GitTables
收藏arXiv2023-04-12 更新2024-06-21 收录
下载链接:
https://gittables.github.io
下载链接
链接失效反馈官方服务:
资源简介:
GitTables是由阿姆斯特丹大学的研究团队创建的一个大规模关系型表格数据集,包含从GitHub上提取的100万张表格。该数据集旨在通过提供与传统数据库表格相似的资源,支持深度学习模型在数据准备和搜索等任务中的应用。GitTables不仅在结构、内容和主题覆盖上与现有数据集有显著差异,还通过DBpedia和Schema.org为表格列添加了语义类型、层次关系和描述,以增强数据集的实用性和研究价值。该数据集的应用领域广泛,包括语义类型检测模型训练、模式完成方法和表格到知识图谱匹配的基准测试,为数据管理和分析提供了强大的资源支持。
GitTables is a large-scale relational tabular dataset created by a research team at the University of Amsterdam, containing 1 million tables extracted from GitHub. This dataset aims to support the application of deep learning models in tasks such as data preparation and search by providing resources similar to traditional database tables. GitTables differs significantly from existing datasets in terms of structure, content, and topic coverage; additionally, it adds semantic types, hierarchical relationships, and descriptions for table columns via DBpedia and Schema.org, enhancing the dataset's practicality and research value. This dataset has a wide range of application scenarios, including semantic type detection model training, schema completion methods, and benchmark testing for table-to-knowledge graph matching, providing powerful resource support for data management and analysis.
提供机构:
阿姆斯特丹大学
创建时间:
2021-06-14
搜集汇总
数据集介绍
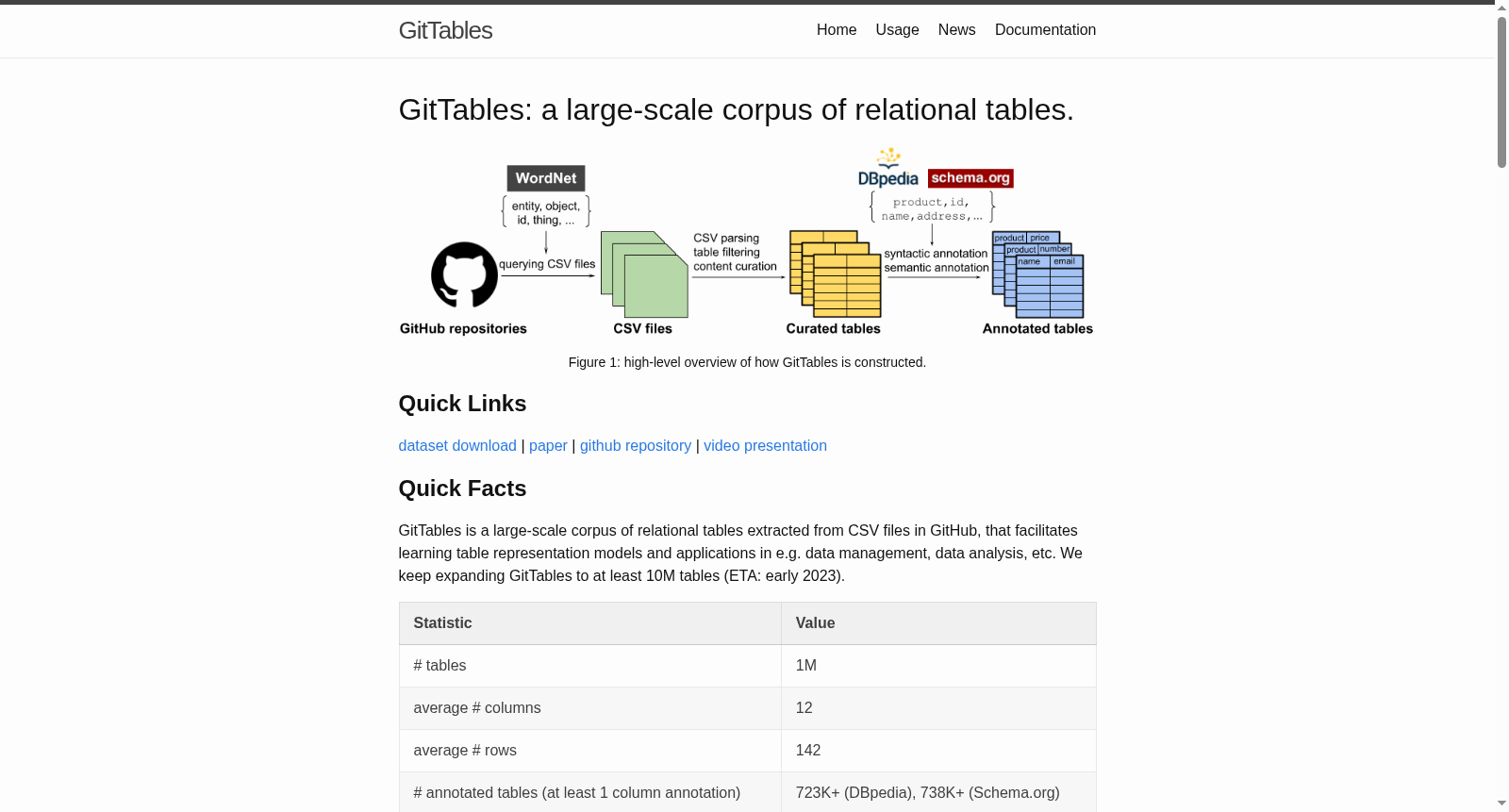
构建方式
GitTables 数据集源自 GitHub 上公开的真实关系表,通过系统爬取与清洗流程,收集了约一百万张涵盖多领域的表格。每张表均经过结构解析与语义标注,利用 DBpedia 和 Schema.org 的语义类型体系为列赋予丰富的语义标签。该数据集以 MIT 许可证发布,确保在学术与商业场景中的合法使用。构建过程中,剔除了列名无意义或仅含数值标识符的表格,保留了具有明确语义含义的列,从而为后续的模型预训练提供了高质量、多样化的数据基础。
使用方法
GitTables 主要用作预训练语料库,用于训练如 ZeroCard 等语义驱动的基数估计模型。使用时,研究者可从数据集中随机选取表格,为每张表生成 1 至 8 个谓词的查询,并记录真实基数以构建训练样本。模型通过列定义的文本描述提取语义嵌入,结合查询谓词表示,学习从语义到数据分布的映射。训练完成后,模型参数可冻结,直接应用于未见过的数据库,无需访问目标库的原始数据或查询日志,实现了即插即用的部署方式。
背景与挑战
背景概述
GitTables数据集由ByteDance团队于2025年提出,旨在解决数据库基数估计领域长期存在的泛化性难题。该数据集包含约100万张真实世界的关系表,覆盖超过2000种语义类型,并基于DBpedia和Schema.org进行了语义标注。核心研究问题在于设计一种无需依赖目标数据库原始数据、查询日志或重新训练的语义驱动基数估计方法。GitTables的构建为ZeroCard模型的预训练提供了大规模、多样化的训练基础,其丰富的语义信息使得模型能够从模式中学习数据分布特征,从而摆脱传统方法对数据访问的强依赖性。该数据集的出现标志着基数估计从数据驱动向语义驱动范式转变的重要里程碑,为数据库查询优化领域带来了全新的研究视角。
当前挑战
GitTables数据集面临的核心挑战在于解决基数估计对目标数据库的强依赖性。具体而言,现有方法大多需要扫描原始数据以构建统计结构或收集查询日志进行模型训练,这在实际部署中带来了高昂的数据获取成本和模型重训练开销。构建过程中,团队需从海量GitHub仓库中提取具有实际意义的表格,并过滤掉缺乏语义信息的列(如单字符标识符或纯数字序列),同时确保所有表格均采用MIT许可证以支持学术和商业应用。此外,生成涵盖1至8个谓词的查询时,需精确记录每个查询的真实基数,并剔除选择性过高的样本,这在大规模数据集上对计算效率和存储管理提出了严峻挑战。
常用场景
经典使用场景
GitTables 作为大规模真实关系表格语料库,在数据库与机器学习交叉领域中,常被用于预训练基线的构建。其包含逾百万张源自 GitHub 的表格,覆盖数千种语义类型,为模型提供了丰富多样的列语义与数据分布模式。研究者通常利用该数据集训练语义驱动的基数估计模型,如 ZeroCard,使其在未见过的数据库上实现即插即用的推理能力,无需依赖目标库的原始数据或查询日志。GitTables 的规模与语义多样性使其成为评估跨数据库泛化能力的理想基准,推动了从数据依赖向语义驱动的范式转变。
解决学术问题
GitTables 的核心学术贡献在于解决了学习型基数估计方法在跨数据库部署时面临的三大依赖问题:原始数据访问依赖、查询日志收集依赖以及模型重训练依赖。传统方法如数据驱动或查询驱动模型,在应用于新数据库时必须重新扫描数据或收集查询模板,导致高昂的部署成本与时间开销。GitTables 通过提供大规模、语义标注丰富的表格,使得研究者能够预训练语义感知的基数估计器,从而在推理阶段仅依据模式语义即可预测数据分布与谓词选择性。这一突破显著降低了学习型优化器在实际生产环境中的落地门槛,并启发了后续关于零样本基数估计的研究方向。
实际应用
在实际应用中,GitTables 驱动的 ZeroCard 模型可直接嵌入数据库系统的查询优化器,用于索引推荐与查询计划生成。例如,在 MySQL 环境中,ZeroCard 无需访问目标表的原始数据或历史查询日志,仅通过模式定义即可估算单表谓词的基数,进而辅助索引顾问选择最优索引集。实验表明,尽管 ZeroCard 的基数估计精度略逊于基于全量数据的直方图方法,但其在索引推荐任务中实现了与后者相当甚至更优的几何加速比,同时避免了数据扫描与采样开销。这一特性尤其适用于云数据库与数据湖场景,其中数据频繁迁移且模式多样,零依赖的基数估计显著降低了运维复杂度。
数据集最近研究
最新研究方向
在数据库查询优化领域,基数估计作为一项基础性任务,长期受限于对原始数据和查询日志的强依赖,这严重制约了学习型方法在实际场景中的泛化部署。针对这一瓶颈,近期研究开始探索语义驱动的全新范式,其中基于GitTables数据集预训练的ZeroCard方法尤为突出。该工作开创性地利用数据库模式中的语义信息预测数据分布,并设计模板无关的谓词表示,从而在无需目标数据库任何数据、查询日志或重训练的条件下,以即插即用的方式完成基数估计。这一突破不仅从根本上消除了传统方法对数据与查询的依赖,更通过在大规模真实表格上的预训练验证了语义信息在捕获列间关联与分布规律中的巨大潜力,为构建真正可落地的学习型查询优化器开辟了全新的研究方向。
相关研究论文
- 1驳回北京字节跳动科技有限公司 · 2025年
以上内容由遇见数据集搜集并总结生成


