qlora-instruct-datasets
收藏Hugging Face2025-10-25 更新2025-10-26 收录
下载链接:
https://huggingface.co/datasets/SamarKamat/qlora-instruct-datasets
下载链接
链接失效反馈官方服务:
资源简介:
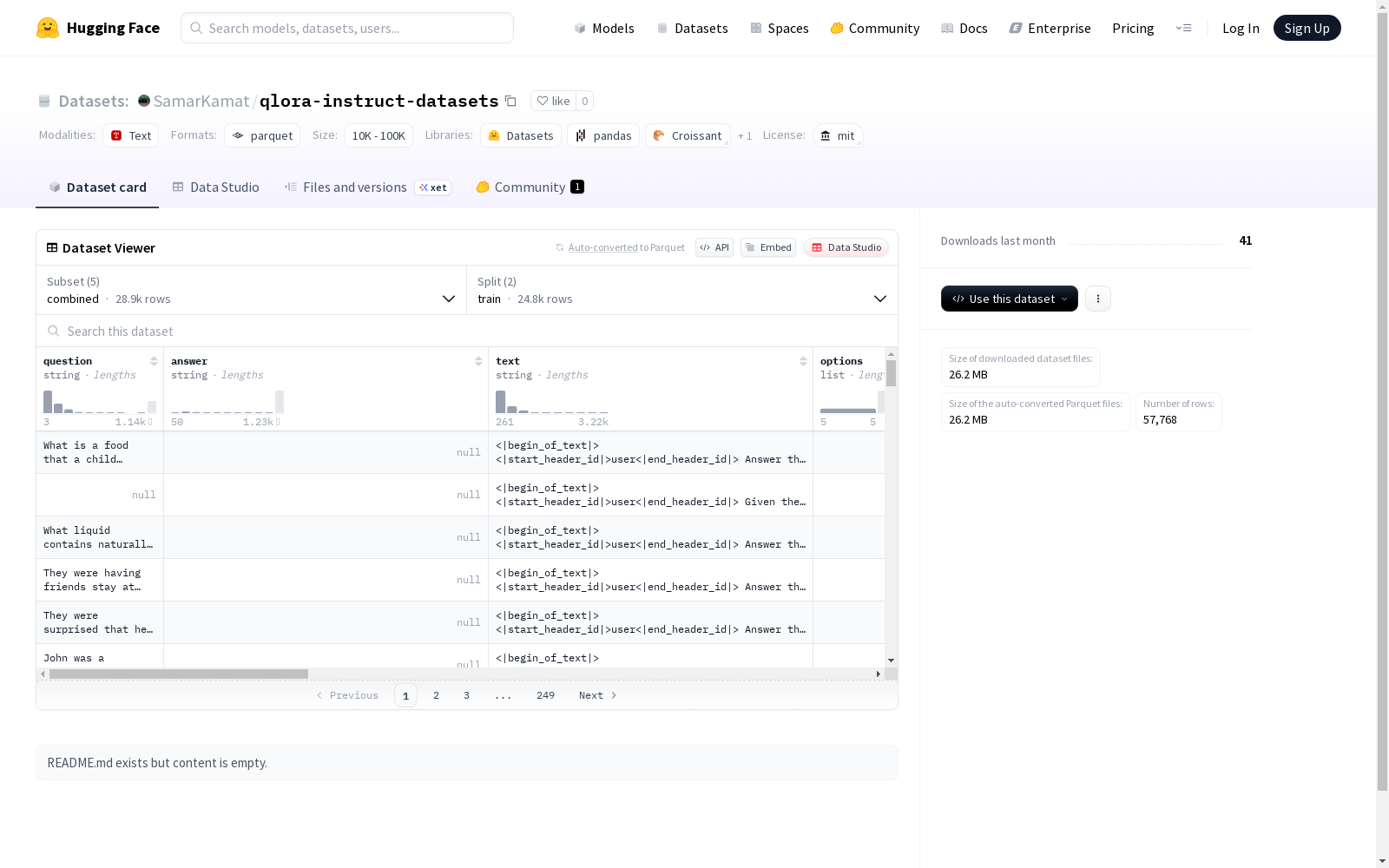
该数据集是一个自然语言处理数据集,包含了四个不同的配置,用于训练和测试模型。数据集中的字段包括问题、答案、前提、假设等,以及与之相关的文本和选项。每个配置都有训练集和测试集,类标签包括蕴含、中立和矛盾三种类型。
This dataset is a natural language processing (NLP) dataset containing four distinct configurations for model training and testing. Its fields include question, answer, premise, hypothesis, as well as associated texts and options. Each configuration is equipped with both a training set and a test set, and the class labels cover three categories: entailment, neutral, and contradiction.
创建时间:
2025-10-19
原始信息汇总
数据集概述
基本信息
- 许可证: MIT
- 数据集地址: https://huggingface.co/datasets/SamarKamat/qlora-instruct-datasets
配置结构
combined配置
- 特征字段:
- question (字符串)
- answer (字符串)
- text (字符串)
- options (字符串列表)
- rationale (字符串)
- correct (字符串)
- premise (字符串)
- hypothesis (字符串)
- label (分类标签: 0-蕴含, 1-中立, 2-矛盾)
- idx (整型)
- id (字符串)
- title (字符串)
- context (字符串)
- answers (结构体: text-字符串列表, answer_start-整型列表)
- question_concept (字符串)
- choices (结构体: label-字符串列表, text-字符串列表)
- answerKey (字符串)
- 数据划分:
- train: 24,842个样本,24,091,012字节
- test: 4,042个样本,3,990,272字节
- 下载大小: 13,170,854字节
- 数据集大小: 28,081,284字节
qual_test配置
- 特征字段:
- premise (字符串)
- hypothesis (字符串)
- label (分类标签: 0-蕴含, 1-中立, 2-矛盾)
- idx (整型)
- text (字符串)
- id (字符串)
- title (字符串)
- context (字符串)
- question (字符串)
- answers (结构体: text-字符串列表, answer_start-整型列表)
- question_concept (字符串)
- choices (结构体: label-字符串列表, text-字符串列表)
- answerKey (字符串)
- 数据划分:
- test: 2,937个样本,3,972,108字节
- 下载大小: 1,182,296字节
- 数据集大小: 3,972,108字节
qual_train配置
- 特征字段: 与qual_test相同
- 数据划分:
- train: 16,358个样本,14,565,505字节
- 下载大小: 6,304,672字节
- 数据集大小: 14,565,505字节
quant_test配置
- 特征字段:
- question (字符串)
- answer (字符串)
- text (字符串)
- options (字符串列表)
- rationale (字符串)
- correct (字符串)
- 数据划分:
- test: 1,105个样本,1,348,345字节
- 下载大小: 681,035字节
- 数据集大小: 1,348,345字节
quant_train配置
- 特征字段: 与quant_test相同
- 数据划分:
- train: 8,484个样本,9,359,641字节
- 下载大小: 4,867,629字节
- 数据集大小: 9,359,641字节
数据文件路径
- combined配置: combined/train-, combined/test-
- qual_test配置: qual_test/test-*
- qual_train配置: qual_train/train-*
- quant_test配置: quant_test/test-*
- quant_train配置: quant_train/train-*
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,qlora-instruct-datasets通过多源知识整合构建而成,涵盖综合配置、定性分析和定量评估三大模块。数据集采用结构化融合策略,将24842个训练样本和4042个测试样本系统整合,每个样本均包含问题、答案、文本及推理链条等核心要素。构建过程中特别注重语义逻辑的完整性,通过预设前提与假设的对应关系,建立蕴含、中立和矛盾三类标签体系,为语言理解任务提供扎实的数据基础。
特点
该数据集最显著的特征在于其多维度的语义标注体系,不仅包含传统问答对和选项集合,还创新性地引入理性分析字段和概念关联机制。数据结构的灵活性体现在支持多种任务格式,从简单的文本分类到复杂的推理判断均可覆盖。特别值得注意的是其分模块设计思路,定性训练集与定量测试集各自独立又相互补充,16358个定性样本与8484个定量样本共同构成层次分明的评估体系,为模型能力测评提供多角度验证。
使用方法
针对不同研究需求,使用者可通过五种配置方案灵活调用数据集资源。综合配置适用于通用指令微调场景,qual_train与qual_test专攻自然语言推理任务,quant_train和quant_test则聚焦数学推理能力评估。实际应用时建议根据模型发展阶段选择相应模块,初始训练阶段可优先采用combined配置获取全面特征,专项优化阶段则利用分模块数据进行针对性强化。数据加载支持标准HuggingFace接口,通过指定config_name参数即可实现不同粒度任务的快速切换。
背景与挑战
背景概述
在自然语言处理领域,指令微调数据集作为提升大语言模型泛化能力的关键资源,其构建工作受到广泛关注。qlora-instruct-datasets作为集成多任务学习范式的综合数据集,融合了自然语言推理、问答及文本蕴含等核心任务,通过结构化字段设计支持模型对复杂语义关系的理解。该数据集采用分模块配置策略,涵盖质量评估与量化分析双维度,为低秩自适应优化技术提供了标准化训练基准,显著推动了高效参数微调方法在资源受限场景下的应用进程。
当前挑战
该数据集致力于解决多模态指令理解中的语义泛化难题,其核心挑战在于统一不同任务类型的标注规范与逻辑冲突。构建过程中面临异构数据源的结构对齐困境,需协调自然语言推理的三元组标注与问答任务的跨度标注体系。同时,质量评估模块需维持文本蕴含标签的一致性,而量化模块需保证选项式问题的逻辑完备性,这种多维度标注融合对数据清洗与验证流程提出了极高要求。
常用场景
经典使用场景
在自然语言处理领域,qlora-instruct-datasets作为指令微调任务的重要资源,其多模态结构设计特别适用于大语言模型的监督微调过程。该数据集通过整合问答对、文本蕴含和多项选择等丰富格式,为模型提供了系统性的指令遵循能力训练。研究人员通常利用其结构化特征来优化模型对复杂指令的理解与执行,特别是在few-shot学习场景下展现出色性能。
解决学术问题
该数据集有效解决了指令微调领域数据稀缺与质量参差的核心难题。通过融合科学问答、文本推理和常识判断等多维度任务,为研究社区提供了标准化的评估基准。其精心设计的标签体系显著提升了模型在逻辑推理和知识应用方面的泛化能力,推动了参数高效微调方法的创新发展,特别是在QLoRA等低资源适配技术的研究中发挥关键作用。
衍生相关工作
基于该数据集衍生的经典研究包括参数高效微调范式的创新探索,特别是在QLoRA技术路线中作为核心训练数据支撑。多项研究利用其多层次标注结构开发了新型的指令压缩算法,同时在知识蒸馏领域催生了多个突破性工作。该数据集还促进了跨任务联合学习框架的发展,为构建通用型对话系统奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


