china-ai-law-challenge/cail2018
收藏Hugging Face2024-01-16 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/china-ai-law-challenge/cail2018
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- found
language_creators:
- found
language:
- zh
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
source_datasets:
- original
task_categories:
- other
task_ids: []
paperswithcode_id: chinese-ai-and-law-cail-2018
pretty_name: CAIL 2018
tags:
- judgement-prediction
dataset_info:
features:
- name: fact
dtype: string
- name: relevant_articles
sequence: int32
- name: accusation
sequence: string
- name: punish_of_money
dtype: float32
- name: criminals
sequence: string
- name: death_penalty
dtype: bool
- name: imprisonment
dtype: float32
- name: life_imprisonment
dtype: bool
splits:
- name: exercise_contest_train
num_bytes: 220112348
num_examples: 154592
- name: exercise_contest_valid
num_bytes: 21702109
num_examples: 17131
- name: exercise_contest_test
num_bytes: 41057538
num_examples: 32508
- name: first_stage_train
num_bytes: 1779653382
num_examples: 1710856
- name: first_stage_test
num_bytes: 244334666
num_examples: 217016
- name: final_test
num_bytes: 44194611
num_examples: 35922
download_size: 1167828091
dataset_size: 2351054654
configs:
- config_name: default
data_files:
- split: exercise_contest_train
path: data/exercise_contest_train-*
- split: exercise_contest_valid
path: data/exercise_contest_valid-*
- split: exercise_contest_test
path: data/exercise_contest_test-*
- split: first_stage_train
path: data/first_stage_train-*
- split: first_stage_test
path: data/first_stage_test-*
- split: final_test
path: data/final_test-*
---
---
# Dataset Card for CAIL 2018
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Github](https://github.com/thunlp/CAIL/blob/master/README_en.md)
- **Repository:** [Github](https://github.com/thunlp/CAIL)
- **Paper:** [Arxiv](https://arxiv.org/abs/1807.02478)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@JetRunner](https://github.com/JetRunner) for adding this dataset.
annotations_creators:
- found(公开获取)
language_creators:
- found(公开获取)
language:
- 中文(zh)
license:
- unknown(未知)
multilinguality:
- monolingual(单语言)
size_categories:
- 100万 < 样本数 < 1000万(1M<n<10M)
source_datasets:
- original(原创)
task_categories:
- other(其他)
task_ids: []
paperswithcode_id: chinese-ai-and-law-cail-2018
pretty_name: CAIL 2018
tags:
- judgement-prediction(判决预测)
dataset_info:
features:
- name: fact(案件事实)
dtype: string
- name: relevant_articles(相关法条)
sequence: int32
- name: accusation(罪名)
sequence: string
- name: punish_of_money(罚金金额)
dtype: float32
- name: criminals(被告人)
sequence: string
- name: death_penalty(死刑)
dtype: bool
- name: imprisonment(有期徒刑刑期)
dtype: float32
- name: life_imprisonment(无期徒刑)
dtype: bool
splits:
- name: exercise_contest_train(练习赛训练集)
num_bytes: 220112348
num_examples: 154592
- name: exercise_contest_valid(练习赛验证集)
num_bytes: 21702109
num_examples: 17131
- name: exercise_contest_test(练习赛测试集)
num_bytes: 41057538
num_examples: 32508
- name: first_stage_train(第一阶段训练集)
num_bytes: 1779653382
num_examples: 1710856
- name: first_stage_test(第一阶段测试集)
num_bytes: 244334666
num_examples: 217016
- name: final_test(最终测试集)
num_bytes: 44194611
num_examples: 35922
download_size: 1167828091
dataset_size: 2351054654
configs:
- config_name: default
data_files:
- split: exercise_contest_train
path: data/exercise_contest_train-*
- split: exercise_contest_valid
path: data/exercise_contest_valid-*
- split: exercise_contest_test
path: data/exercise_contest_test-*
- split: first_stage_train
path: data/first_stage_train-*
- split: first_stage_test
path: data/first_stage_test-*
- split: final_test
path: data/final_test-*
---
---
# CAIL 2018 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建缘由](#curation-rationale)
- [源数据](#source-data)
- [注释](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [授权信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献声明](#contributions)
## 数据集描述
- **主页**:[GitHub](https://github.com/thunlp/CAIL/blob/master/README_en.md)
- **代码仓库**:[GitHub](https://github.com/thunlp/CAIL)
- **相关论文**:[ArXiv](https://arxiv.org/abs/1807.02478)
- **排行榜**:
- **联系人**:
### 数据集摘要
[More Information Needed]
### 支持任务与排行榜
[More Information Needed]
### 语言
[More Information Needed]
## 数据集结构
### 数据实例
[More Information Needed]
### 数据字段
[More Information Needed]
### 数据划分
[More Information Needed]
## 数据集构建
### 构建缘由
[More Information Needed]
### 源数据
#### 初始数据收集与标准化
[More Information Needed]
#### 源语言生产者是谁?
[More Information Needed]
### 注释
#### 注释流程
[More Information Needed]
#### 注释者是谁?
[More Information Needed]
### 个人与敏感信息
[More Information Needed]
## 数据集使用注意事项
### 数据集的社会影响
[More Information Needed]
### 偏差讨论
[More Information Needed]
### 其他已知局限
[More Information Needed]
## 附加信息
### 数据集维护者
[More Information Needed]
### 授权信息
[More Information Needed]
### 引用信息
[More Information Needed]
### 贡献声明
感谢 [@JetRunner](https://github.com/JetRunner) 为本数据集的收录提供贡献。
提供机构:
china-ai-law-challenge
原始信息汇总
数据集卡片 for CAIL 2018
数据集描述
数据集摘要
- 语言: 中文
- 许可: 未知
- 多语言性: 单语种
- 大小类别: 1M<n<10M
- 源数据集: 原始数据
- 任务类别: 其他
- 论文ID: chinese-ai-and-law-cail-2018
- 标签: judgement-prediction
- 数据集名称: CAIL 2018
数据集结构
数据字段
- fact: 字符串
- relevant_articles: 整数序列
- accusation: 字符串序列
- punish_of_money: 浮点数
- criminals: 字符串序列
- death_penalty: 布尔值
- imprisonment: 浮点数
- life_imprisonment: 布尔值
数据分割
- exercise_contest_train: 220112348 字节, 154592 样本
- exercise_contest_valid: 21702109 字节, 17131 样本
- exercise_contest_test: 41057538 字节, 32508 样本
- first_stage_train: 1779653382 字节, 1710856 样本
- first_stage_test: 244334666 字节, 217016 样本
- final_test: 44194611 字节, 35922 样本
数据集大小
- 下载大小: 1167828091 字节
- 数据集大小: 2351054654 字节
配置
- 配置名称: default
- 数据文件:
- exercise_contest_train: data/exercise_contest_train-*
- exercise_contest_valid: data/exercise_contest_valid-*
- exercise_contest_test: data/exercise_contest_test-*
- first_stage_train: data/first_stage_train-*
- first_stage_test: data/first_stage_test-*
- final_test: data/final_test-*
搜集汇总
数据集介绍
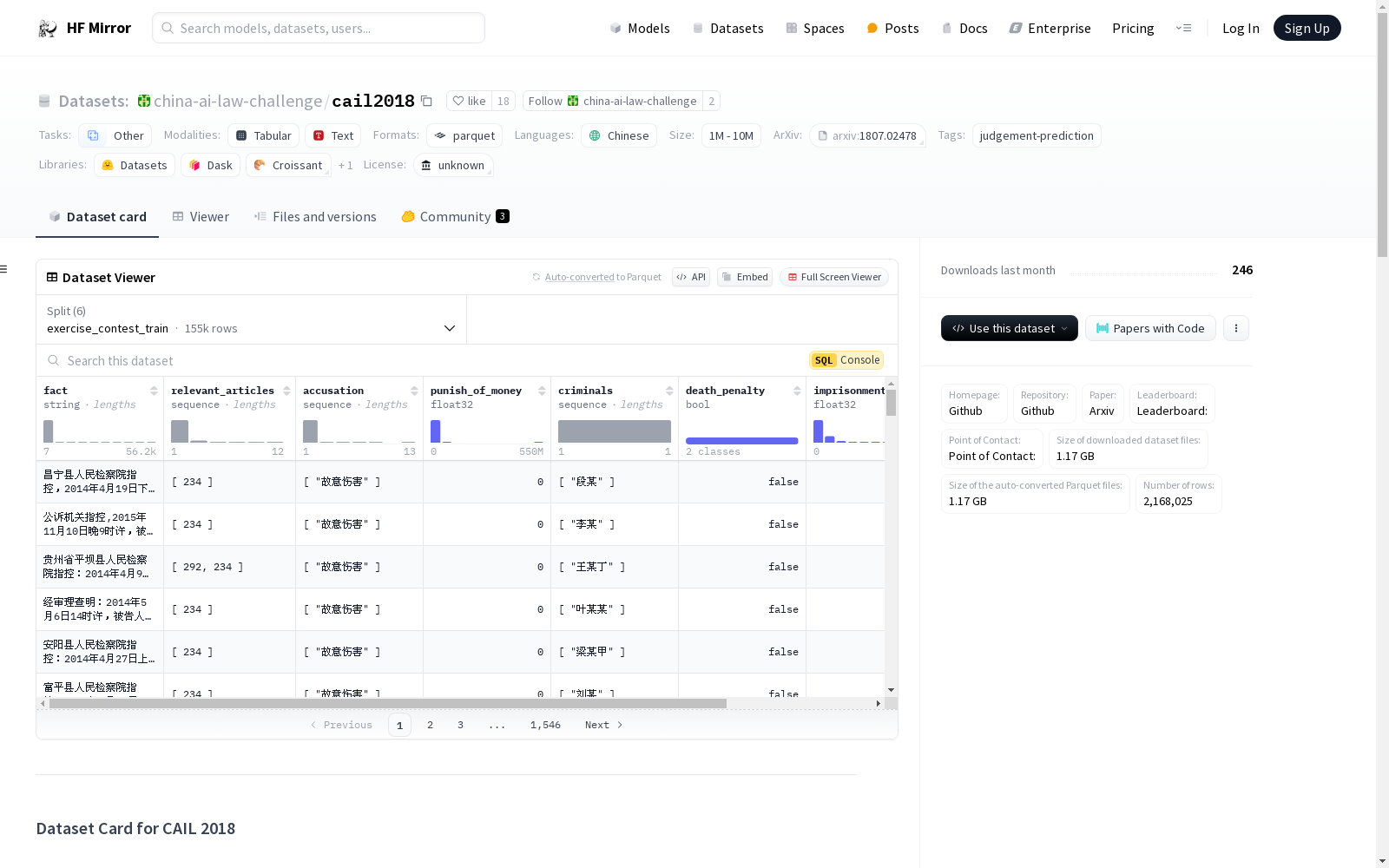
构建方式
在构建CAIL 2018数据集时,研究者们从原始法律文书数据库中提取了大量刑事案件数据,涵盖了多种法律条文和判决结果。数据集的构建过程包括对原始文本的清洗、标准化处理以及特征提取,确保了数据的准确性和一致性。通过这种方式,数据集不仅包含了案件的事实描述,还详细记录了相关的法律条文、指控、刑罚等信息,为法律领域的研究提供了丰富的资源。
特点
CAIL 2018数据集的显著特点在于其全面性和多样性。该数据集不仅包含了大量的刑事案件记录,还详细区分了不同类型的法律条文和判决结果,如罚款、监禁、死刑等。此外,数据集还提供了多种特征,如犯罪事实描述、相关法律条文、指控类型等,这些特征为法律判决预测和法律文本分析提供了坚实的基础。
使用方法
使用CAIL 2018数据集时,研究者可以根据具体的研究目标选择不同的数据子集,如训练集、验证集和测试集。数据集的结构清晰,每个实例都包含了案件的事实描述、相关法律条文、指控类型等关键信息。研究者可以通过加载数据集的配置文件,快速访问所需的数据,并利用这些数据进行法律判决预测、法律文本分类等任务的研究。
背景与挑战
背景概述
CAIL 2018数据集,由清华大学自然语言处理与社会人文计算实验室(THUNLP)创建,旨在推动法律领域的智能化研究。该数据集的核心研究问题涉及法律判决预测,通过提供大量法律案件的事实描述、相关法条、指控类型、刑罚等信息,帮助研究人员开发和评估法律智能系统。CAIL 2018的发布,不仅为法律科技领域提供了丰富的资源,还促进了法律判决预测模型的研究与应用,对提升司法效率和公正性具有重要意义。
当前挑战
CAIL 2018数据集在构建过程中面临多重挑战。首先,法律文本的复杂性和多样性使得数据标注和处理异常困难。其次,法律判决预测任务的准确性要求极高,因为任何错误都可能对司法公正产生重大影响。此外,数据集中包含的敏感个人信息需要严格保护,以避免隐私泄露。最后,法律领域的不断变化和更新也对数据集的时效性和适应性提出了挑战,要求持续更新和维护以保持其有效性。
常用场景
经典使用场景
在法律领域,CAIL 2018数据集的经典使用场景主要集中在判决预测任务上。该数据集通过提供详细的案件事实描述、相关法律条款、指控类型以及判决结果等信息,为研究者构建和训练判决预测模型提供了丰富的资源。通过分析这些数据,研究者可以开发出能够自动预测案件判决结果的算法,从而辅助法官进行案件审理,提高司法效率。
实际应用
在实际应用中,CAIL 2018数据集被广泛用于开发智能法律辅助系统。这些系统通过分析案件事实和相关法律条款,能够自动生成初步的判决建议,从而减轻法官的工作负担,提高司法效率。此外,该数据集还可用于培训法律专业人员,帮助他们更好地理解和应用法律知识,提升专业素养。
衍生相关工作
基于CAIL 2018数据集,研究者们开展了一系列相关工作,包括判决预测模型的优化、法律文本的自动摘要生成以及法律知识图谱的构建等。这些工作不仅深化了对法律数据的理解和应用,还推动了法律人工智能技术的发展。例如,一些研究通过引入深度学习技术,显著提升了判决预测的准确性,为法律领域的智能化应用提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


