MedFrameQA
收藏arXiv2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/SuhaoYu1020/MedFrameQA
下载链接
链接失效反馈官方服务:
资源简介:
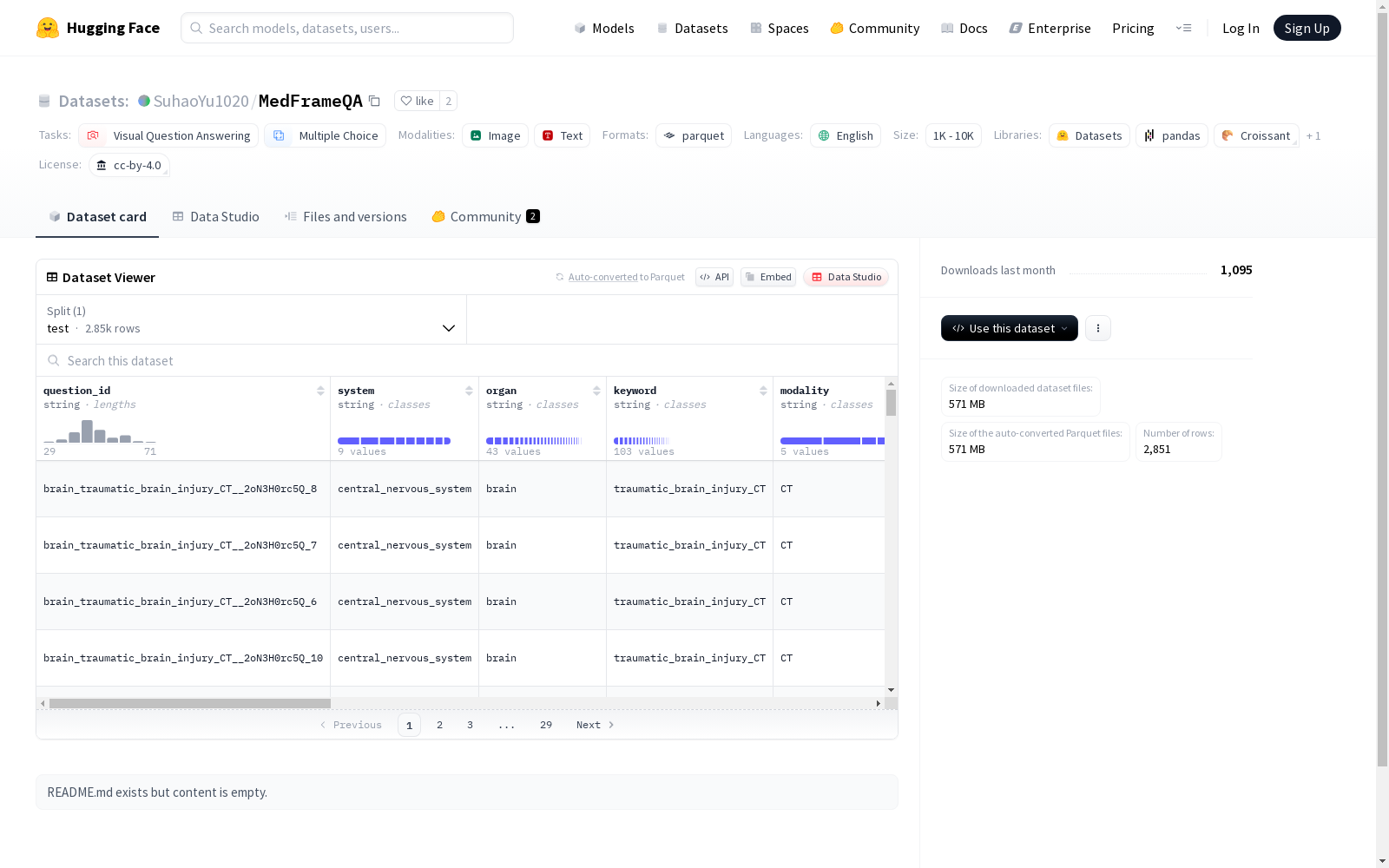
MedFrameQA是一个多图像医疗VQA基准数据集,旨在模拟临床推理流程。数据集包含从3,420个医学视频中提取的9,237个高质量帧,形成了2,851个VQA对,涵盖了九个人体系统和43个器官。每个问题都配有两到五张图像,要求模型进行复杂且全面的推理。数据集的创建过程包括自动提取视频中时间上连贯的帧,以及多阶段的过滤策略来保证数据的质量、难度和医学相关性。该数据集主要用于评估多模态大型语言模型在医学图像领域的推理能力,旨在解决当前模型在实际临床诊断中推理能力不足的问题。
MedFrameQA is a multi-image medical VQA benchmark dataset designed to simulate clinical reasoning workflows. It comprises 9,237 high-quality frames extracted from 3,420 medical videos, forming 2,851 VQA pairs covering nine human body systems and 43 organs. Each question is paired with 2 to 5 images, requiring models to perform complex and comprehensive reasoning. The dataset construction process includes automatically extracting temporally coherent frames from videos, as well as implementing multi-stage filtering strategies to ensure the data's quality, difficulty, and medical relevance. This dataset is primarily utilized to evaluate the reasoning capabilities of multimodal large language models (LLMs) in the medical imaging domain, aiming to address the problem of insufficient reasoning abilities of current models in real clinical diagnostic scenarios.
提供机构:
宾夕法尼亚大学、伊利诺伊大学香槟分校、加州大学圣克鲁斯分校
创建时间:
2025-05-23
原始信息汇总
MedFrameQA 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 视觉问答、多项选择
- 语言: 英语
数据集结构
- 配置名称: default
- 特征:
- question_id (string)
- system (string)
- organ (string)
- keyword (string)
- modality (string)
- video_id (string)
- question (string)
- options (sequence of strings)
- correct_answer (string)
- image_url (sequence of strings)
- reasoning_chain (string)
- image_1 (image)
- image_2 (image)
- image_3 (image)
- image_4 (image)
- image_5 (image)
数据划分
- 测试集: 2851 个样本
数据文件
- 路径:
- data/MedFrameQA_full_with_images_part1.parquet
- data/MedFrameQA_full_with_images_part2.parquet
- data/MedFrameQA_full_with_images_part3.parquet
- data/MedFrameQA_full_with_images_part4.parquet
- data/MedFrameQA_full_with_images_part5.parquet
- data/MedFrameQA_full_with_images_part6.parquet
搜集汇总
数据集介绍
构建方式
MedFrameQA数据集的构建采用了高度自动化的流程,从医学教育视频中提取关键帧并生成多图像视觉问答对。研究团队首先通过114种组合搜索查询从YouTube收集了3,420个医学视频,涵盖9个人体系统和43个器官。使用FFmpeg提取关键帧后,通过GPT-4o进行四阶段严格筛选,确保图像质量、医学相关性、信息丰富性和隐私保护。音频解说通过Whisper转录并与对应帧时间对齐,再由GPT-4o进行临床术语校正。相邻的帧-字幕对被合并为多帧片段以保持临床叙事的连贯性,最后通过GPT-4o生成需要跨图像推理的多选题。数据集经过两阶段过滤(模型自动筛选和人工审核)确保质量,最终形成2,851个高质量VQA对。
使用方法
使用MedFrameQA进行模型评估时,建议采用多阶段验证策略。基准测试包含2,851个闭卷式单选题,每个问题需结合2-5张相关医学图像作答。评估时可采用标准提示模板,要求模型逐步推理后输出最终选项。对于专有模型(如GPT-4o、Gemini-2.5-Flash)可通过官方API进行2,851次请求;开源模型(如QvQ-72B-Preview)可通过阿里云API进行评估。分析结果时需注意模型在9大人体系统和4种主要影像模态(CT、MRI、超声、X光)上的表现差异。数据集特别适合评估模型的三项核心能力:跨图像证据整合、临床推理链构建以及医学概念的空间关系理解。为充分发挥基准价值,建议同时分析模型在2-5张图像问题上的准确率波动情况。
背景与挑战
背景概述
MedFrameQA是由宾夕法尼亚大学、伊利诺伊大学厄巴纳-香槟分校和加州大学圣克鲁兹分校的研究团队于2025年推出的首个专注于多图像医学视觉问答(VQA)的基准数据集。该数据集旨在模拟临床医生通过对比系列医学影像进行诊断的实际工作流程,突破了传统医学VQA仅关注单幅图像分析的局限。数据集包含2,851个VQA对,覆盖9大人体系统和43个器官,每个问题均配有2-5张时序连贯的医学影像。通过自动化流水线从3,420个医学教育视频中提取9,237个高质量关键帧,并采用GPT-4o辅助的生成与过滤机制,确保了问题的临床相关性和推理复杂性。
当前挑战
MedFrameQA针对医学多模态推理提出双重挑战:在领域层面,现有模型在跨影像整合临床证据时表现欠佳,平均准确率不足50%,暴露出忽略关键征象、错误聚合证据和错误传递等系统性缺陷;在构建层面,需解决视频帧的时序连贯性保持、跨模态医学概念对齐,以及生成符合临床逻辑的多图像问题三大难题。特别地,数据构建需平衡自动化规模扩展与医学准确性,通过多阶段过滤策略消除隐私内容并确保问题难度,这对标注质量和领域知识深度提出了极高要求。
常用场景
经典使用场景
MedFrameQA数据集专为评估多图像医学视觉问答(VQA)中的临床推理能力而设计。其经典使用场景包括模拟临床医生通过对比一系列医学影像(如CT、MRI、X光等)进行诊断的过程。例如,研究者可利用该数据集测试模型在分析连续影像序列(如随时间变化的骨折愈合过程或多角度脑部扫描)时的跨图像推理能力,要求模型整合不同视角或时间点的视觉线索以回答复杂临床问题。
解决学术问题
该数据集解决了医学AI领域的关键学术问题:现有单图像VQA基准无法反映真实临床实践中多图像综合分析的需求。通过提供2-5张时序或逻辑关联的影像及配套问答对,MedFrameQA填补了评估模型在解剖定位、病理演变追踪和跨模态证据整合等高级临床推理任务上的空白。其构建方法(基于视频关键帧自动化生成问答对)也为大规模高质量医学多模态数据集的建设提供了范式。
实际应用
在实际医疗场景中,MedFrameQA可助力开发辅助诊断系统,例如:1)放射科工作流优化,通过自动比对患者多次检查的影像序列识别细微变化;2)教学培训系统构建,为医学生提供基于真实病例的多图像推理练习;3)远程会诊支持,帮助基层医生整合多源影像证据。数据集涵盖9大人体系统和43个器官的跨模态数据,能有效提升AI系统在复杂临床环境中的适用性。
数据集最近研究
最新研究方向
在医学视觉问答(VQA)领域,MedFrameQA数据集的推出标志着多图像临床推理评估的重要突破。该数据集通过从医学教育视频中提取时间连贯的帧序列,构建了包含2,851个多图像VQA对的基准测试,覆盖9大人体系统和43个器官。前沿研究聚焦于多模态大语言模型(MLLMs)在跨图像合成推理中的表现,实验显示当前模型准确率普遍低于50%,主要存在忽略关键帧证据、跨图像误聚合及错误链式传播等缺陷。该研究揭示了医学AI在真实临床工作流中的能力差距,为开发具有深度多图像分析能力的诊断系统提供了关键评估框架。
相关研究论文
- 1MedFrameQA: A Multi-Image Medical VQA Benchmark for Clinical Reasoning宾夕法尼亚大学、伊利诺伊大学香槟分校、加州大学圣克鲁斯分校 · 2025年
以上内容由遇见数据集搜集并总结生成


