swahili-child-assessment
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/yvan-pimi/swahili-child-assessment
下载链接
链接失效反馈官方服务:
资源简介:
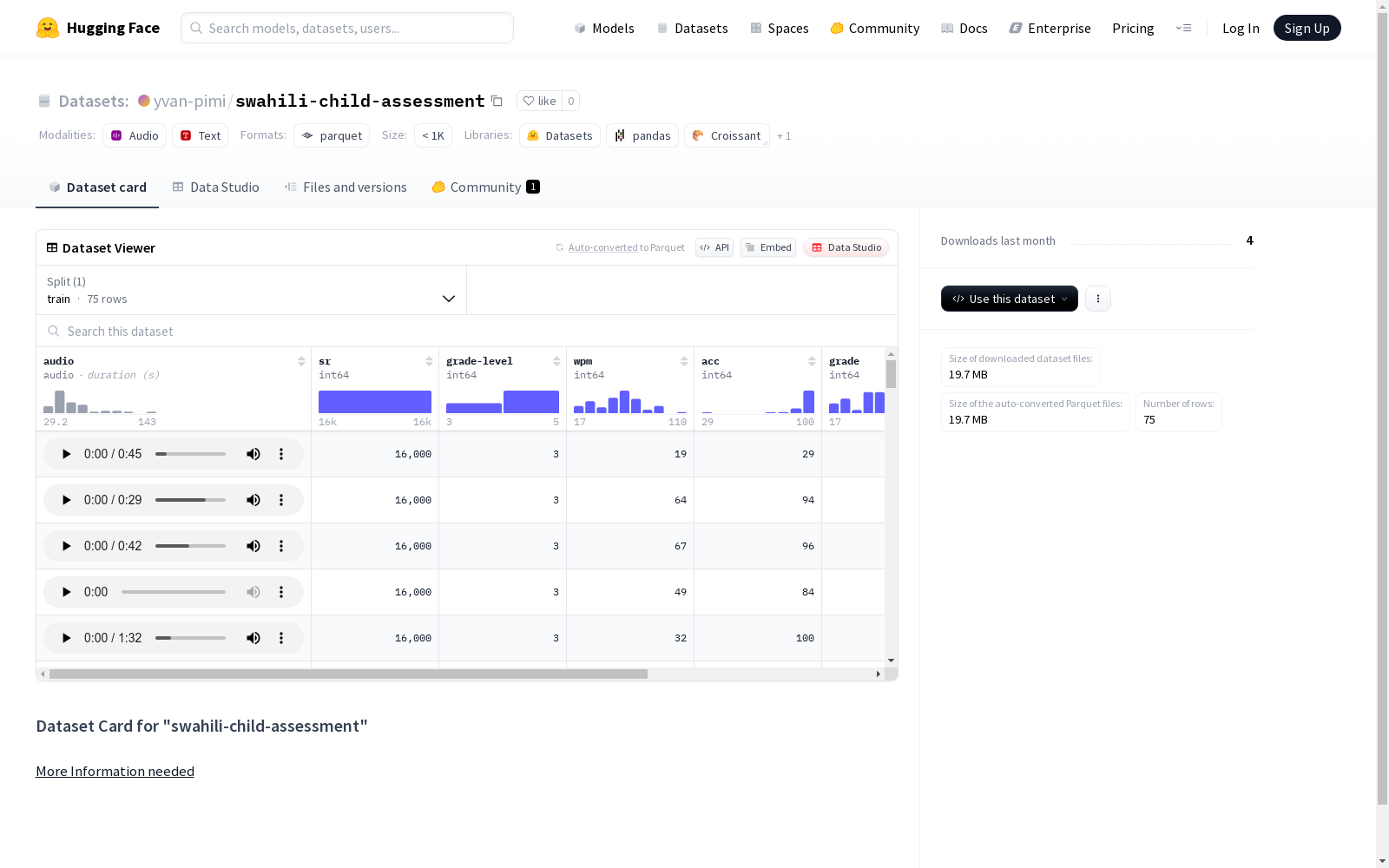
Swahili儿童评估数据集包含音频样本和与之相关的评估信息,如学生的年级水平、每分钟单词数、准确率、年级、错误数和句子内容。该数据集被拆分为训练集,其中包含75个示例,总大小为25860353字节。
创建时间:
2025-06-10
搜集汇总
数据集介绍
构建方式
在儿童语言发展研究领域,斯瓦希里语儿童评估数据集的构建采用了系统化采集方法,通过记录肯尼亚地区学龄儿童的朗读音频,同步收集朗读流利度、准确度和错误类型等多维指标。音频数据以16kHz采样率保存,并标注了年级水平和句子文本,确保了数据的完整性和可追溯性。
特点
该数据集涵盖75条高质量音频样本,每条样本均包含朗读速度(wpm)、准确率(acc)及错误计数等量化特征,同时关联学童的年级元数据。其独特价值在于提供了非洲本土语言斯瓦希里语的儿童语言发展实证数据,填补了该语言领域评估资源的空白。
使用方法
研究者可通过加载音频特征与标注字段,训练语音识别或语言能力评估模型,尤其适用于跨年级朗读能力对比研究。数据以标准音频格式存储,支持直接提取梅尔频谱或声学特征,兼容常见语音处理框架如TorchAudio或Librosa。
背景与挑战
背景概述
斯瓦希里语儿童评估数据集诞生于非洲教育科技发展的关键时期,由专注于语言学习技术的研究团队构建,旨在通过计算语言学方法评估儿童斯瓦希里语阅读能力。该数据集聚焦于基础教育阶段语言技能量化分析,通过采集学龄儿童的朗读音频及流利度、准确度等多维指标,为教育诊断与语言技术开发提供数据支撑。其创新性在于填补了低资源语言教育评估数据的空白,对促进教育公平与跨语言语音研究具有显著意义。
当前挑战
该数据集核心挑战在于解决低资源语言环境下儿童语言能力自动化评估的难题,需克服方言变异、年龄相关发音不稳定性等语言学障碍。在构建过程中,研究人员面临田野数据采集的实操困难,包括偏远地区录音设备标准化、儿童参与者伦理合规性管理,以及专家标注成本高昂等问题。音频数据与多维度标注的对齐技术实现,亦是该数据集构建过程中的关键挑战。
常用场景
经典使用场景
在非洲语言教育技术领域,斯瓦希里语儿童评估数据集为语音识别与教育评估研究提供了关键资源。该数据集通过记录儿童朗读音频及其流利度指标,典型应用于构建自动阅读评估系统,研究者可分析朗读准确率、语速等特征,进而评估儿童的语言掌握程度。
解决学术问题
该数据集有效解决了低资源语言教育评估中标准化数据缺失的学术难题。通过提供带有详细标注的斯瓦希里语儿童语音样本,支持教育语音识别、阅读能力量化建模等研究,填补了非洲语言教育技术领域的空白,为跨语言教育公平性研究提供了数据基础。
衍生相关工作
基于该数据集衍生的经典工作包括低资源语言语音识别模型优化研究,如端到端的斯瓦希里语朗读评分系统。此外,它促进了多模态教育数据分析框架的发展,部分研究将其与认知科学结合,探索儿童二语习得规律,推动了教育技术与计算语言学的交叉创新。
以上内容由遇见数据集搜集并总结生成


