sdiazlor/math-preference-dataset
收藏Hugging Face2024-05-21 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/sdiazlor/math-preference-dataset
下载链接
链接失效反馈官方服务:
资源简介:
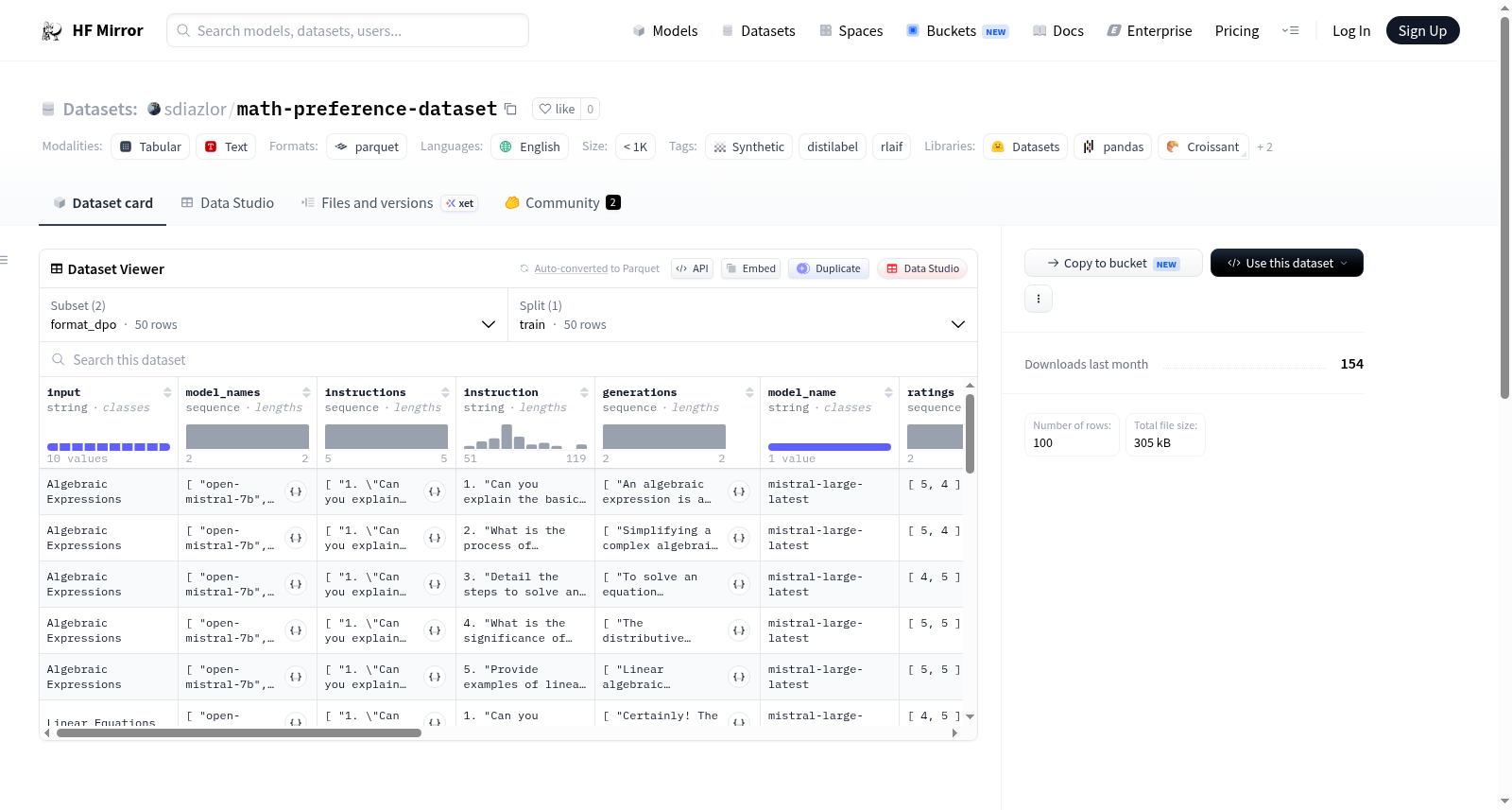
该数据集包含两个配置:format_dpo和preference_to_argilla_0,每个配置都有不同的特征和示例结构。数据集主要用于数学偏好相关的任务,包含代数表达式的解释和评分等内容。数据集的生成使用了distilabel工具,并提供了pipeline.yaml文件用于复现生成过程。
该数据集包含两个配置:format_dpo和preference_to_argilla_0,每个配置都有不同的特征和示例结构。数据集主要用于数学偏好相关的任务,包含代数表达式的解释和评分等内容。数据集的生成使用了distilabel工具,并提供了pipeline.yaml文件用于复现生成过程。
提供机构:
sdiazlor
原始信息汇总
数据集概述
基本信息
- 数据集大小: 小于1K
- 数据集标签: synthetic, distilabel, rlaif
配置信息
配置1: format_dpo
- 特征:
- input: 字符串
- model_names: 字符串序列
- instructions: 字符串序列
- instruction: 字符串
- generations: 字符串序列
- model_name: 字符串
- ratings: 整数序列
- rationales: 字符串序列
- prompt: 字符串
- prompt_id: 字符串
- chosen:
- content: 字符串
- role: 字符串
- chosen_rating: 整数
- rejected:
- content: 字符串
- role: 字符串
- rejected_rating: 整数
- 数据分割:
- train: 50个样本,348669字节
- 下载大小: 181938字节
- 数据集大小: 348669字节
配置2: preference_to_argilla_0
- 特征:
- input: 字符串
- model_names: 字符串序列
- instructions: 字符串序列
- instruction: 字符串
- generations: 字符串序列
- model_name: 字符串
- ratings: 整数序列
- rationales: 字符串序列
- 数据分割:
- train: 50个样本,194937字节
- 下载大小: 91271字节
- 数据集大小: 194937字节
数据文件
- format_dpo:
- train: format_dpo/train-*
- preference_to_argilla_0:
- train: preference_to_argilla_0/train-*
搜集汇总
数据集介绍
背景与挑战
背景概述
这是一个名为'math-preference-dataset'的小规模合成数据集,包含100行数据,专为数学领域的偏好学习任务设计。数据集涵盖代数表达式、线性方程、二次方程等多个数学主题,每个示例包含由不同模型生成的回答、人工评分(1-5分)和评分理由,并组织为偏好对格式,适用于直接偏好优化(DPO)等对齐方法。数据集使用distilabel工具生成,旨在训练和评估语言模型在数学内容上的偏好对齐能力。
以上内容由遇见数据集搜集并总结生成


