PolyTrace
收藏github2025-09-23 更新2025-10-03 收录
下载链接:
https://github.com/Zhou-jiecheng/PolyTrace
下载链接
链接失效反馈官方服务:
资源简介:
PolyTrace是一个用于LLM RLVR训练的工作负载数据集,包含3个大规模内部RL训练工作负载和4个开源RL训练工作负载,主要包含工具调用延迟和实际工作负载两种数据类型。数据集涵盖数学、编程、搜索、视频理解、工具使用和图像理解等多个任务领域,支持多轮任务工作负载,并提供数据匿名化和分布生成功能。
PolyTrace is a workload dataset designed for LLM RLVR training. It includes three large-scale internal RL training workloads and four open-source RL training workloads, featuring two main data types: tool call latency and actual workloads. The dataset covers multiple task domains such as mathematics, programming, search, video understanding, tool usage, and image understanding, supports multi-turn task workloads, and provides data anonymization and distribution generation functions.
创建时间:
2025-09-22
原始信息汇总
PolyTrace数据集概述
数据集简介
PolyTrace是一个用于大语言模型强化学习训练的数据集,主要包含两种数据类型:工具调用延迟数据和实际工作负载数据。
任务构成
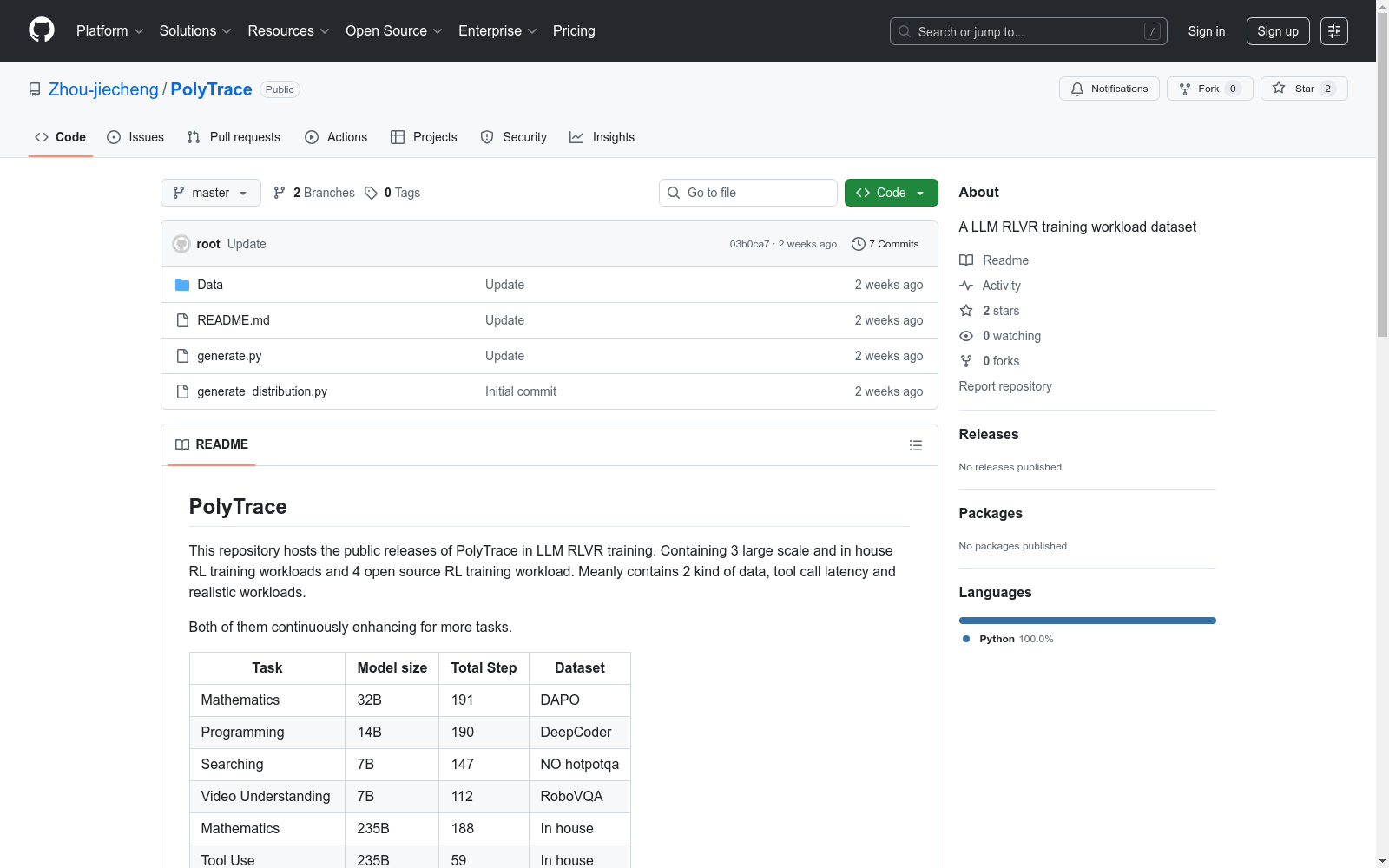
数据集包含7个训练任务,分为两大类:
开源RL训练工作负载(4个)
- Mathematics:32B模型,191个训练步骤,使用DAPO数据集
- Programming:14B模型,190个训练步骤,使用DeepCoder数据集
- Searching:7B模型,147个训练步骤,使用NO hotpotqa数据集
- Video Understanding:7B模型,112个训练步骤,使用RoboVQA数据集
内部RL训练工作负载(3个)
- Mathematics:235B模型,188个训练步骤,使用内部数据集
- Tool Use:235B模型,59个训练步骤,使用内部数据集
- Image Understanding:235B模型,46个训练步骤,使用内部数据集
数据结构
单轮任务格式
json { "0": { "input": [], "output": [] }, "1": { "input": [], "output": [] } }
多轮任务格式
json { "0": [ { "input": [...], "output": [...] }, { "input": [...], "output": [...] } ], "1": [ { "input": [...], "output": [...] }, { "input": [...], "output": [...] } ] }
数据特征
- 从训练轨迹中收集长度信息以实现数据匿名化
- 提供基于高斯混合分布的数据生成方法用于更严格的数据脱敏
- 在开源任务中,部分输入输出可能存在不一致,但不影响数据采样
使用工具
数据集提供生成脚本:
generate.py:生成Verl中Cosmos任务的输入数据generate_distribution.py:使用拟合分布生成工作负载数据
搜集汇总
数据集介绍
构建方式
在强化学习训练领域,PolyTrace数据集通过整合七种不同规模的任务轨迹构建而成,涵盖数学推理、程序生成及多模态理解等关键方向。其构建过程采用训练轨迹长度采集技术,对输入输出序列进行匿名化处理,既包含单轮任务的标准键值对结构,也支持多轮对话的嵌套列表形式。通过高斯混合分布拟合真实工作负载的统计特征,实现了数据生成与隐私保护的平衡。
特点
该数据集最显著的特征在于其多尺度任务覆盖能力,既包含32B参数模型的数学推理轨迹,也收录7B模型的视频理解数据。数据结构设计兼具灵活性与规范性,单任务采用扁平化键值存储,多轮对话则通过层次化列表保持时序关联。开源任务与内部任务的并行收录,既保障了基准任务的可比性,又扩展了专业场景的适用边界。
使用方法
使用该数据集时,可通过附带的生成脚本控制输出序列长度与终止条件,例如设置ignore_eos参数忽略终止符并指定最大生成长度。对于需要严格脱敏的场景,建议采用分布拟合采样方法,通过高斯混合模型提取工作负载统计参数后进行概率采样。数据读取接口支持直接加载JSON格式的轨迹文件,其多模态数据结构可适配不同训练框架的输入要求。
背景与挑战
背景概述
PolyTrace数据集作为强化学习验证与推理领域的重要资源,聚焦于大语言模型在复杂任务中的性能优化。该数据集由专业研究团队构建,整合了数学推理、程序生成、信息检索及多模态理解等核心任务,覆盖从7B至235B不同规模的模型训练轨迹。其结构化设计通过工具调用延迟与真实工作负载的双重维度,为智能体决策机制的研究提供了实证基础,显著推动了可复现强化学习范式的标准化进程。
当前挑战
该数据集致力于解决异构任务中强化学习智能体的泛化能力与效率平衡问题,尤其面临多模态任务对齐、长序列决策优化等核心难题。在构建过程中,数据匿名化要求催生了高斯混合分布拟合技术,但开源任务中存在的输入输出非对称性仍对数据采样一致性构成挑战。此外,跨规模模型的训练轨迹融合需要克服计算资源分配与评估指标统一化的双重压力。
常用场景
经典使用场景
在强化学习与大型语言模型协同优化的研究领域中,PolyTrace数据集凭借其多模态任务轨迹记录,成为评估模型推理效率的基准工具。该数据集通过整合数学推理、编程生成及视觉理解等多样化任务序列,为研究者提供了分析模型在复杂决策链中行为模式的典型场景,尤其在多轮交互式任务中展现其结构化数据的优势。
解决学术问题
PolyTrace通过系统化采集工具调用延迟与真实工作负载数据,有效解决了强化学习训练中奖励函数设计与环境交互建模的共性难题。其匿名化处理的多轮对话轨迹为研究长期依赖关系与策略泛化提供了数据基础,显著推进了面向现实场景的序列决策理论发展,并填补了跨领域任务迁移研究中高质量基准数据的空白。
衍生相关工作
基于PolyTrace的轨迹匿名化方法,衍生出诸如DAPO数学推理基准与RoboVQA视觉问答系统等经典工作。其多模态任务架构进一步启发了DeepCoder代码生成模型的迭代优化,而高斯混合分布采样技术则为后续研究如HotpotQA知识检索任务的数据增强提供了可复用的方法论范式。
以上内容由遇见数据集搜集并总结生成


