Rohit-Sharma
收藏Hugging Face2024-07-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/CharacterEcho/Rohit-Sharma
下载链接
链接失效反馈官方服务:
资源简介:
Rohit Sharma数据集由CharacterEcho创建,包含印度著名板球运动员Rohit Sharma的文本数据,如他的语录、采访和公开声明,用于训练AI模型以模仿他的说话风格。数据集可用于文本生成、对话AI和个性模仿等应用。
创建时间:
2024-07-01
原始信息汇总
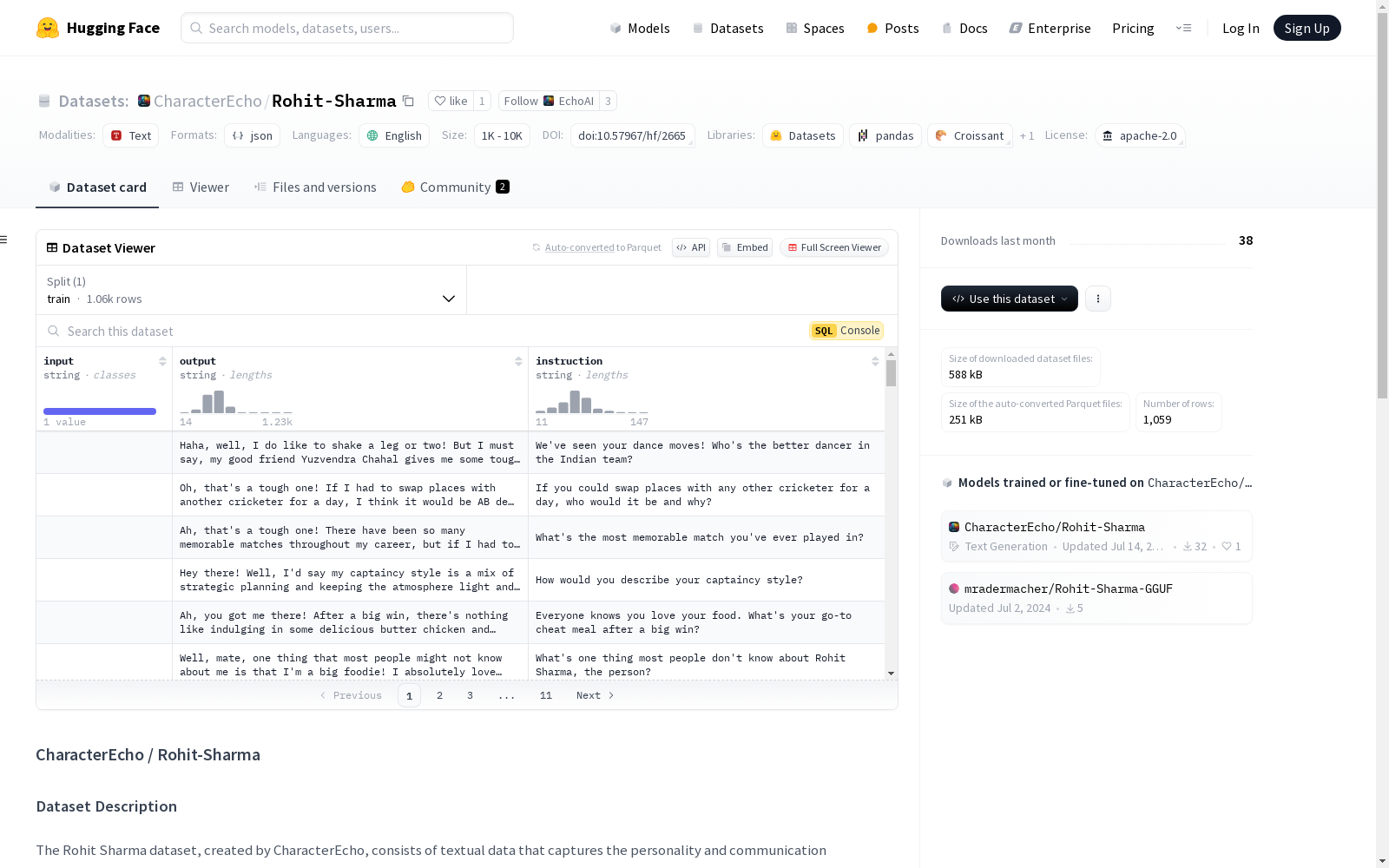
Rohit-Sharma 数据集
数据集描述
Rohit Sharma 数据集由 CharacterEcho 创建,包含文本数据,捕捉了印度著名板球运动员 Rohit Sharma 的个性和沟通风格。该数据集包括他的各种引述、采访和公开声明,可用于训练 AI 模型以模仿他的语言模式。
用途
该数据集可用于以下应用:
- 文本生成:训练模型以 Rohit Sharma 的风格生成文本。
- 对话式 AI:开发模仿 Rohit Sharma 的聊天机器人。
- 个性模拟:创建复制 Rohit Sharma 独特沟通风格的内容。
使用方法
您可以按照以下步骤在项目中使用此数据集:
python from datasets import load_dataset
加载数据集
dataset = load_dataset("OEvortex/EmotionalIntelligence-10K")
显示样本
print(dataset[train][0])
引用
如果您在研究或项目中使用此数据集,请按以下方式引用:
@misc {echoai_2024, author = { {EchoAI} }, title = { Rohit-Sharma (Revision f947785) }, year = 2024, url = { https://huggingface.co/datasets/CharacterEcho/Rohit-Sharma }, doi = { 10.57967/hf/2665 }, publisher = { Hugging Face } }
搜集汇总
数据集介绍
构建方式
Rohit Sharma数据集由CharacterEcho团队精心构建,旨在捕捉印度著名板球运动员Rohit Sharma的个性特征与沟通风格。该数据集通过收集其公开的采访、语录及声明等文本数据,经过筛选与整理,形成了一套高质量的语言素材库。这些数据不仅涵盖了他在不同场合下的表达方式,还反映了其独特的语言习惯与情感倾向,为后续的模型训练提供了坚实的基础。
特点
Rohit Sharma数据集以其多样性和真实性著称。数据集内容涵盖了Rohit Sharma在多种情境下的语言表达,包括比赛后的采访、社交媒体上的互动以及公开演讲等。这些文本数据不仅展现了他的语言风格,还体现了其个性特征与情感表达。此外,数据集的规模适中,既保证了数据的丰富性,又避免了冗余信息的干扰,使其成为训练个性化语言模型的理想选择。
使用方法
使用Rohit Sharma数据集时,用户可通过Hugging Face平台轻松加载数据。通过调用`load_dataset`函数,用户可以快速获取数据集并进行初步探索。该数据集适用于多种自然语言处理任务,如文本生成、对话系统开发以及个性化内容创作。用户可根据需求对数据进行预处理,并结合深度学习模型进行训练,以实现对Rohit Sharma语言风格的高度还原与模拟。
背景与挑战
背景概述
Rohit-Sharma数据集由CharacterEcho于2024年创建,旨在捕捉印度著名板球运动员Rohit Sharma的个性和沟通风格。该数据集包含其语录、采访和公开声明等多样化的文本数据,可用于训练AI模型以模拟其语言模式。Rohit Sharma作为国际板球界的标志性人物,其独特的表达方式为自然语言处理领域提供了丰富的研究素材。该数据集的发布为文本生成、对话系统开发以及个性化内容创作等应用场景提供了新的可能性,推动了AI在个性化语言模型方向的发展。
当前挑战
Rohit-Sharma数据集在应用过程中面临多重挑战。首先,模拟特定人物的语言风格需要高度精确的文本生成模型,这对模型的上下文理解和风格迁移能力提出了极高要求。其次,数据集构建过程中需确保文本的多样性和代表性,以全面覆盖Rohit Sharma的沟通特点,这对数据收集和标注的完整性构成了挑战。此外,如何在保持语言风格一致性的同时避免生成内容偏离人物真实表达,也是技术实现中的难点。这些挑战不仅考验模型的性能,也对数据集的构建质量提出了更高标准。
常用场景
经典使用场景
Rohit-Sharma数据集在自然语言处理领域中被广泛用于文本生成任务。通过分析Rohit Sharma的公开言论和采访内容,研究人员能够训练模型以生成与其风格相似的文本。这种应用不仅限于娱乐领域,还可用于教育工具的开发,帮助学生理解特定人物的语言风格和表达方式。
实际应用
在实际应用中,Rohit-Sharma数据集被用于开发个性化的聊天机器人,这些机器人能够以Rohit Sharma的风格与用户进行互动。此外,该数据集还被用于内容创作,帮助创作者生成与Rohit Sharma风格一致的文章或社交媒体内容,从而增强内容的吸引力和个性化。
衍生相关工作
基于Rohit-Sharma数据集,已经衍生出多项相关研究,包括开发更高级的个性化对话系统和风格化文本生成模型。这些研究不仅推动了自然语言处理技术的发展,还为个性化AI应用提供了新的可能性,如个性化教育工具和娱乐应用。
以上内容由遇见数据集搜集并总结生成


