HotpotAIMedVQA
收藏Hugging Face2025-07-15 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/hotpotai/HotpotAIMedVQA
下载链接
链接失效反馈官方服务:
资源简介:
HotpotAIMedVQA数据集是一个英文的生物医学领域的事实性多选问答数据集,包含少于1000个示例。该数据集旨在对模型在领域理解、情境推理和基于事实的问答方面的性能进行基准测试。数据集的注释由斯坦福大学的医生完成。
创建时间:
2025-07-09
原始信息汇总
HotpotAIMedVQA数据集概述
基本信息
- 名称: HotpotAIMedVQA
- 语言: 英语
- 规模: <1K示例
- 任务类型: 多项选择题问答(QA)
- 领域: 生物医学
数据集描述
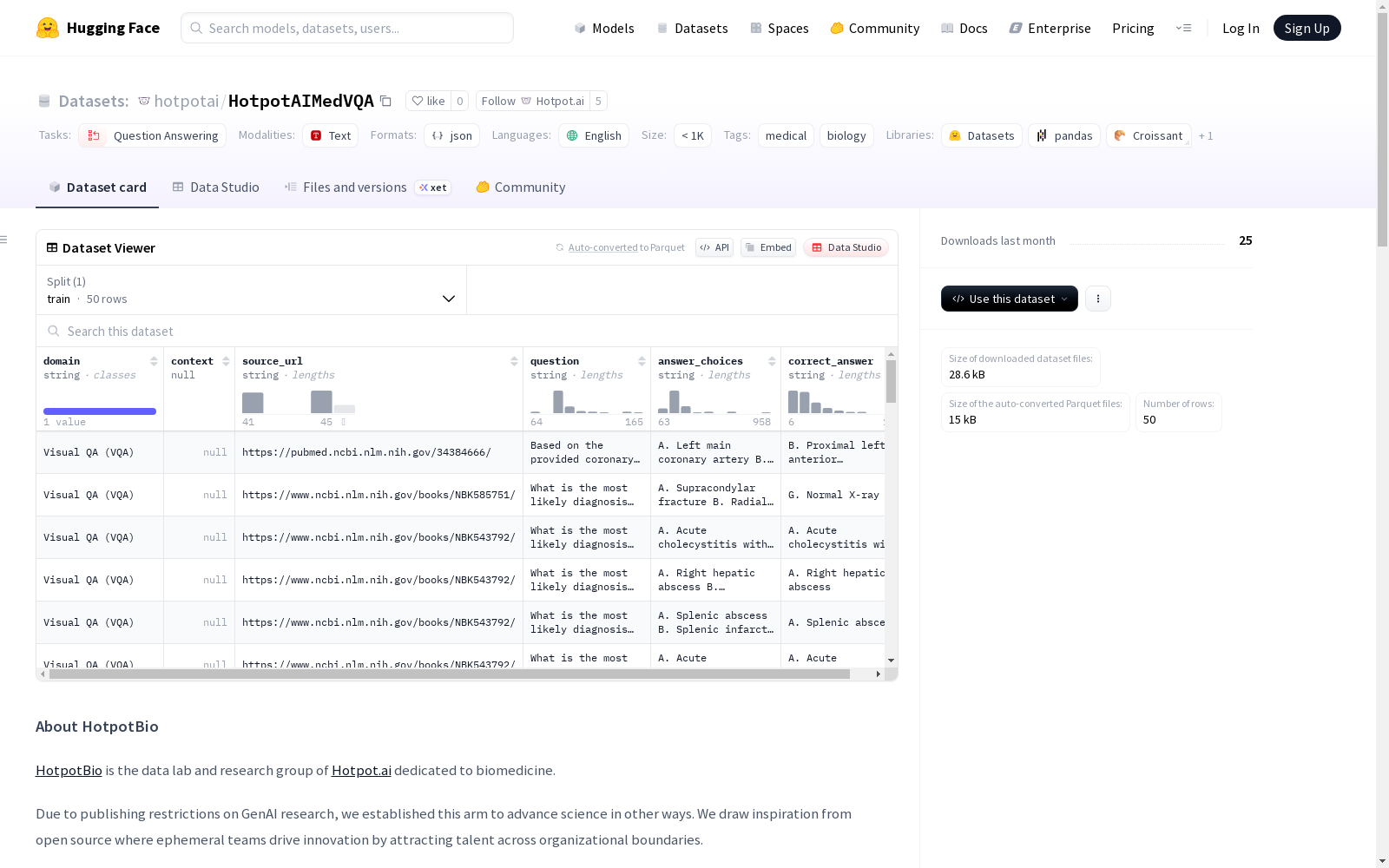
- 包含事实性生物医学多项选择题(MCQs),附带上下文段落和来源URL
- 旨在评估模型在生物医学领域的领域理解、上下文推理和基于事实的问答能力
数据列说明
| 列名 | 描述 |
|---|---|
domain |
生物医学领域/主题 |
context |
与问题相关的短文或源文本 |
question |
多项选择题 |
answer_choices |
可能的答案选项列表 |
correct_answer |
正确答案 |
source_url |
上下文的原始来源 |
应用场景
- 评估医疗LLMs和医疗应用中的事实性和视觉问答能力
- QA模型微调和基准测试
- 临床领域推理和上下文理解
数据特点
- 由斯坦福大学医生标注
- 严格验证的专家策划数据集
- 关注生物医学领域的精确性和最新指南
引用信息
bibtex
@misc{hotpotaimedmcq2025,
title = {HotpotAIMedVQA: Medical Visual QA},
author = {Hu, Clarence C. and Kamtam, Devanish N. and Cardona, Juan J.},
year = {2025},
publisher = {Hotpot.ai},
url = {https://hotpot.ai/bio},
howpublished = {url{https://huggingface.co/datasets/hotpotai/HotpotAIMedVQA}},
note = {Annotations performed by Stanford physicians}
}
联系方式
- 邮箱: info — at — hotpot.ai
搜集汇总
数据集介绍
构建方式
在生物医学领域,高质量数据集的构建依赖于专业知识的深度整合。HotpotAIMedVQA数据集的构建过程由斯坦福大学等顶尖机构的医学博士和博士后研究人员共同完成,他们依据最新临床指南对900道多项选择题进行了精确标注。每道题目均配有上下文段落和原始来源URL,确保了数据的可靠性和时效性。这种严格的专家验证机制有效避免了医学信息错误可能导致的临床误判,为模型训练提供了坚实的数据基础。
特点
该数据集专注于生物医学领域的事实性多项选择题问答,涵盖临床推理、肿瘤学、基因组学等多个专业方向。其核心特点在于所有问题均经过医学专家严格验证,并配有权威来源的上下文支持。数据集规模虽不足千例,但每个样本都包含完整的领域标注、问题题干、选项列表及标准答案,支持模型在领域理解、上下文推理和事实性问答方面的综合评估。这种设计特别适合检验模型在快速演变的医学知识环境下的适应能力。
使用方法
研究人员可利用该数据集对医疗大型语言模型进行事实性和视觉问答能力的评估,特别适用于临床领域推理任务的基准测试。使用时需加载包含领域分类、上下文段落、问题题干、选项列表和正确答案的结构化数据,通过比对模型输出与专家标注答案来量化性能。该数据集支持端到端的微调流程,也可作为验证集用于检测模型在动态医学知识环境下的稳健性,为生物医学AI应用提供可靠的评估框架。
背景与挑战
背景概述
HotpotAIMedVQA数据集由HotpotBio研究团队于2025年创建,该团队隶属于Hotpot.ai公司,专注于生物医学领域的人工智能研究。核心研究问题聚焦于通过多选问答形式评估模型在生物医学领域的领域理解、上下文推理和事实性问答能力。数据集由斯坦福大学医生团队参与标注,涵盖临床推理、肿瘤学、基因组学等多个专业领域,旨在推动机器学习在临床及生物医学应用中的发展,提升模型在医疗诊断和治疗决策中的准确性与可靠性。
当前挑战
该数据集致力于解决生物医学视觉问答中的领域挑战,包括模型对复杂医学语境的理解、多模态信息的整合以及事实性答案的精确生成。构建过程中面临医学数据标注的高难度,需依赖顶尖医学专家基于最新指南进行验证,以避免错误标注导致临床误诊或药物不良反应。同时,医学知识的动态演变使得训练数据可能迅速过时,例如2024年美国预防服务工作组对乳腺癌筛查指南的更新,要求数据集持续迭代以保持时效性和准确性。
常用场景
经典使用场景
在医学人工智能领域,HotpotAIMedVQA数据集被广泛用于评估多模态语言模型在生物医学视觉问答任务中的表现。该数据集通过提供专家验证的多选题及其相关上下文段落,为研究者构建了一个标准化的测试平台,用于检验模型在临床推理和事实检索方面的能力。其严谨的标注流程确保了评估结果的可信度,成为衡量模型医学知识掌握程度的重要工具。
衍生相关工作
基于该数据集衍生的经典研究包括多模态医学问答系统的联合训练框架,以及针对生物医学领域的事实验证算法。斯坦福研究团队开发了基于注意力机制的临床推理模型,通过融合上下文感知和知识检索技术,显著提升了医学问答的准确率。此外,该数据集还催生了面向医学知识更新的动态评估基准,为处理时效性医学信息提供了方法论创新。
数据集最近研究
最新研究方向
在生物医学人工智能领域,HotpotAIMedVQA数据集正推动临床推理与多模态整合的前沿探索。随着医疗指南动态更新与罕见病理变异的复杂性日益凸显,该数据集通过斯坦福医师团队的专业标注,为模型提供了精准的事实性问答基准。当前研究聚焦于医疗大语言模型的事实性验证与视觉问答能力评估,尤其在肿瘤学、基因组学等专科领域的应用备受关注。2024年美国预防服务工作组关于乳腺筛查指南的修订事件,进一步突显了医疗数据时效性对模型性能的关键影响。该数据集的推出为降低临床误诊风险、提升药物研发安全性提供了至关重要的验证基础,标志着医学人工智能向高可靠性迈进的实质性突破。
以上内容由遇见数据集搜集并总结生成


