- 数学问题:使用高级推理模型(如 Qwen-QwQ)过滤掉无法解决、不匹配或答案错误的问题,并将选择题转换为开放性问题。
- 编程问题:主要过滤掉重复的问题。
最终保留了 455k 个数学问题和 27k 个编程问题。
数据集结构
数据集包含训练集和验证集,具体结构如下:
python from datasets import load_dataset
ds = load_dataset("PRIME-RL/Eurus-2-RL-Data") print(ds)
DatasetDict({
train: Dataset({
features: [id, task, source, instruction, reference],
num_rows: 482019
})
validation: Dataset({
features: [id, task, source, instruction, reference],
num_rows: 2048
})
})
数据统计
| Train | Validation | |
|---|---|---|
| Math | 455261 | 1024 |
| Coding | 26758 | 1024 |
数据示例
数学问题
json { "id": "numina_amc_aime_1931", "task": "Math", "source": "numina_amc_aime", "instruction": "Given that $\frac{2}{7}$ of the knights are red, and $\frac{1}{6}$ of the knights are magical, and that the fraction of red knights who are magical is $2$ times the fraction of blue knights who are magical, find the fraction of red knights who are magical.
Present the answer in LaTex format: \boxed{Your answer}", "reference": "\frac{7}{27}" }
编程问题
json { "id": "codecontests_0", "task": "Coding", "source": "codecontests", "instruction": "You are given undirected weighted graph. Find the length of the shortest cycle which starts from the vertex 1 and passes throught all the edges at least once. Graph may contain multiply edges between a pair of vertices and loops (edges from the vertex to itself).
Input
The first line of the input contains two integers n and m (1 ≤ n ≤ 15, 0 ≤ m ≤ 2000), n is the amount of vertices, and m is the amount of edges. Following m lines contain edges as a triples x, y, w (1 ≤ x, y ≤ n, 1 ≤ w ≤ 10000), x, y are edge endpoints, and w is the edge length.
Output
Output minimal cycle length or -1 if it doesnt exists.
Examples
Input
3 3 1 2 1 2 3 1 3 1 1
Output
3
Input
3 2 1 2 3 2 3 4
Output
14
Write Python code to solve the problem. Present the code in python Your code
at the end.", "reference": "{"inputs": ["3 3\n1 2 1\n2 3 1\n3 1 1\n", "3 2\n1 2 3\n2 3 4\n", "2 10\n1 2 9\n1 2 9\n2 1 9\n1 2 8\n2 1 9\n1 2 9\n1 2 9\n1 2 11\n1 2 9\n1 2 9\n", "4 4\n1 3 1953\n3 2 2844\n1 3 2377\n3 2 2037\n", "2 1\n2 2 44\n", "4 8\n1 2 4824\n3 1 436\n2 2 3087\n2 4 2955\n2 4 2676\n4 3 2971\n3 4 3185\n3 1 3671\n", "15 14\n1 2 1\n2 3 1\n2 4 1\n3 5 1\n3 6 1\n4 7 1\n4 8 1\n5 9 1\n5 10 1\n6 11 1\n6 12 1\n7 13 1\n7 14 1\n8 15 1\n", "15 0\n", "3 1\n3 2 6145\n", "15 4\n1 5 5531\n9 15 3860\n8 4 6664\n13 3 4320\n", "7 3\n4 4 1\n7 7 1\n2 2 1\n", "2 8\n1 2 4618\n1 1 6418\n2 2 2815\n1 1 4077\n2 1 4239\n1 2 5359\n1 2 3971\n1 2 7842\n", "4 2\n1 2 1\n3 4 1\n", "6 2\n5 3 5039\n2 3 4246\n", "2 1\n2 2 5741\n", "4 2\n3 2 6816\n1 3 7161\n", "15 1\n7 5 7838\n", "6 4\n5 4 6847\n3 6 7391\n1 6 7279\n2 5 7250\n", "15 2\n5 13 9193\n14 5 9909\n", "5 2\n2 2 2515\n2 4 3120\n", "3 3\n1 2 1\n2 3 1\n3 2 1\n", "3 1\n3 2 6389\n", "10 3\n4 4 1\n7 7 1\n2 2 0\n", "6 2\n5 5 5039\n1 3 4246\n", "15 1\n9 9 7838\n", "6 4\n5 4 6847\n3 6 7391\n1 3 2446\n2 5 7250\n", "1 2\n1 1 1\n1 1 3\n", "6 0\n", "3 1\n3 3 9184\n", "10 3\n4 4 0\n7 7 1\n2 2 0\n", "6 2\n5 5 5039\n1 3 7812\n", "15 1\n3 9 7838\n", "4 4\n1 3 1953\n4 4 2844\n2 3 4041\n3 2 2037\n"], "outputs": ["3\n", "14\n", "91\n", "9211\n", "-1\n", "28629\n", "28\n", "0\n", "-1\n", "-1\n", "-1\n", "43310\n", "-1\n", "-1\n", "-1\n", "27954\n", "-1\n", "-1\n", "73199\n", "44\n", "3\n", "-1\n", "8\n", "0\n", "-1\n", "-1\n", "-1\n", "3059\n", "7042\n", "-1\n", "0\n", "22019\n", "69034\n", "6\n", "9683\n", "14464\n", "-1\n", "6222\n", "95162\n", "35262\n", "0\n", "-1\n", "90\n", "3669\n", "315043\n", "9\n", "41\n", "10875\n", "26917\n", "28\n", "-1\n", "46065\n", "4\n", "11482\n", "27874\n", "5\n", "2957\n", "7043\n", "69034\n", "9547\n", "12136\n", "0\n", "87\n", "307170\n", "35\n", "7\n", "14865\n", "27196\n", "44599\n", "7039\n", "8481\n", "11646\n", "80\n", "316201\n", "9\n", "15672\n", "26868\n", "7029\n", "10119\n", "85\n", "24495\n", "-1\n", "-1\n", "-1\n", "-1\n", "-1\n", "-1\n", "4\n", "-1\n", "-1\n", "-1\n", "-1\n", "-1\n", "4\n", "0\n", "-1\n", "-1\n", "-1\n", "-1\n", "-1\n"]}" }
引用
latex @misc{cui2024process, title={Process Reinforcement through Implicit Rewards}, author={Ganqu Cui and Lifan Yuan and Zefan Wang and Hanbin Wang and Wendi Li and Bingxiang He and Yuchen Fan and Tianyu Yu and Qixin Xu and Weize Chen and Jiarui Yuan and Huayu Chen and Kaiyan Zhang and Xingtai Lv and Shuo Wang and Yuan Yao and Hao Peng and Yu Cheng and Zhiyuan Liu and Maosong Sun and Bowen Zhou and Ning Ding}, year={2025} }
latex @article{yuan2024implicitprm, title={Free Process Rewards without Process Labels}, author={Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng}, journal={arXiv preprint arXiv:2412.01981}, year={2024} }