NeuroSynth
收藏arXiv2024-07-17 更新2024-07-22 收录
下载链接:
https://huggingface.co/spaces/rongguangw/neuro-synth
下载链接
链接失效反馈官方服务:
资源简介:
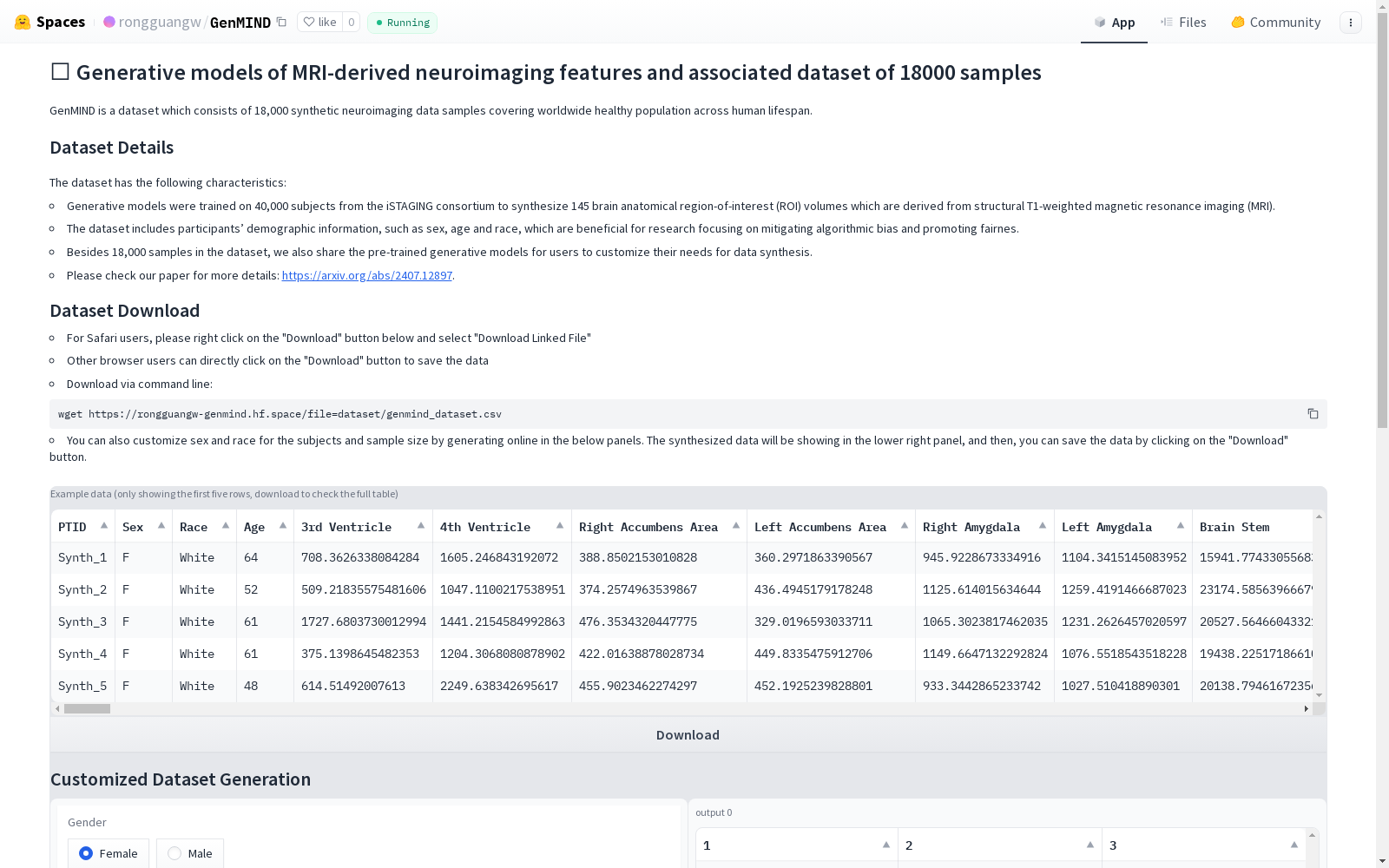
NeuroSynth是由宾夕法尼亚大学的AI和数据科学集成诊断中心创建的一个大型神经影像数据集,包含18,000条合成样本,覆盖22至90岁成年人的脑部结构数据。该数据集通过生成模型从iSTAGING联盟的真实脑部MRI扫描数据中训练得到,考虑了年龄、性别和种族等协变量。创建过程中使用了核密度估计(KDE)模型,确保合成数据与真实数据的分布一致。NeuroSynth主要应用于神经影像学领域的机器学习研究,特别是在疾病分类和脑龄预测等任务中,显著提高了模型的准确性和泛化能力。
NeuroSynth is a large-scale neuroimaging dataset developed by the Center for AI and Integrative Diagnostics in Data Science at the University of Pennsylvania, which contains 18,000 synthetic samples of brain structural data from adults aged 22 to 90 years. Trained on real brain MRI scans from the iSTAGING Consortium using generative models, this dataset incorporates covariates including age, gender, and ethnicity. A kernel density estimation (KDE) model was employed during its development to ensure that the synthetic data matches the distribution of real-world data. NeuroSynth is primarily applied to machine learning research in the field of neuroimaging, particularly for tasks such as disease classification and brain age prediction, where it significantly improves model accuracy and generalization performance.
提供机构:
宾夕法尼亚大学
创建时间:
2024-07-17
搜集汇总
数据集介绍
构建方式
NeuroSynth数据集的构建方法采用了核密度估计(KDE)模型,这是一种非参数的密度估计方法,能够捕捉数据分布的复杂特性。具体而言,研究人员从iSTAGING联盟收集了超过40,000个MRI扫描数据,并从中提取了145个解剖学脑ROI体积。这些数据被用于训练KDE模型,以便生成符合实际数据分布的合成数据。为了确保模型能够准确反映不同人口统计学特征(如年龄、性别和种族)的分布,研究人员采用了分层方法,将数据按照这些特征进行分类,并为每个分类训练一个独立的模型。在训练过程中,研究人员对每个类别中的特征向量进行了标准化处理,并使用了高斯核来构建每个数据点的局部高斯密度表面。通过组合这些局部密度,模型能够平滑地估计年龄和ROI体积的联合概率密度函数。此外,为了确定最佳的带宽参数,研究人员进行了网格搜索,最终选择了能够在细节和泛化之间取得平衡的带宽。
使用方法
NeuroSynth数据集的使用方法涉及多个步骤。首先,用户可以从提供的网址下载数据集和KDE模型。然后,用户可以使用这些模型来生成符合其研究需求的合成数据。例如,研究人员可以利用NeuroSynth来比较他们的患者人群与数据集中的标准数据,或者训练脑年龄预测模型。此外,用户还可以使用合成数据进行数据增强,以提高疾病分类模型的性能。为了确保数据集的质量和准确性,用户在将NeuroSynth数据与自己的数据进行整合时,应该注意数据之间的潜在差异,并采取适当的归一化或校准方法。在使用合成数据进行研究时,用户还应该考虑模型的局限性,例如由于核平滑导致的噪声,并在解释结果时保持谨慎。总之,NeuroSynth数据集为神经影像学研究提供了一个宝贵的资源,可以帮助研究人员克服数据共享的限制,并促进机器学习技术在医学领域的应用。
背景与挑战
背景概述
NeuroSynth 数据集由美国宾夕法尼亚大学佩雷尔曼医学院人工智能和数据科学中心(AI2D)的研究团队创建,旨在解决医学领域数据共享受限的问题。该数据集基于 iSTAGING 联盟的 40,000 多份 MRI 扫描数据,包含了不同年龄、性别和种族的正常脑部区域体积测量值。NeuroSynth 数据集提供了 18,000 个成人生命跨度(22-90 岁)的合成脑部影像样本,这些样本能够帮助研究人员在疾病诊断、预后和精准医疗等领域构建和优化机器学习模型。NeuroSynth 数据集的发布对于推动神经影像学领域机器学习研究具有重要意义,它为研究人员提供了大量且多样化的数据资源,有助于克服数据隐私和共享限制的问题。
当前挑战
NeuroSynth 数据集面临的挑战主要包括:1) 领域问题挑战:如何利用合成数据提高疾病分类模型的准确性和泛化能力;2) 构建过程挑战:如何在保证数据隐私的前提下,生成与真实数据分布一致的合成数据,同时减少噪声和过拟合问题。此外,NeuroSynth 数据集还面临着如何与现有数据进行有效整合和比较的挑战,以及如何根据特定研究需求进行数据定制和扩展的问题。
常用场景
经典使用场景
NeuroSynth数据集主要用于生成规范性的大脑区域体积数据,这些数据可用于疾病分类、预后和精准医疗等领域的机器学习模型构建和优化。通过使用NeuroSynth,研究人员可以生成18,000个合成样本,涵盖了成年人的整个生命周期(年龄范围:22至90岁),以及不同种族和性别的数据。这些数据对于下游机器学习模型的准确性有显著的提升。
解决学术问题
NeuroSynth数据集解决了医学数据通常包含敏感患者信息,受到医院严格的隐私法规限制的问题。为了克服这些限制,NeuroSynth提供了大量合成的脑MRI数据,这些数据可以公开共享和分发,而不必担心数据隐私问题。此外,NeuroSynth生成的规范性数据显著提高了下游机器学习模型在疾病分类等任务上的准确性。
实际应用
NeuroSynth数据集在实际应用中具有广泛的应用场景,包括但不限于:1) 局部疾病人群比较,研究人员可以利用NeuroSynth来比较自己的患者人群与NeuroSynth的规范性数据集;2) 脑龄预测模型,NeuroSynth可以作为训练脑龄预测模型的资源;3) 丰富分类研究中的健康对照组,数据集增强了健康对照组,用于区分分析和疾病分型研究;4) 合成数据生成器模型,研究人员可以使用NeuroSynth生成的模型来定制自己的数据合成。
数据集最近研究
最新研究方向
NeuroSynth数据集的最新研究方向主要集中在利用生成模型来生成具有广泛代表性的神经影像学数据。该数据集基于iSTAGING联盟的大量真实脑部MRI扫描,通过非参数核密度估计(KDE)模型训练,产生了18,000个涵盖成年人生理年龄范围(22-90岁)的合成样本。这些样本不仅包括了脑部ROI体积,还包含了人口统计学信息,如性别、年龄和种族。NeuroSynth的生成模型能够生成无限的数据,为疾病诊断、预后和精准医疗等领域提供了大量数据支持。此外,NeuroSynth还允许用户根据研究需求定制数据合成,从而提高了数据集的适用性和灵活性。未来,NeuroSynth计划进一步扩展数据集,包括遗传风险因素、认知评分和生物标志物等协变量,以支持更广泛的研究和应用。
相关研究论文
- 1NeuroSynth: MRI-Derived Neuroanatomical Generative Models and Associated Dataset of 18,000 Samples宾夕法尼亚大学 · 2024年
以上内容由遇见数据集搜集并总结生成


