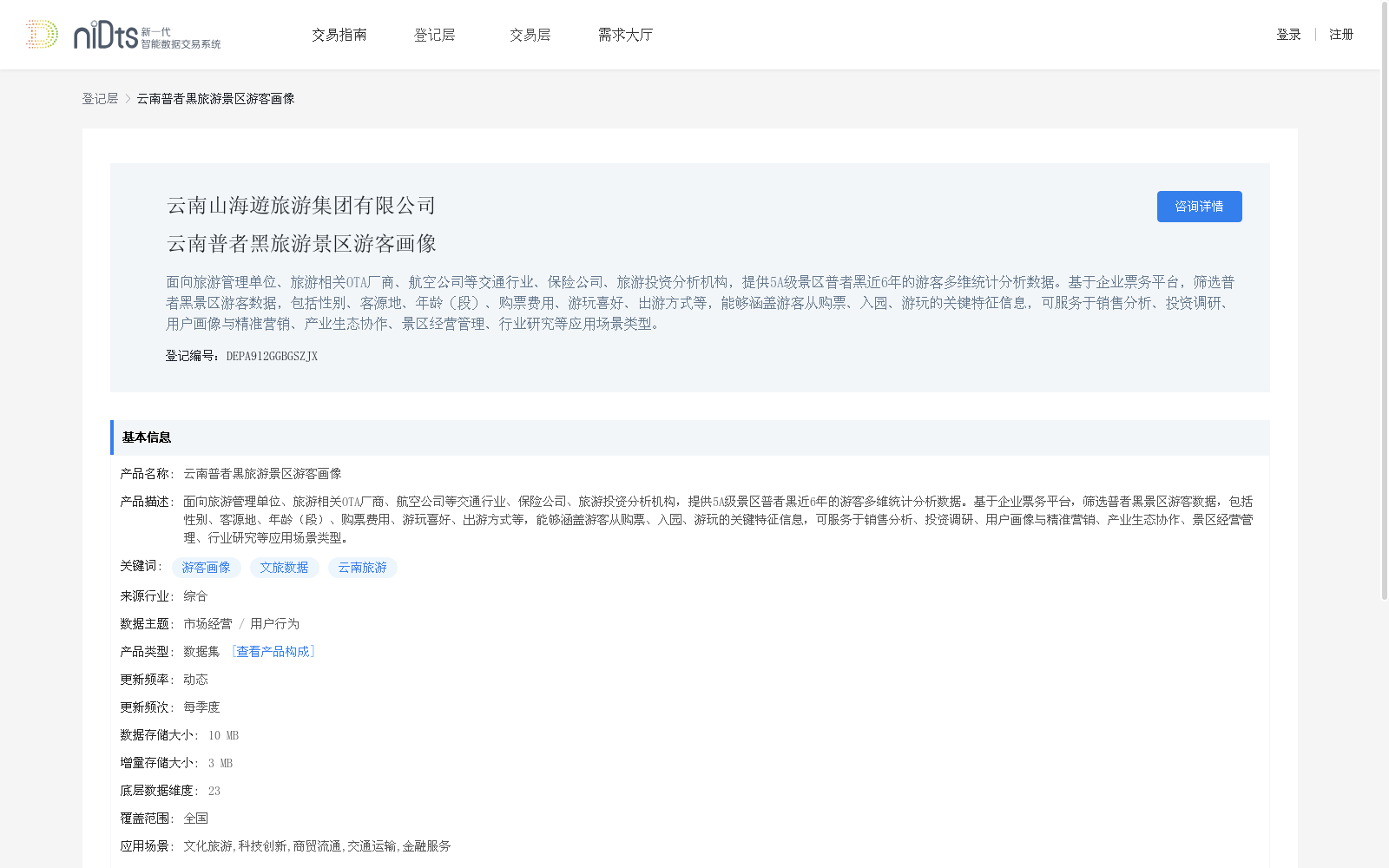
云南普者黑旅游景区游客画像
收藏上海数据交易所2024-12-19 更新2026-03-21 收录
下载链接:
https://nidts.chinadep.com/reg-hall/product-detail?id=5377
下载链接
链接失效反馈官方服务:
资源简介:
面向旅游管理单位、旅游相关OTA厂商、航空公司等交通行业、保险公司、旅游投资分析机构,提供5A级景区普者黑近6年的游客多维统计分析数据。基于企业票务平台,筛选普者黑景区游客数据,包括性别、客源地、年龄(段)、购票费用、游玩喜好、出游方式等,能够涵盖游客从购票、入园、游玩的关键特征信息,可服务于销售分析、投资调研、用户画像与精准营销、产业生态协作、景区经营管理、行业研究等应用场景类型。
This dataset provides multi-dimensional statistical analysis data of tourists to the 5A-level scenic spot Puzhehei over the past six years, targeting tourism management authorities, tourism-related OTA vendors, transportation industries such as airlines, insurance companies, and tourism investment analysis institutions. Based on enterprise ticketing platforms, the data is filtered from the tourist records of Puzhehei Scenic Area, covering key characteristic information of tourists throughout their travel process including ticket purchase, park entry and sightseeing, such as gender, tourist origin, age group, ticket purchase cost, sightseeing preferences, travel modes and more. It can support a wide range of application scenarios including sales analysis, investment research, user profiling and precision marketing, industrial ecosystem collaboration, scenic area operation management, and industry research.
提供机构:
云南山海遊旅游集团有限公司
创建时间:
2024-12-19
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集提供云南普者黑旅游景区近6年的游客多维统计分析数据,涵盖性别、客源地、年龄(段)、购票费用、游玩喜好、出游方式等关键特征信息,适用于销售分析、投资调研、用户画像与精准营销等多种应用场景。
以上内容由遇见数据集搜集并总结生成


