x_dataset_7480
收藏Hugging Face2025-02-10 更新2025-02-11 收录
下载链接:
https://huggingface.co/datasets/LadyMia/x_dataset_7480
下载链接
链接失效反馈官方服务:
资源简介:
Bittensor Subnet 13 X(Twitter)数据集是Bittensor Subnet 13去中心化网络的一部分,包含来自X(前Twitter)的实时推文数据流,支持多种自然语言处理任务,如情感分析、趋势检测、内容分析和用户行为建模。数据集以英文为主,但也包含多语言内容。数据持续更新,用户需自行根据时间戳创建数据划分。所有用户名和URL均经过编码处理以保护隐私。
创建时间:
2025-01-27
搜集汇总
数据集介绍
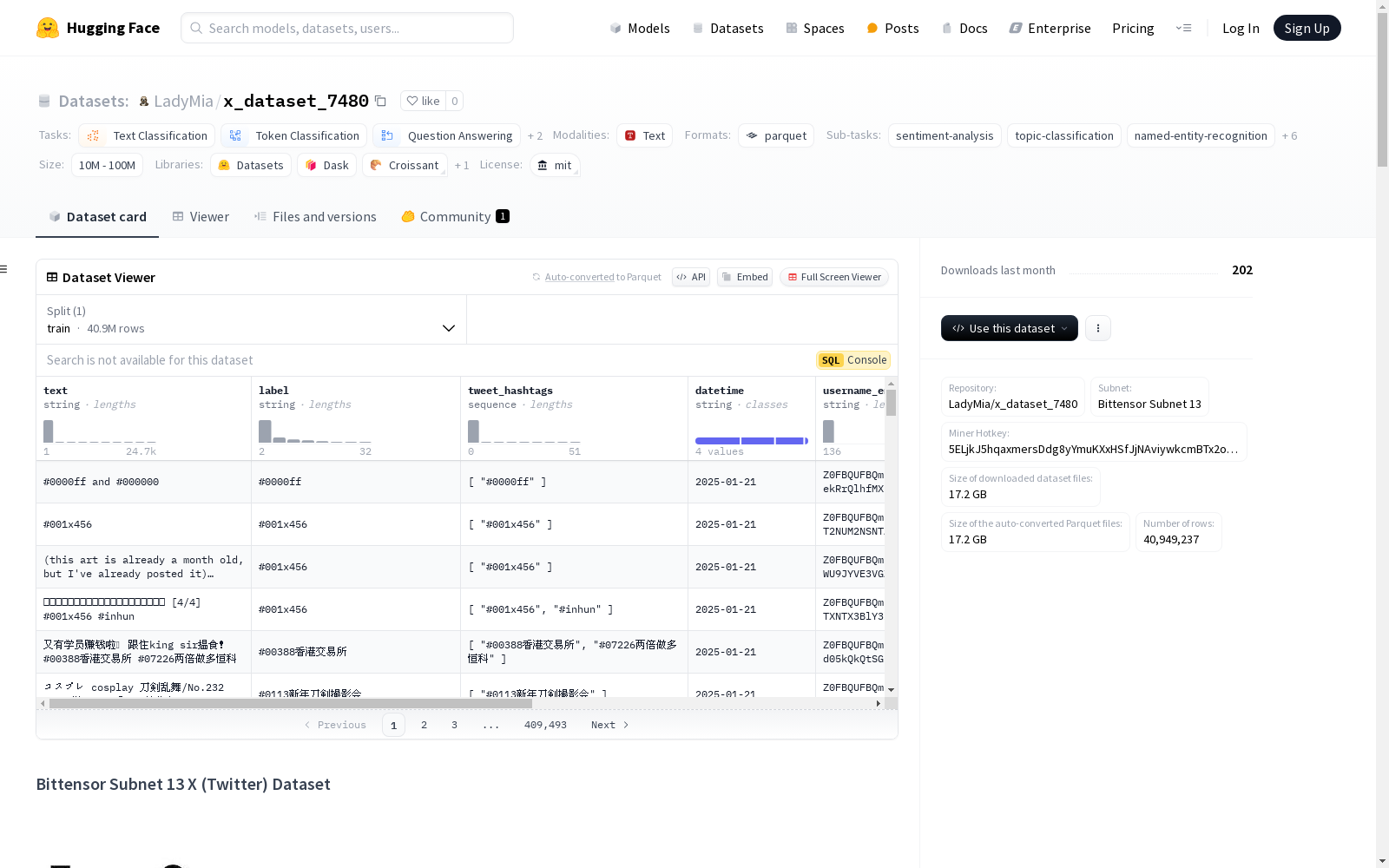
构建方式
x_dataset_7480数据集是Bittensor Subnet 13去中心化网络的一部分,包含了来自X(前Twitter)的预处理数据。该数据集通过网络矿工持续更新,为各种分析和机器学习任务提供实时的推文流。数据收集严格遵循平台的服务条款和API使用指南,确保了数据的合法性和时效性。
使用方法
在使用x_dataset_7480数据集时,用户应自行创建数据划分,基于时间戳来满足特定的研究需求。该数据集适用于多种机器学习任务,用户可以将其导入到机器学习框架中,进行模型训练和评估。在使用数据集时,应注意潜在的社会影响和偏见,同时考虑到数据质量可能因去中心化收集和预处理而存在差异。
背景与挑战
背景概述
x_dataset_7480数据集,作为Bittensor Subnet 13分布式网络的一部分,收录了来自X(原Twitter)平台的预处理数据。该数据集由网络矿工持续更新,为研究人员和机器学习任务提供实时推文流。该数据集的创建旨在探索社交媒体动态,并支持情感分析、趋势检测、内容分析和用户行为建模等多种任务。该数据集以英文为主,但由于去中心化的创建方式,也可能包含多语言内容。自2025年起,该数据集便开始收集数据,由LadyMia维护,并在学术和商业研究中产生了广泛的影响。
当前挑战
在数据集构建和使用过程中,研究人员面临诸多挑战。首先,数据质量因去中心化收集和预处理方式而可能存在波动。其次,数据中可能包含社交媒体平台常见的噪声、垃圾邮件或无关内容。此外,实时收集方法可能导致时间偏差,数据集仅限于公开推文,不包括私人账户或直接消息。在使用数据时,还需注意潜在的社交媒体数据偏见和隐私保护问题。
常用场景
经典使用场景
在社会科学与计算传播学领域,x_dataset_7480数据集作为Bittensor Subnet 13网络中的一部分,其经典使用场景主要聚焦于Twitter平台的内容分析与情感挖掘。研究者得以通过该数据集深入探索社交媒体中的舆论动态,进行情绪分析、话题分类以及命名实体识别等任务,从而绘制出网络舆论的实时地图。
解决学术问题
该数据集解决了学术研究中对于实时社交媒体数据的需求,特别是在文本分类、问题回答与总结等任务中表现出色。它帮助学者们克服了传统数据收集的障碍,使得对大规模社交媒体文本的快速分析与解读成为可能,进而推动了社交网络分析领域的研究进展。
实际应用
在实际应用层面,x_dataset_7480数据集为市场分析、品牌监测以及危机管理等领域提供了强有力的数据支持。企业和组织可以利用此数据集监测公众情绪,及时调整市场策略或应对公关事件,增强决策的科学性和时效性。
数据集最近研究
最新研究方向
在自然语言处理领域,x_dataset_7480数据集作为源自Twitter的实时社交媒体数据,其研究价值日益凸显。近期研究主要聚焦于情感分析、话题分类、命名实体识别等任务,旨在深入挖掘社交媒体中的用户情感态度、内容主题以及关键信息。该数据集的多语言特性使得跨语言信息处理研究成为可能,为理解不同文化背景下的社交媒体动态提供了宝贵资源。此外,研究者也在探索如何利用该数据集进行趋势检测、内容分析以及用户行为建模,以期为社交媒体的智能分析与应用提供新的视角和方法。
以上内容由遇见数据集搜集并总结生成


