CUSP
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/SeanWu25/CUSP
下载链接
链接失效反馈官方服务:
资源简介:
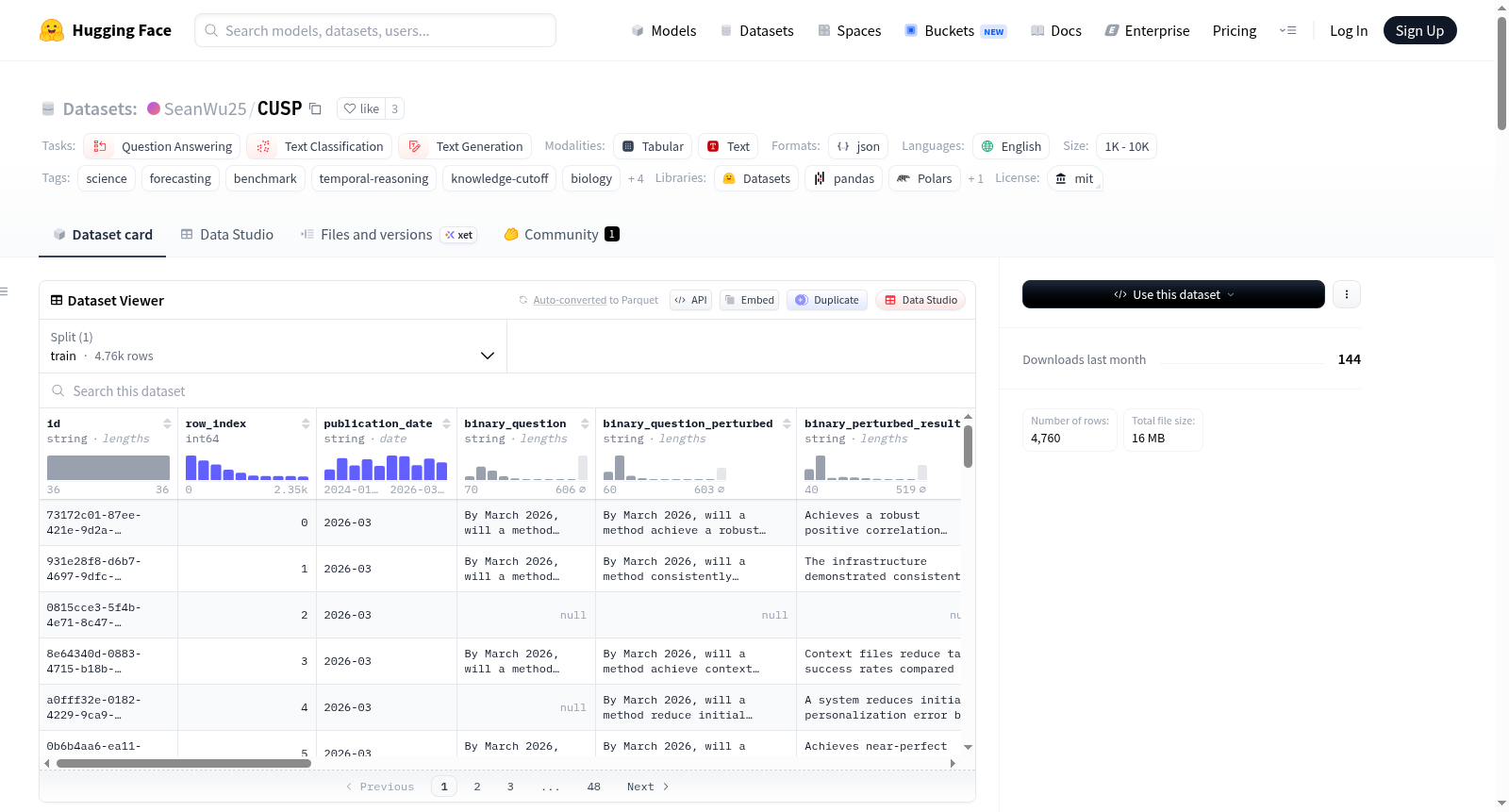
CUSP(Cutoff-conditioned Unseen Scientific Progress)是一个用于评估人工智能系统在历史知识截止条件下预测科学进展能力的基准数据集。其核心目标是测试模型的前瞻性推理能力,即给定一个模型的训练知识截止日期,该模型能否预测在该日期之后实际发生的真实科学发现。数据集聚焦于评估科学预见性,而非对已知事实的推理。数据内容来源于六种权威科学出版物,涵盖八个核心研究领域,包括生物学、医学、化学、物理学、环境科学、材料科学、细胞生物学和人工智能。数据的时间覆盖范围从2023年3月到2026年2月。数据集规模在1,000到10,000个样本之间。每个数据样本对应一篇真实发表的科学论文,并以JSON Lines格式存储,包含丰富的元数据和多种任务格式,如样本唯一标识符、论文来源、高层研究领域、细粒度研究子领域、论文标题、摘要、数字对象标识符、真实发表日期以及模型知识截止日期。数据集设计了五种不同的任务变体来多角度评估模型:二元问题、扰动二元问题、多项选择题、自由回答题和日期预测。该数据集适用于问答、文本分类和文本生成等任务,特别用于科学预测、时间推理和知识截止感知的模型评估,并采用双轨框架进行严格评估,数据经过多阶段验证以确保质量。
CUSP (Cutoff-conditioned Unseen Scientific Progress) is a benchmark dataset for evaluating the ability of artificial intelligence systems to predict scientific progress under historical knowledge cutoff conditions. Its core objective is to test the forward-looking reasoning capability of models, i.e., given a models training knowledge cutoff date, whether the model can predict real scientific discoveries that actually occurred after that date. The dataset focuses on assessing scientific foresight rather than reasoning about known facts. The data content is sourced from six authoritative scientific publications, covering eight core research areas, including biology, medicine, chemistry, physics, environmental science, materials science, cell biology, and artificial intelligence. The temporal coverage of the data ranges from March 2023 to February 2026. The dataset size ranges between 1,000 and 10,000 samples. Each data sample corresponds to a real published scientific paper and is stored in JSON Lines format, containing rich metadata and multiple task formats, such as sample unique identifier, paper source, high-level research domain, fine-grained research subdomain, paper title, abstract, digital object identifier, ground truth publication date, and model knowledge cutoff date. The dataset designs five different task variants to evaluate models from multiple perspectives: binary questions, perturbed binary questions, multiple-choice questions, free-response questions, and date prediction. It is suitable for tasks such as question answering, text classification, and text generation, particularly for scientific prediction, temporal reasoning, and knowledge cutoff-aware model evaluation, employing a dual-track framework for rigorous assessment, with data undergoing multi-stage validation to ensure quality.
创建时间:
2026-05-08
搜集汇总
数据集介绍
构建方式
CUSP数据集专为检验人工智能系统在历史知识截止条件下的科学进展预测能力而构建。其数据源自《自然》《科学》《细胞》等顶级期刊以及Hugging Face顶尖论文与arXiv每周十大AI论文,覆盖生物学、医学、化学、物理学与人工智能等领域。每条数据对应一篇真实已发表论文,并设置五种任务变体,包括二元判断、扰动二元判断、多项选择、自由回答及日期预测。该数据集通过设定明确的知识截止日期,构建出一套能够评估模型在时间轴上的前瞻性推理能力的基准。
使用方法
用户可通过Hugging Face平台便捷加载CUSP数据集,支持从`huggingface_hub`下载`CUSP_final.jsonl`文件,或使用`datasets`库直接读取为数据集对象。数据以JSON Lines格式存储,每条记录包含来源、领域、题目类型、答案及截断日期等字段。官方提供配套评估代码,用户可克隆GitHub仓库并运行脚本生成模型预测,再通过LLM裁判进行评估并生成结构化报告,便于系统化地测评模型在科学预见性任务上的表现。
背景与挑战
背景概述
CUSP数据集由Sean Wu、Pan Lu、Yupeng Chen、Jonathan Bragg、Yutaro Yamada、David Clifton、Philip Torr、James Zou和Junchi Yu等研究人员于2026年共同创建,旨在评估人工智能系统在历史知识截止条件下预测科学进步的能力。该数据集聚焦于生物学、医学、化学、物理学和人工智能等多个前沿领域,其核心研究问题在于检验模型能否基于训练截止日期前的知识,准确预测截止之后发生的真实科学发现。与仅测试已知事实推理的传统基准不同,CUSP开创性地引入了“前瞻性推理”评估范式,通过二元判断、多项选择、自由回答和日期预测等多种任务变体,全面衡量AI对未来科学突破的预见能力。该数据集对科学预测、AI推理评估及知识时效性研究等领域具有重要影响,为模型在动态知识环境下的适应性评估提供了标准化测试平台。
当前挑战
CUSP数据集所解决的领域核心问题在于,现有基准测试多局限于对已有知识的回顾性评估,无法衡量AI模型在知识截止条件下对未知科学发现的预测能力。该挑战具体包括:1)模型需要基于有限的历史知识进行前瞻性推理,而非简单的记忆检索;2)科学研究本身具有高度不确定性和非确定性,预测结果难以用简单正确与否进行评判;3)不同科学领域的进展速度悬殊,跨领域预测难度差异显著。在数据集构建过程中,研究人员面临的挑战包括:1)从Nature、Science、Cell等顶级期刊及AI前沿论文中筛选真实且具有时间敏感性的科学发现,确保每个样本都对应实际已发表的论文;2)设计五类任务变体以全面覆盖不同推理维度,同时维持评估框架的客观性和可复现性;3)建立双轨大语言模型评判机制,在评估结果正确性的同时,还需检测推理过程的机制合理性、泄漏风险及可行性,这对评判模型自身的鲁棒性提出了极高要求。
常用场景
经典使用场景
CUSP数据集(Cutoff-conditioned Unseen Scientific Progress)为评估人工智能系统在历史知识截止条件下的科学预见能力提供了开创性基准。该数据集的核心用途是检验模型是否能够基于其训练数据截止日期之前的知识,准确预测此后发生的真实科学发现。通过涵盖二元判断、扰动二元判断、多项选择、自由回答以及日期预测五种任务形式,CUSP全面衡量模型在生物、医学、化学、物理和人工智能等前沿科学领域的远见推理能力,成为推动人工智能前向推理研究的关键工具。
解决学术问题
该数据集直面传统基准测试无法触及的核心学术问题:模型能否超越记忆已知事实,真正理解科学进步的内在逻辑并预测未知发现?CUSP通过将每一条测试实例锚定经过同行评议的真实学术论文,结合严格的时间分割设计,系统性地评估模型在知识截止条件下的归纳与推演能力。此基准的发布有效填补了评估模型科学预见性的空白,揭示了当前大规模语言模型在因果推理和时序理解方面的局限性,为理解人工智能的认知边界提供了实证基础。
实际应用
在实际应用中,CUSP数据集为科研辅助系统的研发提供了度量标尺。科学探索机构可利用该基准筛选出具备较强科学洞察能力的模型,辅助研究者生成实验假设、预测新兴技术突破方向,甚至提前数月预判高影响力期刊可能发布的重大发现。此外,该数据集在科学政策制定、科研资金分配以及技术趋势预测等场景中也展现出应用潜力,能够帮助决策者基于模型分析结果更有效地配置研究资源和锁定前沿课题。
数据集最近研究
最新研究方向
当前,科学预测的前沿研究正聚焦于评估人工智能系统在知识截止条件下的前瞻性推理能力。CUSP数据集应运而生,它创新性地构建了一个涵盖生物学、医学、化学、物理学及人工智能等领域的基准测试平台,通过二选、多项选择、自由回答及日期预测等多元任务,系统性地考察模型能否基于历史数据截断点,准确预判后续真实发生的科学发现。该数据集收录了2023年3月至2026年2月间《自然》《科学》《细胞》等顶级期刊及AI前沿论文的实证进展,并采用双轨评估框架,既校验答案正确性,又深入分析推理过程的泄露风险与机制合理性。CUSP的提出标志着从“回顾性知识问答”向“前瞻性科学推论”的关键转型,为衡量AI在动态科研前沿中的预测效能与潜在局限提供了标准化工具,对推动人工智能辅助科学发现的研究具有深远意义。
以上内容由遇见数据集搜集并总结生成


