Sirat-tiny
收藏Hugging Face2026-05-03 更新2026-05-04 收录
下载链接:
https://huggingface.co/datasets/tCorp-Startup/Sirat-tiny
下载链接
链接失效反馈官方服务:
资源简介:
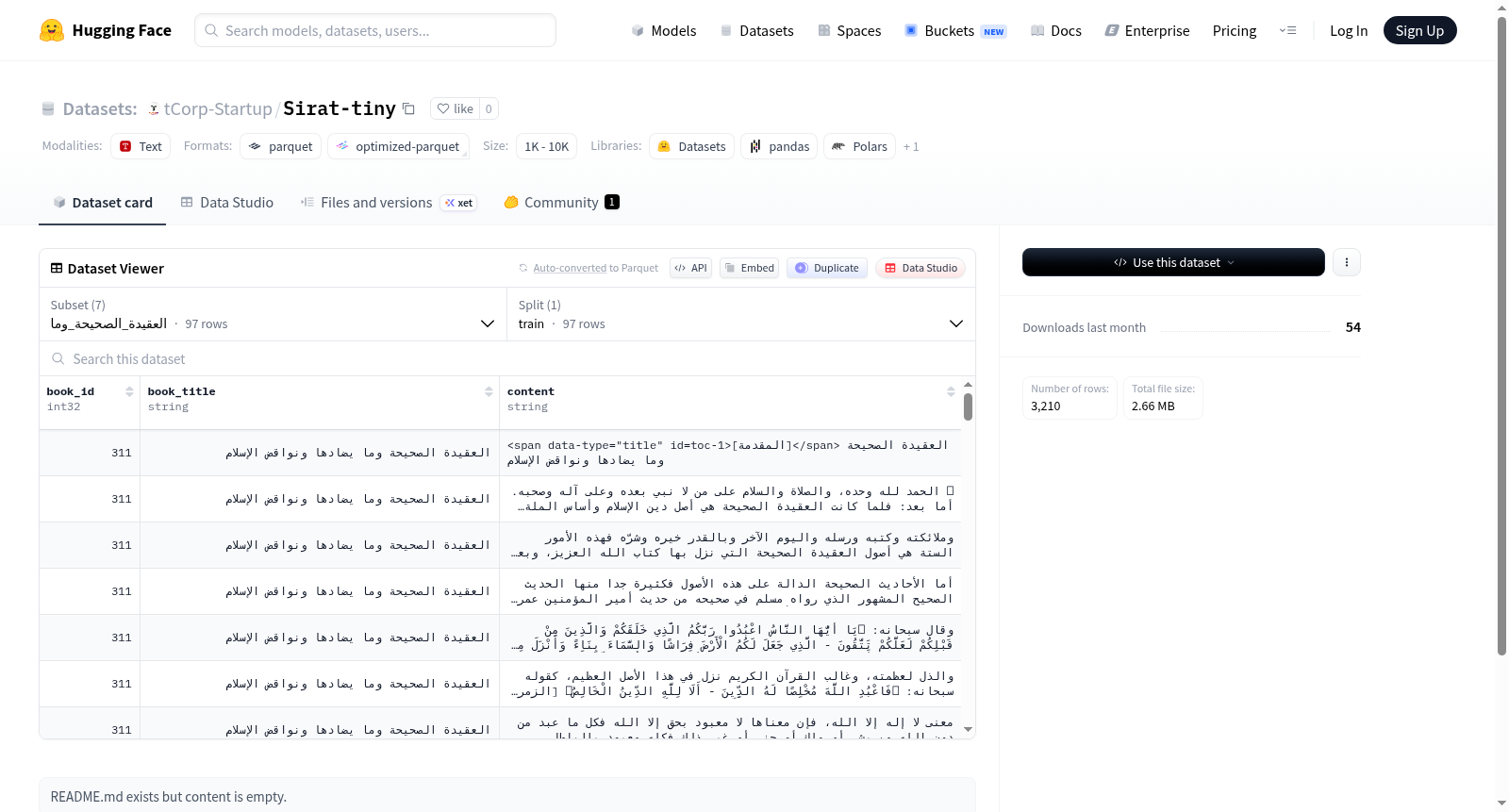
该数据集包含多个阿拉伯语伊斯兰教义文本的配置,每个配置代表不同的宗教著作。数据集结构包含三个主要字段:book_id(书籍ID,int32类型)、book_title(书籍标题,字符串类型)和content(内容,字符串类型)。各配置的数据规模差异较大,训练集样本数量从97到1820不等,数据体积从84.9KB到4.07MB不等。值得注意的是,شفاء_العليل_في配置显示为空数据集(0字节,0样本)。从阿拉伯语标题推断,这些文本可能涉及伊斯兰教义、信仰理论等相关内容,适用于阿拉伯语自然语言处理、宗教文本分析等研究领域。
创建时间:
2026-04-21
原始信息汇总
数据集概述:Sirat-tiny
数据集页面地址: https://huggingface.co/datasets/tCorp-Startup/Sirat-tiny
数据集简介: 该数据集名为 Sirat-tiny,包含多个子集(config),每个子集对应一本阿拉伯语宗教书籍的文本内容。所有子集结构一致,用于文本训练。
数据集结构
每个子集(config)包含以下三个字段:
book_id(int32): 书籍的唯一标识符。book_title(string): 书籍的标题。content(string): 书籍的正文内容。
每个子集仅包含一个 train 划分(split)。
子集详情
| 子集名称 (config_name) | 总数据量 (bytes) | 样本数 | 下载大小 |
|---|---|---|---|
| العقيدة_الصحيحة_وما | 134,849 | 97 | 37,504 |
| تحقيق_الإيمان_لابن | 84,931 | 335 | 18,081 |
| جامع_الورع_وقامع | 1,537,796 | 571 | 386,020 |
| دفع_دعوى_المعارض | 4,077,041 | 1,820 | 1,972,800 |
| شفاء_العليل_في | 0 | 0 | 1,068 |
| عقيدة_الإيمان_بالقضاء | 374,984 | 140 | 103,733 |
| عقيدة_الإيمان_باليوم | 501,790 | 247 | 127,821 |
关键信息
- 语言: 数据集内容为阿拉伯语。
- 主题: 涉及伊斯兰教义、信仰、辩论等宗教文本。
- 数据规模: 共7个子集,总计约6.7 MB(数据集大小),包含约3,210个样本。
- 使用场景: 适用于阿拉伯语宗教文本的模型训练、文本分析等自然语言处理任务。
搜集汇总
数据集介绍
构建方式
Sirat-tiny数据集的构建立足于伊斯兰教义学领域的经典文献,旨在为阿拉伯语宗教文本的自然语言处理研究提供结构化语料资源。该数据集收录了七部关于伊斯兰信仰、教义辨析及修行伦理的著作,包括《正确的信仰及其对立面》与《伊本·艾比·哈提姆的信仰实现》等。每部著作被独立划分为一个配置(config),数据以书号(book_id)、书名(book_title)与正文(content)三字段形式组织,且所有配置均仅提供训练集(train split),便于聚焦于文本的语义学习与模型预训练。
特点
该数据集的核心特点在于其领域专精性与多源文本的异构集成。所有内容均源自伊斯兰古典学术著作,文本语言严谨且富含宗教术语,为高精度语义分析带来了独特挑战。不同配置间的样本数量与数据规模差异显著,如《شفاء_العليل_في》的样本数为零,而《دفع_دعوى_المعارض》则包含1820个样本与约4MB数据量,这种非均衡性为研究模型在稀疏数据场景下的适应性提供了绝佳测试环境。此外,每个配置的标题均采用阿拉伯语罗马化转写,有助于国际研究者索引与引用。
使用方法
使用Sirat-tiny数据集时,用户可通过Hugging Face Datasets库按配置名称加载对应子集,例如调用load_dataset('Sirat-tiny', 'دفع_دعوى_المعارض')即可获取该著作的训练数据。每个样本均可直接通过键值访问book_id、book_title和content字段,其中content字段为完整的阿拉伯语文本段落,适合用于语言建模、文本分类或主题抽取等任务。研究者可基于各配置的数据规模与内容主题,灵活构建跨著作的对比实验或混合训练集,以提升模型在宗教典籍理解上的泛化能力。
背景与挑战
背景概述
Sirat-tiny是一个专注于阿拉伯语伊斯兰经典文献的数字数据集,由服务于低资源语言自然语言处理领域的研究人员构建。该数据集以多卷宗形式收录了包括《العقيدة الصحيحة》、《تحقيق الإيمان》等在内的七部宗教典籍的文本内容,涵盖信仰、律法、伦理等核心主题,总样本数逾三千条,文本以原始阿拉伯语呈现,未经过度归一化处理,旨在为伊斯兰文献的机器阅读与语义分析提供基础资源。数据集创建于近期,其发布标志着面向阿拉伯语古典文本的细粒度语料库建设迈出重要一步,为后续开展经文检索、教义对齐、作者身份识别等任务奠定了数据基础,对低资源语境下的宗教文本数字化研究具有示范意义。
当前挑战
该数据集所面临的挑战首先根植于领域问题本身——阿拉伯语伊斯兰经典文献以富含形态变化、词汇歧义和复杂句法结构著称,加之文献中大量使用特定宗教术语与古语用法,对词形还原、语义解析等自然语言处理任务形成天然障碍。在构建过程中,挑战尤为显著:原始文献多为手写扫描本或格式混乱的电子文档,需耗费大量精力进行数字化转写与清洗;文本的章节划分、段落拆解缺乏统一标准,导致数据切分需依赖人工判读;部分卷宗(如《شفاء العليل》)样本数为零,暴露了资源获取的不完整性,使得模型在稀疏数据下的泛化能力面临严峻考验。
常用场景
经典使用场景
Sirat-tiny数据集涵盖了多部伊斯兰教义典籍的文本片段,包括《正确信仰及其对立面》、《伊本·信仰实现论》等核心著作,在宗教文本数字化与自然语言处理领域具有重要价值。该数据集最经典的使用场景是作为阿拉伯语伊斯兰文献的语料库,用于训练和评估面向古典阿拉伯文的语言模型。研究者可借助这些结构化的书籍内容,开展文本分类、主题建模以及跨典籍的语义关联分析,尤其适合探究伊斯兰教义中信仰、美德与法律等概念的上下文演化规律。
实际应用
在实际应用中,Sirat-tiny数据集可赋能智能问答系统与宗教知识图谱的构建。基于其内容的语义嵌入,开发者能够打造面向伊斯兰教徒的数字助手,提供教义查询、典籍引用验证等服务。此外,该数据还可用于古籍文本的自动校对与版本比对工具,帮助研究机构高效整理和保存珍贵手稿,同时为跨语言翻译模型提供对齐语料,促进伊斯兰文化在全球范围内的传播与理解。
衍生相关工作
围绕Sirat-tiny数据集,已衍生出一系列经典工作,包括基于该语料训练的古阿拉伯语词嵌入模型(如阿拉伯语BERT变体)、面向宗教文本的迁移学习框架,以及针对典籍中特定逻辑结构的信息抽取系统。这些工作进一步催生了多语言宗教语料库的构建规范、低资源语言的序列标注基准,并推动了将历史语言学与深度神经网络相结合的跨学科研究,形成了从数据标注到模型评估的完整学术生态。
以上内容由遇见数据集搜集并总结生成


