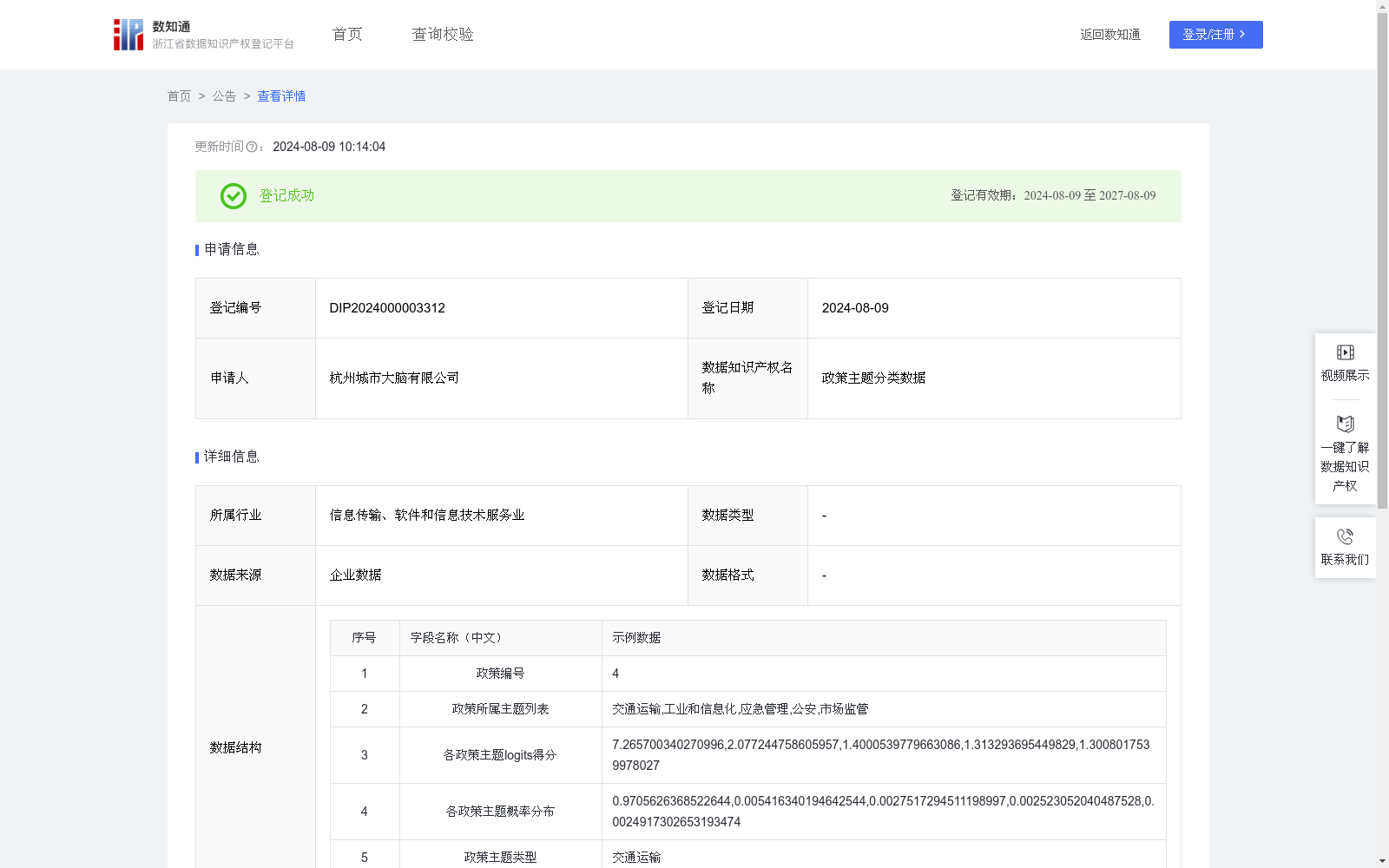
政策主题分类数据
收藏浙江省数据知识产权登记平台2024-08-09 更新2024-08-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/48726
下载链接
链接失效反馈官方服务:
资源简介:
政策公文主题分类是政府治理现代化的重要手段之一,对提升政府治理能力和社会管理服务水平具有重要意义。通过对政策文本进行主题分类,可以更快的响应用户政策检索需求,进一步提高工作效率。1.数据采集:从不同类型的政务公开网站上间隔性获取最新的政策公文,将其中的政策文本数据进行保存。
2.数据清洗:对采集的政策文本数据进行数据清洗,仅保留可用的政策公文信息。剔除文本数据中可能存在的URL、IP地址、电子邮件、手机号码、电话号码、身份证号码信息;剔除无效的政策文本数据,判断标准为汉字数量是否少于10、符号比例是否低于50%、中英文字符和数字的占有比例是低于10%、中文字符比例是否低于10%。
3.数据主题分类:对清洗好的政策文本数据,使用训练好的Bert变体模型进行政策主题分类。首先,使用BPE算法对政策文本数据进行分词后,对切分的子词进行向量化后作为Bert变体模型的编码器的输入。之后,将编码器中的多层Transformer中得到的上下文信息经过分类头得到每个政策主题的概率。最终,取概率最高的主题作为当前政策的主题。
Topic classification of official policy documents is one of the important means to advance the modernization of government governance, and holds great significance for enhancing government governance capabilities and social management and service levels. Conducting topic classification on policy texts can respond to users' policy retrieval demands more rapidly, and further improve work efficiency.
1. Data Collection: Intermittently acquire the latest policy documents from various types of government public disclosure websites, and save the contained policy text data.
2. Data Cleaning: Clean the collected policy text data and only retain valid policy document information. Remove potential URLs, IP addresses, email addresses, mobile phone numbers, landline telephone numbers, and ID card numbers from the text data; eliminate invalid policy text data, with the judgment criteria being whether the number of Chinese characters is less than 10, whether the proportion of symbols is lower than 50%, whether the proportions of Chinese and English characters and numbers are lower than 10%, and whether the proportion of Chinese characters is lower than 10%.
3. Data Topic Classification: Use the pre-trained BERT variant model to perform topic classification on the cleaned policy text data. First, conduct word segmentation on the policy text data via the BPE algorithm, vectorize the segmented subwords, and take them as the input of the encoder of the BERT variant model. Subsequently, pass the contextual information obtained from the multi-layer Transformer in the encoder through the classification head to acquire the probability of each policy topic. Finally, select the topic with the highest probability as the current policy's assigned topic.
提供机构:
杭州城市大脑有限公司
创建时间:
2024-07-16
搜集汇总
数据集介绍
特点
该数据集是由杭州城市大脑有限公司提供的政策主题分类数据,包含2528条每日更新的政策文本信息,每条数据详细记录了政策编号、主题列表及分类概率,应用于政府公文主题分类场景,采用Bert变体模型进行自动化分类处理。
以上内容由遇见数据集搜集并总结生成


