ZoomBench
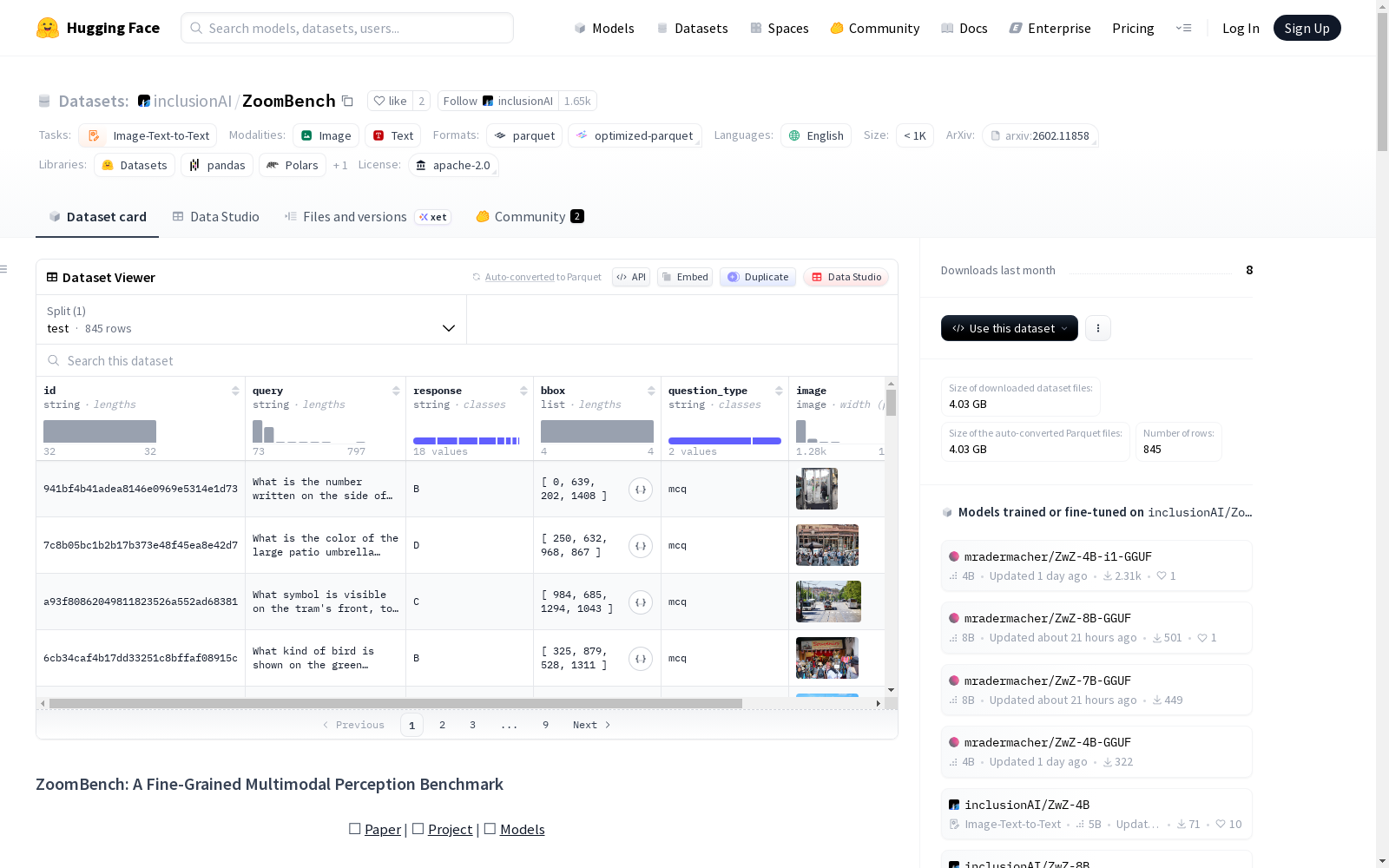
收藏ZoomBench 数据集概述
数据集简介
ZoomBench 是一个旨在评估多模态大语言模型(MLLMs)细粒度多模态感知能力的基准测试。它专门针对那些决定性视觉证据微小、细微或容易被全局上下文淹没的场景,这些场景要求模型仅从单张完整图像中实现“缩放级别”的感知。该数据集是“Zooming without Zooming”项目的一部分。
关键统计信息
- 总样本数:845
- 感知维度:6
- 问题格式:多项选择题 + 开放性问题
- 评估视图:完整图像 + 裁剪区域(双视图)
- 证据标注:自动(通过R2I方法)
- 构建方式:混合(Gemini-2.5-Pro生成 + 人工验证)
- 难度:57.5%(以 1 − Qwen2.5-VL-7B 模型的准确率衡量)
感知维度
数据集涵盖细粒度感知的6个主要类别:
- 细粒度计数:针对微小且密集堆积的物体。
- OCR:专注于文本和符号识别。
- 颜色属性:辨别物体局部的细微颜色变化。
- 结构属性:检查几何和形状相关属性,如物体结构和部件布局。
- 材质属性:识别材料构成和表面属性(如金属、木材、玻璃、织物)。
- 物体识别:区分特定的物体类型和种类,如旗帜、品牌、地标和知名人物。
评估协议
混合评分格式
- 多项选择题:适用于答案空间自然离散或难以严格归一化的情况。
- 开放性问题:带有标准目标答案,用于更自然和灵活的评估。
双视图协议
每个样本包含完整图像及其对应的关键区域裁剪图。这可以量化“缩放差距”,即从裁剪区域感知与从完整图像感知的性能差异。缩放差距大表明模型难以从全局上下文中提取细粒度细节,而差距小则表明模型具有鲁棒的细粒度感知能力。
注意力图可解释性
支持注意力图覆盖率评估,用于衡量模型的视觉注意力是否集中在与任务相关的图像区域上。这提供了一个可解释性视角:即使模型回答正确,若在目标区域上的注意力覆盖率低,也可能表明其依赖捷径而非真正的细粒度理解。
构建流程
- 从多样化的图像数据集中裁剪出微区域。
- 使用强大的MLLM(Gemini-2.5-Pro)基于裁剪区域生成问题和候选答案。
- 将问题映射回完整图像,形成具有挑战性的感知任务(无需任何空间标注,如边界框)。裁剪区域自动作为证据标注。
- 人工循环验证:人工标注者根据完整图像和裁剪区域检查模型生成的问答对的有效性、难度和正确性。
- 将问题聚类到6个细粒度感知类别中。
使用方式
加载数据集
python from datasets import load_dataset dataset = load_dataset("inclusionAI/ZoomBench")
评估
评估脚本位于项目主仓库中:
- 转换ZoomBench为评估格式:
python convert_benchmark.py - 运行基准评估:
bash run_baseline.sh - 注意力图覆盖率分析:
python eval_coverage.py
相关资源
- 模型:ZwZ-4B、ZwZ-7B、ZwZ-8B
- 训练数据:ZwZ-RL-VQA
- 项目仓库:https://github.com/inclusionAI/Zooming-without-Zooming
引用
bibtex @article{wei2026zooming, title={Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception}, author={Wei, Lai and He, Liangbo and Lan, Jun and Dong, Lingzhong and Cai, Yutong and Li, Siyuan and Zhu, Huijia and Wang, Weiqiang and Kong, Linghe and Wang, Yue and Zhang, Zhuosheng and Huang, Weiran}, journal={arXiv preprint arXiv:2602.11858}, year={2026} }
许可证
请参阅项目仓库了解许可证详情。ZoomBench 旨在用于研究和评估目的。
联系方式
- Lai Wei: waltonfuture@sjtu.edu.cn
- Liangbo He: langdao.hlb@antgroup.com
- Jun Lan: yelan.lj@antgroup.com
- Zhuosheng Zhang: zhangzs@sjtu.edu.cn
- Weiran Huang: weiran.huang@sjtu.edu.cn