MS COCOAI
收藏arXiv2026-01-02 更新2026-01-06 收录
下载链接:
https://huggingface.co/datasets/Rajarshi-Roy-research/Defactify_Image_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
MS COCOAI是由国际联合团队构建的大规模AI生成图像检测数据集,包含9.6万条语义对齐的真实与合成图像-标题对。该数据集以MS COCO真实图像为基准,通过Stable Diffusion 3/2.1、SDXL、DALL-E 3和MidJourney v6五种生成模型创建对应合成样本,每张真实图像对应五种生成风格。数据集包含原始分辨率图像、人工标注标题、二分类标签(真实/AI生成)和生成模型溯源标签,并附加水平翻转、亮度调节等四种扰动变体。其核心价值在于提供语义对齐的对照数据,支持生成痕迹分析与模型指纹识别研究,适用于数字内容鉴伪、生成模型安全评估等前沿领域。
MS COCOAI is a large-scale AI-generated image detection dataset constructed by an international collaborative research team. It encompasses 96,000 semantically aligned real and synthetic image-caption pairs. Built upon real images from the MS COCO dataset, corresponding synthetic samples are generated for each real image using five generative models: Stable Diffusion 3/2.1, SDXL, DALL-E 3, and MidJourney v6, resulting in five distinct generated styles per real image. The dataset includes raw-resolution images, manually annotated captions, binary classification labels (real/AI-generated), generative model attribution labels, as well as four types of perturbation variants such as horizontal flipping and brightness adjustment. Its core value lies in providing semantically aligned controlled data to support research on generative trace analysis and model fingerprint recognition, and it is applicable to cutting-edge fields including digital content forgery detection and generative model security evaluation.
提供机构:
Kalyani Govt. Engg. College; AI Institute USC; 德里印度理工学院; 比拉尼理工学院海得拉巴分校; 古瓦哈提印度理工学院; 西尔查国立技术学院; 圣何塞州立大学; 加州大学洛杉矶分校; 华盛顿州立大学; VIIT; GITA; Meta AI; 亚马逊AI; 比拉尼理工学院果阿分校
创建时间:
2026-01-02
原始信息汇总
AI-Generated Image Veracity Dataset 数据集概述
数据集基本信息
- 数据集名称:AI-Generated Image Veracity Dataset
- 数据集地址:https://huggingface.co/datasets/Rajarshi-Roy-research/Defactify_Image_Dataset
- 语言:英文(所有描述文本和标题均为英文)
- 下载大小:7508933957 字节
- 数据集大小:6494581450 字节
数据集内容与目的
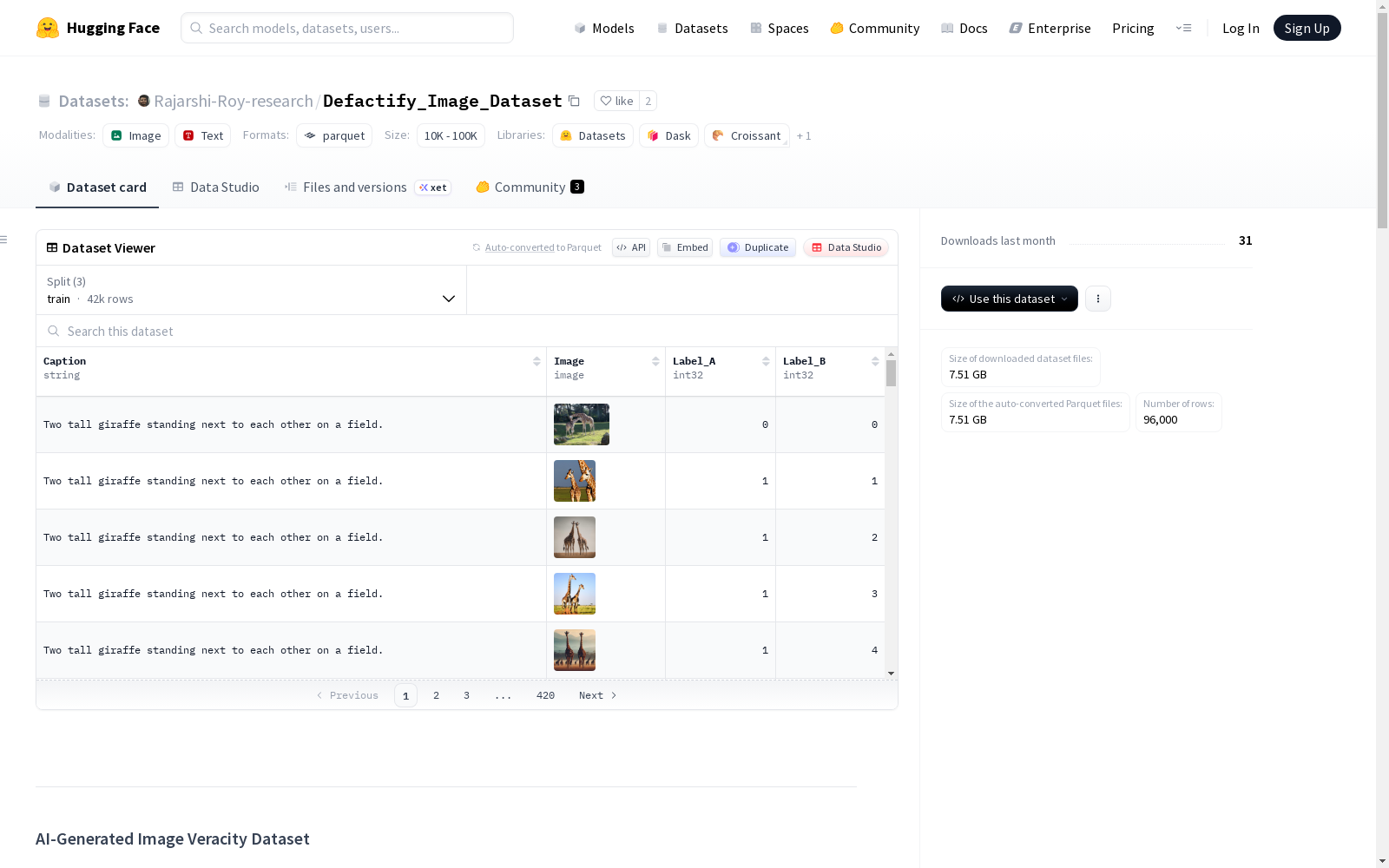
该数据集是一个高质量的图像及相关元数据集合,旨在为检测和识别人工智能生成内容的来源提供基准测试。数据集包含真实世界图像以及由主流AI模型生成的图像,这些模型包括SD21、SDXL、SD3、DALLE3和Midjourney。每个图像都经过精心标注,支持两个不同的计算机视觉任务:二元真伪分类和多类别来源模型识别。
支持的任务
数据集直接支持以下两个关键图像分类任务:
- 任务A(二元真实性分类):将图像分类为真实或AI生成。
- 任务B(AI模型来源识别):识别被标记为AI生成图像所使用的特定AI生成模型。
数据结构与字段
数据实例
每个数据实例包含一个图像文件、用于生成图像的文本标题(如适用)以及两个详细说明其来源和真实性的标签。
数据字段
| 字段名 | 数据类型 | 描述 |
|---|---|---|
Caption |
string |
用于生成图像的文本提示,或真实图像的描述性标题。 |
Image |
datasets.Image() |
实际的图像内容(例如 .jpg, .png)。 |
Label_A |
datasets.ClassLabel |
任务A标签:图像真实性的二元标签。 |
Label_B |
datasets.ClassLabel |
任务B标签:指定生成来源/模型的标签。 |
标签定义
Label_A(二元真实性分类)
| 标签 | 值 | 描述 |
|---|---|---|
| Real | 0 |
图像是真实的照片/非AI生成。 |
| AI-Generated | 1 |
图像由AI生成模型创建。 |
Label_B(模型来源识别)
| 标签 | 值 | 模型/来源 |
|---|---|---|
| Real | 0 |
真实图像(不涉及AI生成)。 |
| SD21 | 1 |
由 Stable Diffusion 2.1 生成。 |
| SDXL | 2 |
由 Stable Diffusion XL 生成。 |
| SD3 | 3 |
由 Stable Diffusion 3 生成。 |
| DALLE3 | 4 |
由 DALL-E 3 生成。 |
| Midjourney | 5 |
由 Midjourney 6(或使用的最新版本)生成。 |
数据划分
| 划分 | 实例数量 | 说明 |
|---|---|---|
train |
42000 | 推荐用于模型训练。 |
validation |
9000 | 推荐用于超参数调优。 |
test |
45000 | 用于最终的无偏评估。 |
搜集汇总
数据集介绍
构建方式
在合成图像检测领域,构建具有语义对齐特性的数据集对于分离内容偏差与生成伪影至关重要。MS COCOAI数据集以MS COCO数据集为基础,从中随机抽取16,000张图像及其对应的人类撰写描述作为种子。每个描述均被用作文本提示,通过五种前沿图像生成模型——Stable Diffusion 3、Stable Diffusion 2.1、SDXL、DALL-E 3和MidJourney v6——生成合成图像,确保每个提示对应一个合成样本。真实图像直接来源于MS COCO,所有图像均保持原始分辨率,未进行任何尺寸调整或归一化处理。此外,为增强数据集的鲁棒性,对每张合成图像独立应用了水平翻转、亮度降低、高斯噪声添加和JPEG压缩四种扰动变换,生成了多样化的增强版本。
特点
该数据集的核心特征在于其语义对齐的设计理念,所有合成图像均基于与真实图像相同的文本描述生成,从而有效隔离了内容偏差对检测任务的影响。数据集规模宏大,涵盖96,000个图像-描述对,均衡覆盖了真实图像与五种生成模型的输出,为模型评估提供了全面基准。其标注体系精细,不仅包含图像真伪的二元标签,还提供了具体的生成模型类别标签,支持从二元分类到多类模型溯源的多层次研究。数据集中描述的语义多样性广泛,涉及城市环境、室内场景、野生动物、交通工具等多个概念范畴,确保了检测模型在不同视觉概念上的泛化能力。
使用方法
该数据集主要支持两项核心任务:其一是二元分类任务,旨在区分图像为真实拍摄或AI生成;其二是模型识别任务,要求判定合成图像的具体生成模型。研究人员可将数据集按既定划分用于训练、验证与测试,开发并评估各类检测算法。基于频率域表示的ResNet-50分类器已作为基线模型建立,为后续研究提供了性能参照。数据集的结构化设计便于直接加载与处理,图像与标签的对应关系清晰,支持端到端的模型训练流程。通过利用其扰动版本,研究者可进一步探究检测方法在常见图像变换下的鲁棒性与泛化性能。
背景与挑战
背景概述
随着Stable Diffusion、DALL-E等生成式人工智能技术的迅猛发展,合成图像的逼真度已逼近真实照片,这为虚假信息传播和媒体操纵带来了严峻挑战。为应对这一紧迫问题,由Rajarshi Roy、Amitava Das等来自多所高校与Meta、Amazon等机构的研究人员于2025年共同构建了MS COCOAI数据集。该数据集以经典的MS COCO数据集为基础,通过五类前沿生成模型(包括Stable Diffusion 3、DALL-E 3等)生成了语义对齐的合成图像,旨在为AI生成图像检测提供大规模、多样化的基准资源。其核心研究聚焦于区分真实与合成图像,并追溯图像的具体生成模型,从而推动数字媒体可信认证与安全治理领域的技术发展。
当前挑战
MS COCOAI数据集致力于解决AI生成图像检测中的两大核心挑战:在领域问题层面,生成模型迭代迅速导致合成图像与真实图像在视觉特征上日益趋同,传统检测方法难以捕捉细微的生成痕迹;同时,多模型共存的生态要求检测系统具备跨模型的泛化能力,避免对特定生成器过拟合。在构建过程中,研究团队面临语义对齐的难题——需确保合成图像与真实图像共享相同文本描述,以剥离内容偏差对检测结果的干扰;此外,整合开源与闭源生成器、涵盖多样化扰动以评估模型鲁棒性,亦是数据集设计中的关键挑战。
常用场景
经典使用场景
在生成式人工智能迅猛发展的背景下,MS COCOAI数据集为AI生成图像检测研究提供了标准化的评估基准。该数据集最经典的使用场景是作为二元分类任务的训练与测试平台,研究者利用其语义对齐的图像-文本对,开发能够区分真实摄影与AI生成图像的算法。通过对比同一文本描述下不同生成模型的输出,该数据集有效揭示了各类模型在视觉特征上的细微差异,为检测模型提供了丰富的学习样本。
解决学术问题
该数据集主要解决了生成式AI时代面临的两个核心学术问题:一是如何准确识别图像的人工智能来源,二是如何追溯特定合成图像的生成模型。通过提供涵盖五种主流生成器的语义对齐样本,数据集消除了内容偏差对检测结果的干扰,使研究者能够专注于生成痕迹的特征提取。这为开发鲁棒性更强的跨模型检测算法奠定了数据基础,推动了数字媒体取证领域的方法论创新。
衍生相关工作
基于MS COCOAI数据集,学术界衍生出多项经典研究工作。频率域分析方法通过傅里叶变换捕捉生成图像的频谱特征,成为检测模型的重要预处理步骤。混合特征融合方法结合高层语义与底层噪声模式,显著提升了跨生成器的泛化性能。此外,针对数据集设计的对抗性扰动测试框架,推动了鲁棒性检测器的演进,为应对日益复杂的图像篡改手段提供了技术储备。
以上内容由遇见数据集搜集并总结生成


