stanfordnlp/SHP
收藏Hugging Face2023-10-10 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/stanfordnlp/SHP
下载链接
链接失效反馈资源简介:
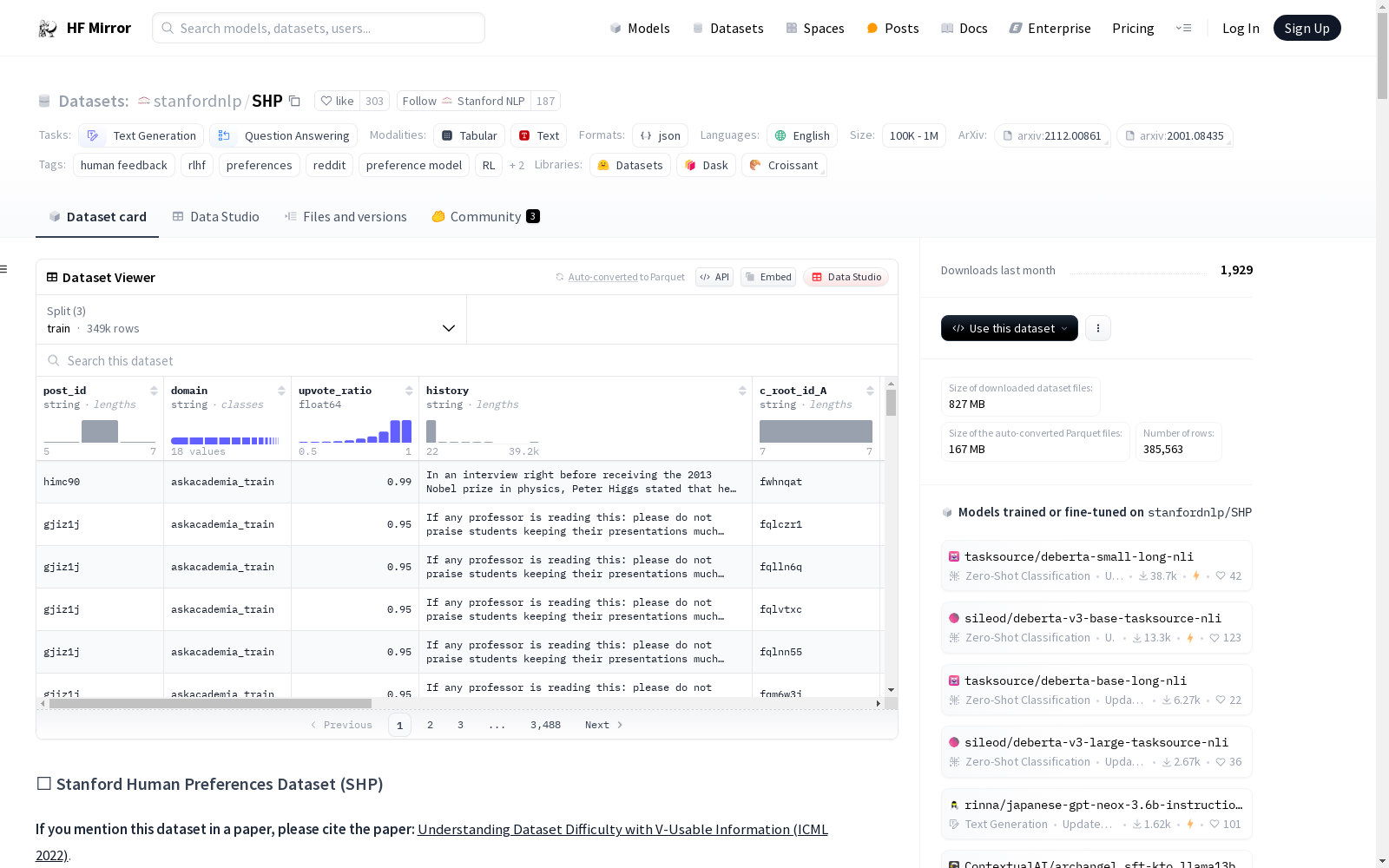
Stanford Human Preferences Dataset (SHP) 是一个包含385K条Reddit用户对18个不同主题领域的问题/指令的集体偏好的数据集,用于训练RLHF奖励模型和NLG评估模型。每个示例是一个Reddit帖子,包含一个问题/指令和一对顶级评论,其中一个评论更受Reddit用户集体偏好。数据集通过时间戳信息推断偏好,确保偏好反映的是评论的‘帮助性’而非‘有害性’。数据集包含18个子论坛的训练、验证和测试数据,每个子论坛的数据以JSONL文件格式存储。
Stanford Human Preferences Dataset (SHP) is a dataset containing 385K collective preference records from Reddit users regarding questions or instructions across 18 distinct thematic domains, which is intended for training RLHF reward models and natural language generation (NLG) evaluation models. Each example is a Reddit post that includes a question or instruction and a pair of top-level comments, with one of the two comments being more preferred by the collective Reddit user base. The dataset infers user preferences via timestamp information, ensuring that the captured preferences reflect the "helpfulness" rather than "harmfulness" of the comments. The dataset covers training, validation and test splits for 18 subreddits, with data for each subreddit stored in JSONL file format.
提供机构:
stanfordnlp
原始信息汇总
数据集概述
数据集名称
Stanford Human Preferences Dataset (SHP)
数据集大小
385K 条数据
数据集任务类别
- 文本生成
- 问答
数据集标签
- 人类反馈
- RLHF
- 偏好
- 偏好模型
- RL
- NLG
- 评估
数据集语言
英语
数据集内容
SHP 包含 385K 条人类对回答问题/指令的偏好数据,涵盖 18 个不同领域,如烹饪、法律咨询等。每个示例包含一个 Reddit 帖子,一个问题/指令以及该帖子的两个顶级评论,其中一个评论被 Reddit 用户集体更偏好。
数据集结构
数据集分为 18 个目录,每个目录代表一个子论坛,每个目录包含用于训练、验证和测试的 JSONL 文件。
数据集用途
用于训练 RLHF 奖励模型和 NLG 评估模型。
数据集与其他数据集的区别
- 与 Anthropics HH-RLHF 数据集相比,SHP 的数据均为自然发生和人类编写,而 HH-RLHF 的回答是机器编写。
- 与 ELI5 数据集相比,SHP 使用时间戳信息推断偏好,而 ELI5 仅提供评论和分数。
数据集预处理
预处理保持最小化,包括扩展子论坛特定缩写和移除超链接中的 URL。
构建偏好模型
建议使用大型模型进行微调,如 FLAN-T5-xl,以预测人类偏好,并建议根据 score_ratio 报告性能曲线。
数据集限制
- SHP 不用于伤害最小化,不包含学习毒性检测所需的毒性内容。
- 更偏好的响应不一定更事实准确。
数据集许可证
根据 Reddit API 使用条款进行数据抓取,用户内容所有权归用户所有,Reddit 授予非独占、不可转让、不可再授权和可撤销的许可。
数据集联系信息
联系邮箱:kawin@stanford.edu
数据集创建者
Kawin Ethayarajh, Heidi (Chenyu) Zhang, Yizhong Wang, Dan Jurafsky
搜集汇总
数据集介绍
构建方式
斯坦福人类偏好数据集(SHP)的构建采用了对Reddit平台上的帖子及其评论进行抓取的方式。通过分析帖子的时间戳和评分信息,该数据集提炼出了人类对评论帮助性的集体偏好。具体而言,数据集包含了18个不同主题的子版块,每个子版块下有训练、验证和测试三个数据集,数据通过子版块内的帖子ID进行划分,确保了数据的多样性和代表性。
特点
SHP数据集的特点在于其利用了Reddit平台上评论的时间戳信息来推断偏好,而非单纯依赖评分。此外,数据集涵盖了18个不同领域的子版块,包括了从烹饪到法律咨询等多样化的主题,使得该数据集在领域覆盖上具有广泛性。每个示例包含了一个问题或指令以及两个顶级评论,通过集体的偏好标签,为训练RLHF奖励模型和NLG评估模型提供了有力的基础。
使用方法
使用SHP数据集时,用户可以通过HuggingFace的datasets库来加载整个数据集或特定子版块的数据。数据集的结构包括多个字段,如帖子ID、领域、评分比例、偏好标签等,这些字段为用户提供了丰富的信息来进行模型训练和评估。加载数据后,用户可以根据需要对其进行预处理,以适应不同模型的输入要求,进而进行微调、评估等操作。
背景与挑战
背景概述
斯坦福人类偏好数据集(SHP)是一款汇集了385K条人类对问题/指令响应的集体偏好数据集,涵盖了18个不同的主题领域。该数据集创建于2022年,主要研究人员来自于斯坦福大学,其核心研究问题是如何理解和利用人类偏好信息来训练强化学习奖励模型和自然语言生成评价模型。SHP数据集对相关领域产生了重要影响,为研究人类偏好提供了丰富的实验资源。
当前挑战
SHP数据集在构建过程中遇到的挑战主要包括:1)如何准确捕捉并利用人类在Reddit上的偏好信息,特别是在处理时间戳和评分之间的关系时;2)如何确保数据集的多样性和平衡性,避免特定领域的过度代表;3)如何在保持数据质量的同时,处理Reddit数据中的噪声和潜在的有害内容;4)如何设计和实现有效的偏好模型,使其在不同领域和不同条件下都能保持良好的性能。
常用场景
经典使用场景
斯坦福人类偏好数据集(SHP)广泛应用于自然语言处理领域,其经典使用场景在于训练和评估基于人类偏好的模型,如强化学习中的奖励模型和自然语言生成(NLG)的评价模型。该数据集通过收集Reddit上的用户评论,利用评论的时间戳和得分差异来推断人类对回答的偏好,进而优化模型对问题回答的准确性和有效性。
实际应用
在实际应用中,SHP数据集可被用于改进聊天机器人、推荐系统和个性化搜索等,通过模拟人类偏好,这些系统能够提供更加精准和符合用户期望的服务。此外,它还可以用于广告投放和内容优化,以增强用户互动和满意度。
衍生相关工作
基于SHP数据集,衍生出了多项相关工作,包括SteamSHP模型,这是一种经过微调的偏好模型,用于评估NLG和构建RLHF奖励模型。这些工作进一步扩展了SHP数据集的应用范围,推动了自然语言处理领域的发展。
以上内容由遇见数据集搜集并总结生成


