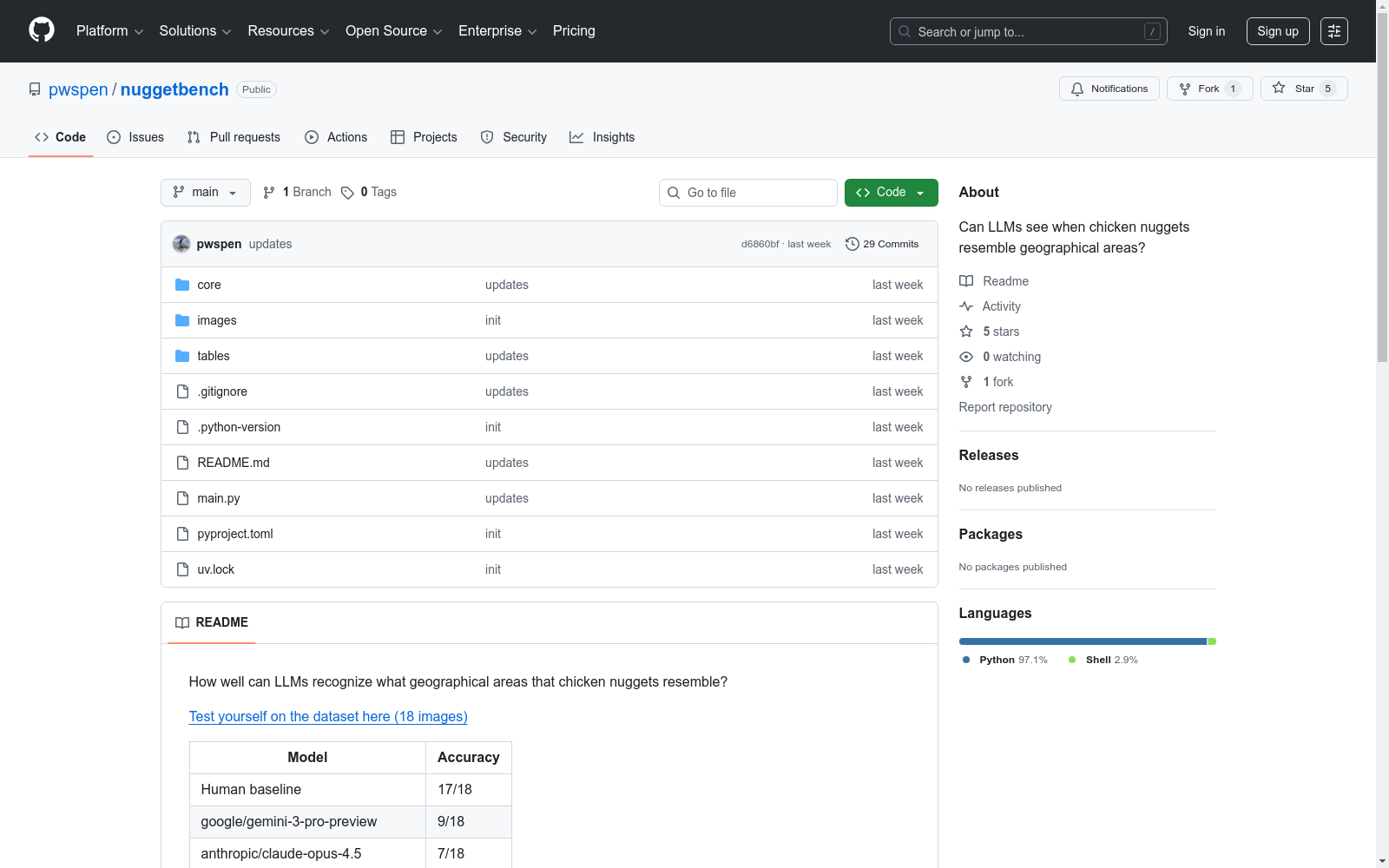
nuggetbench
收藏数据链接:
官方服务:
资源简介:
该数据集包含18张图片,展示了形状像著名地理区域(如美国州、国家和大陆)的鸡块。数据集用于测试大型语言模型(LLMs)在视觉敏锐度和世界知识方面的能力。
This dataset contains 18 images depicting chicken nuggets shaped like famous geographic regions, including U.S. states, countries, and continents. It is designed to test the visual acuity and world knowledge capabilities of large language models (LLMs).
创建时间:
2025-12-16
原始信息汇总
数据集概述
数据集名称与主题
- 名称:NuggetBench
- 核心主题:评估大型语言模型(LLMs)识别鸡块形状与地理区域相似性的能力。
数据集内容与构成
- 数据类型:图像数据集。
- 数据来源:互联网上收集的所有形状明显类似于著名地理区域(包括美国各州、国家和大陆)的鸡块图像。
- 数据规模:包含18张测试图像。
数据集目的与设计理念
- 主要目的:提供一个“无意义且愚蠢”的基准测试,以检验模型的视觉敏锐度和世界知识。
- 设计理念:通过测试一个不可能被专门训练的任务,来更好地评估模型在常见或合理的度量标准之外的真实能力,避免陷入古德哈特定律(Goodharts Law)所描述的“指标优化”陷阱。
评估方法与结果
- 评估任务:要求模型识别鸡块形状所对应的地理区域。
- 基准结果:
- 人类基线准确率:17/18
- google/gemini-3-pro-preview 准确率:9/18
- anthropic/claude-opus-4.5 准确率:7/18
- qwen/qwen3-vl-235b-a22b-instruct 准确率:5/18
- x-ai/grok-4-fast 准确率:4/18
- openai/gpt-5.2 准确率:2/18
数据集访问与使用
- 在线测试:用户可通过 https://github.com/pwspen/nuggetbench/blob/main/tables/answers.md 访问数据集并自行测试。
- 本地运行:
- 克隆代码仓库。
- 需预先安装
uv(安装指南:https://docs.astral.sh/uv/getting-started/installation/)。 - 设置
OPENROUTER_API_KEY环境变量。 - 执行命令
uv run main.py运行基准测试。
- 结果详情:每模型的详细结果位于 https://github.com/pwspen/nuggetbench/tree/main/tables。
搜集汇总
数据集介绍
构建方式
在计算机视觉与地理信息交叉领域,nuggetbench数据集的构建体现了独特的创意。该数据集通过系统性地从互联网上搜集所有形状酷似显著地理区域(如美国各州、国家及大洲)的鸡块图像,构建了一个视觉识别基准。这些图像经过人工筛选,确保每张图片中的鸡块轮廓与特定地理区域具有明确的相似性,从而形成一个既具趣味性又具备科学验证价值的图像集合。
特点
nuggetbench数据集的核心特点在于其巧妙融合了视觉感知与地理知识。数据集中的图像均呈现鸡块与地理区域形状之间的直观对应关系,要求模型不仅识别物体本身,还需关联其轮廓与真实世界的地理形态。这种设计使得评估超越了常规的视觉分类任务,转而检验模型在无意义却复杂的跨域联想能力,为衡量人工智能的泛化性能提供了新颖视角。
使用方法
使用nuggetbench数据集进行基准测试时,研究人员需克隆项目仓库并安装uv工具,同时设置OPENROUTER_API_KEY环境变量。通过运行main.py脚本,即可自动调用不同大型语言模型对数据集中图像进行地理区域识别,并将结果与人类基线及其他模型性能对比。该流程支持快速验证模型在非典型视觉任务上的表现,为评估模型视觉敏锐度与世界知识提供标准化测试框架。
背景与挑战
背景概述
在人工智能评测领域,随着大型语言模型(LLM)与多模态模型的快速发展,传统基准测试逐渐面临Goodhart定律的挑战,即模型可能过度优化可度量的指标而忽视广义能力。nuggetbench数据集应运而生,由独立研究者于近期创建,旨在通过一种新颖且无实际用途的任务——识别形状酷似地理区域的鸡块图像,来评估模型的视觉敏锐度与常识知识。该数据集包含18幅精心筛选的图像,每幅图像均呈现鸡块与特定国家、州或大陆轮廓的相似性,核心研究问题聚焦于模型在未经专门训练的情况下,能否结合视觉模式识别与地理知识进行准确推断。这一创新性评测框架为理解模型在非典型任务上的泛化能力提供了独特视角,对推动更鲁棒、更接近人类认知的人工智能评估体系具有启发意义。
当前挑战
nuggetbench数据集所针对的领域挑战在于,当前人工智能模型在标准视觉任务上表现卓越,但在需要融合低级视觉特征与高级世界知识的非结构化任务中,其泛化能力仍显不足。具体而言,模型必须克服从抽象、不规则的鸡块形状中提取轮廓特征,并将其映射到复杂的地理空间概念上,这一过程涉及跨模态联想与常识推理,对现有架构构成显著考验。在数据集构建过程中,主要挑战来源于图像素材的稀缺性与标注一致性:互联网上符合“明确形似地理区域”标准的鸡块图像数量有限,且需要确保每幅图像与对应地理区域的相似度足够显著,以避免主观歧义。此外,创建者需在无权威参考的情况下,自行确立并验证图像与地理区域的对应关系,这要求较高的领域知识与严谨的筛选流程,以保障评测的可靠性与公正性。
常用场景
经典使用场景
在视觉与地理知识交叉的评估领域,nuggetbench数据集以其独特的创意,为大型语言模型的多模态能力测试提供了一个经典场景。该数据集通过呈现形状酷似地理区域的鸡块图像,要求模型识别这些图像所对应的具体国家、州或大陆。这种设计巧妙地将无意义的视觉对象与严肃的地理知识相结合,旨在评估模型在未经专门训练的任务中,如何运用其视觉解析能力和世界知识进行推理,从而超越了传统基准测试的局限。
实际应用
在实际应用层面,nuggetbench虽非直接服务于生产环境,但其方法论对人工智能系统的可靠性评估具有深远影响。它启发开发者在设计自动驾驶、医疗影像分析或工业质检等关键系统时,需构建类似‘反直觉’或‘对抗性’的测试集,以暴露出模型在常规评估中难以察觉的脆弱性。这种评估范式有助于确保AI系统在面临真实世界复杂、非结构化输入时,其决策并非基于肤浅的模式匹配,而是根植于深层的理解和推理。
衍生相关工作
nuggetbench的独特视角催生了一系列关于模型评估哲学与方法的衍生讨论。它直接呼应并扩展了诸如‘抽象推理基准’和‘分布外泛化测试’等经典研究方向的工作。其核心思想——即通过无实用价值但需综合能力的任务来探测模型智能本质——与认知科学中用于衡量人类流体智力的测试设计理念一脉相承。该数据集激励后续研究探索更多脱离常规数据分布的‘干净’评估任务,以推动对人工智能通用能力更本质、更可靠的度量体系构建。
以上内容由遇见数据集搜集并总结生成


