uzbek-speech-corpus
收藏Hugging Face2025-01-24 更新2025-01-25 收录
下载链接:
https://huggingface.co/datasets/murodbek/uzbek-speech-corpus
下载链接
链接失效反馈官方服务:
资源简介:
乌兹别克语语音语料库(USC)是由ISSAI和塔什干信息技术大学计算机系统系图像与语音处理实验室合作开发的。该语料库包含958个不同说话者的105小时转录音频。为确保高质量,语料库经过母语者的手动检查。USC主要用于自动语音识别(ASR),但也适用于语音合成和语音翻译等其他任务。据我们所知,USC是第一个在Creative Commons Attribution 4.0 International许可下开放给学术和商业用途的乌兹别克语语音语料库。我们期望USC将成为乌兹别克语ASR研究的基准数据集,并为语音研究社区提供宝贵的资源。
The Uzbek Speech Corpus (USC) was developed jointly by ISSAI and the Image and Speech Processing Laboratory of the Department of Computer Systems, Tashkent University of Information Technologies. This corpus contains 105 hours of transcribed audio from 958 distinct speakers. To ensure high quality, the corpus has been manually verified by native speakers. USC is primarily intended for automatic speech recognition (ASR), but also supports other tasks such as speech synthesis and speech translation. To the best of our knowledge, USC is the first Uzbek speech corpus made available for both academic and commercial use under the Creative Commons Attribution 4.0 International license. We anticipate that USC will serve as a benchmark dataset for Uzbek ASR research and provide a valuable resource for the speech research community.
创建时间:
2025-01-23
搜集汇总
数据集介绍
构建方式
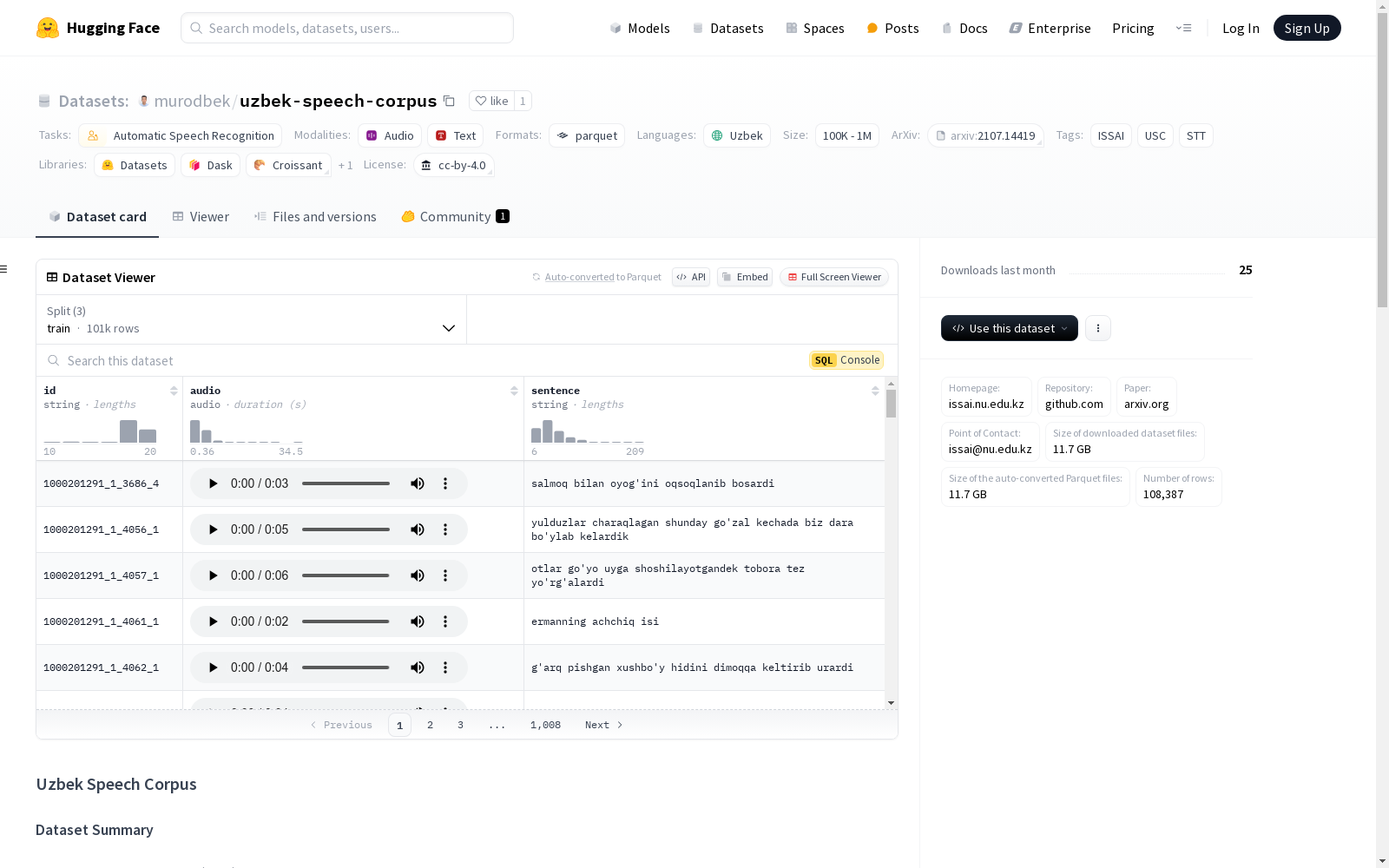
Uzbek Speech Corpus(USC)数据集由ISSAI与塔什干信息技术大学计算机系统系的图像与语音处理实验室合作开发。该数据集包含958位不同说话者的105小时转录音频,涵盖了乌兹别克语的广泛语音样本。为确保数据质量,所有音频均经过母语者的手动校对。数据集的构建过程严格遵循学术标准,旨在为自动语音识别(ASR)任务提供高质量的训练和测试资源。
特点
Uzbek Speech Corpus数据集以其多样性和高质量著称。数据集包含100,767条训练样本、3,783条验证样本和3,837条测试样本,总时长约105小时。数据字段包括音频ID、音频文件及其对应的标准化文本。此外,数据集涵盖了879位训练说话者、41位验证说话者和38位测试说话者,确保了说话者多样性。该数据集还提供了丰富的词汇覆盖,包含63,100个独特词汇,为乌兹别克语语音研究提供了坚实的基础。
使用方法
Uzbek Speech Corpus数据集主要用于自动语音识别(ASR)任务,也可用于语音合成和语音翻译等语音相关研究。用户可通过HuggingFace平台轻松访问该数据集,并利用其提供的训练、验证和测试集进行模型训练与评估。数据集的音频文件以标准格式存储,文本字段经过标准化处理,便于直接应用于深度学习框架。此外,用户可参考相关论文和GitHub仓库获取更多技术细节和使用示例。
背景与挑战
背景概述
Uzbek Speech Corpus (USC) 是由ISSAI与塔什干信息技术大学计算机系统系图像与语音处理实验室合作开发的首个开源乌兹别克语语音语料库。该数据集于2021年发布,包含来自958位不同说话者的105小时转录音频数据,旨在推动乌兹别克语自动语音识别(ASR)研究的发展。USC不仅为ASR任务提供了高质量的训练数据,还可用于语音合成、语音翻译等相关任务。其发布填补了乌兹别克语语音数据资源的空白,为学术界和工业界提供了重要的研究基础。
当前挑战
USC数据集在构建过程中面临多重挑战。首先,乌兹别克语作为一种资源稀缺语言,缺乏高质量的语音数据,数据收集与标注过程需依赖大量人工参与,以确保音频与文本的准确对齐。其次,数据集的多样性与代表性要求涵盖不同地区、年龄和性别的说话者,这对数据采集的广度和深度提出了较高要求。此外,语音识别任务本身面临诸如口音差异、背景噪声干扰等技术难题,这些因素均增加了数据集的构建难度。尽管USC为乌兹别克语ASR研究提供了重要支持,但其在数据规模、领域覆盖以及模型泛化能力方面仍需进一步扩展与优化。
常用场景
经典使用场景
Uzbek Speech Corpus(USC)作为乌兹别克语语音识别领域的重要资源,广泛应用于自动语音识别(ASR)任务中。该数据集包含105小时的乌兹别克语语音数据,涵盖了958位不同说话者的语音样本,经过母语者的严格校对,确保了数据的高质量。研究者通常利用该数据集训练和评估ASR模型,以提升乌兹别克语语音识别的准确性和鲁棒性。此外,USC还可用于语音合成、语音翻译等相关任务,为乌兹别克语的自然语言处理研究提供了坚实的基础。
解决学术问题
Uzbek Speech Corpus解决了乌兹别克语语音识别研究中数据稀缺的问题。作为首个开源的乌兹别克语语音数据集,USC填补了该领域的研究空白,为学术界和工业界提供了标准化的基准数据。通过该数据集,研究者能够开发更精确的语音识别模型,探索乌兹别克语的语言特性,并推动低资源语言的自然语言处理技术发展。USC的发布不仅促进了乌兹别克语语音技术的进步,还为其他低资源语言的语音研究提供了可借鉴的范例。
衍生相关工作
Uzbek Speech Corpus的发布催生了一系列相关研究工作。例如,基于该数据集,研究者开发了多种乌兹别克语语音识别模型,并在公开的基准测试中取得了显著进展。此外,USC还被用于探索低资源语言的语音合成技术,推动了乌兹别克语语音生成模型的发展。一些研究还利用USC进行多语言语音识别系统的开发,将乌兹别克语与其他语言结合,提升了多语言语音技术的通用性和适应性。这些工作进一步拓展了USC的应用范围,为乌兹别克语语音技术的未来发展奠定了基础。
以上内容由遇见数据集搜集并总结生成


