dreamlip_long_captions
收藏Hugging Face2024-08-26 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/qidouxiong619/dreamlip_long_captions
下载链接
链接失效反馈官方服务:
资源简介:
DreamLIP-30M是一个包含约3000万图像注释的数据集,这些注释是详细的长期描述。与其他合成图像标题注释的精心策划风格不同,DreamLIP-30M利用预训练的多模态大型语言模型来获取平均长度为247的详细描述。这些详细描述是通过询问ShareGPT4V/InstructBLIP/LLava1.5模型“详细描述图像”的问题生成的。同时,我们还通过提示“用一句话描述图像”来提供生成的简短标题。详细的长期描述对答案的多样性影响很小,因此我们可以为每张图像获得全面的标题。
DreamLIP-30M is a dataset comprising approximately 30 million image annotations, which consist of detailed long-form descriptions. In contrast to the meticulously curated style of synthetic image caption annotations employed in existing datasets, DreamLIP-30M leverages pre-trained multimodal large language models to generate detailed descriptions with an average length of 247. These detailed descriptions are produced by using the prompt "Please describe the image in detail" to query models including ShareGPT4V, InstructBLIP, and LLava1.5. Meanwhile, we also generate concise captions via the prompt "Please describe the image in one sentence". Since the detailed long-form descriptions have minimal impact on the diversity of the generated responses, we can obtain comprehensive captions for each image.
创建时间:
2024-08-24
原始信息汇总
数据集卡片 DreamLIP-30M
数据集描述
数据集概述
DreamLIP-Long-Captions 是一个包含约 30M 图像注释的数据集,即详细的长期描述。与其他合成图像标题注释的精选风格不同,DreamLIP-30M 利用预训练的多模态大型语言模型来获取平均长度为 247 的详细描述。更确切地说,详细的描述是通过向 ShareGPT4V/InstructBLIP/LLava1.5 提问“详细描述图像”而生成的。同时,我们还通过提示“用一句话描述图像”来提供生成的简短标题。详细长期描述的问题对答案的多样性影响很小,因此我们可以获得每个图像的全面描述。
附加信息
数据集策展人
Kecheng Zheng, Yifei Zhang, Wei Wu, Fan Lu, Shuailei Ma, Xin Jin, Wei Chen 和 Yujun Shen。
许可信息
我们根据标准的 Creative Common CC-BY-4.0 许可证分发带有长期描述的图像 URL。单个图像受其自身版权保护。
引用信息
bibtex @inproceedings{DreamLIP, title={DreamLIP: Language-Image Pre-training with Long Captions}, author={Zheng, Kecheng and Zhang, Yifei and Wu, Wei and Lu, Fan and Ma, Shuailei and Jin, Xin and Chen, Wei and Shen, Yujun}, booktitle={ECCV}, year={2024} }
搜集汇总
数据集介绍
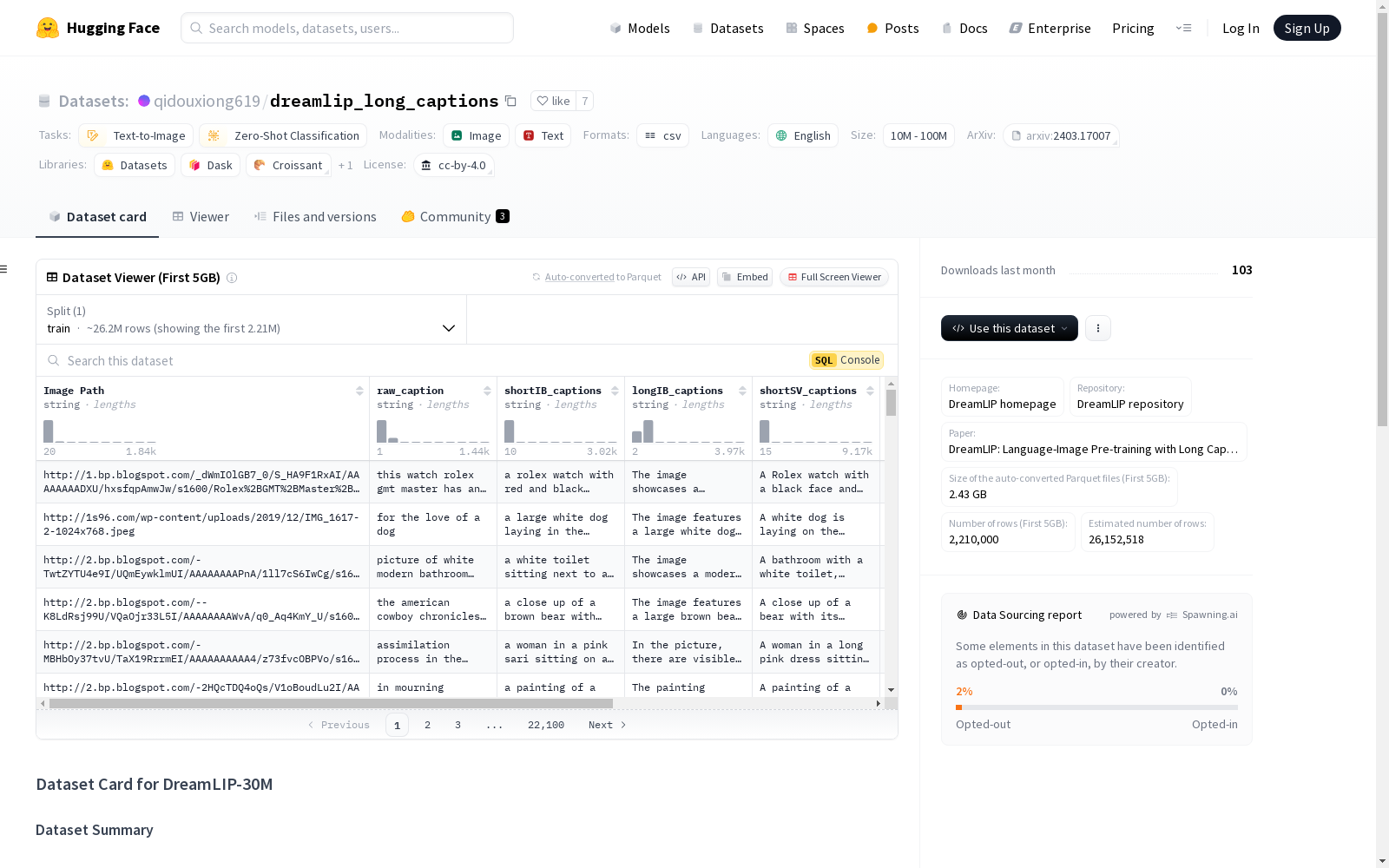
构建方式
DreamLIP-Long-Captions数据集的构建基于多模态大语言模型的应用,通过预训练的模型如ShareGPT4V、InstructBLIP和LLava1.5生成详细的图像描述。具体方法是通过向这些模型提出“详细描述这张图片”的问题,从而获得平均长度为247个字符的详细描述。此外,数据集还提供了通过提示“用一句话描述这张图片”生成的简短描述。这种构建方式确保了描述的多样性和全面性。
特点
DreamLIP-Long-Captions数据集的特点在于其包含约3000万条图像注释,这些注释以详细的长描述为主,平均长度达到247个字符。与传统的合成图像注释相比,这些描述更为详尽和丰富,能够提供更全面的图像理解。数据集还提供了简短描述,增加了使用的灵活性。这种结构使得数据集在文本到图像生成和零样本分类等任务中具有广泛的应用潜力。
使用方法
DreamLIP-Long-Captions数据集的使用方法主要围绕其提供的详细和简短的图像描述。研究人员和开发者可以利用这些描述进行文本到图像的生成任务,或者用于训练和评估零样本分类模型。数据集的长描述特别适合于需要深度图像理解的应用场景,而简短描述则适用于快速图像标注和检索。通过结合使用这两种描述,可以更全面地探索图像与文本之间的关系。
背景与挑战
背景概述
DreamLIP-Long-Captions数据集由Kecheng Zheng等人于2024年创建,旨在通过大规模图像标注推动语言-图像预训练领域的研究。该数据集包含约3000万条图像标注,每条标注均为详细的长描述,平均长度达247个词。与传统的合成图像标注不同,DreamLIP-30M利用预训练的多模态大语言模型(如ShareGPT4V、InstructBLIP和LLava1.5)生成详细描述,显著提升了图像描述的丰富性和多样性。该数据集的研究成果已在ECCV 2024会议上发表,为图像理解、文本生成及多模态学习等任务提供了重要支持。
当前挑战
DreamLIP-Long-Captions数据集在构建过程中面临多重挑战。首先,生成高质量的长描述需要依赖先进的多模态大语言模型,这对计算资源和模型性能提出了极高要求。其次,确保描述的一致性和准确性是一个复杂问题,尤其是在处理大规模数据时,如何避免生成重复或冗余的描述成为关键难点。此外,数据集的使用场景主要集中在零样本分类和文本到图像生成任务中,如何在这些任务中充分发挥长描述的优势仍需进一步探索。最后,尽管数据集提供了丰富的标注信息,但其对图像版权问题的处理仍需谨慎,以确保数据的合法性和合规性。
常用场景
经典使用场景
DreamLIP-Long-Captions数据集在文本到图像生成领域具有广泛的应用。其核心价值在于提供了大量详细的图像描述,这些描述通过多模态大语言模型生成,平均长度达到247个字符。这种长描述不仅丰富了图像的内容表达,还为模型训练提供了更为细致的语义信息。在零样本分类任务中,该数据集能够帮助模型更好地理解图像与文本之间的复杂关系,从而提升分类的准确性。
实际应用
在实际应用中,DreamLIP-Long-Captions数据集为图像检索、自动图像标注、虚拟现实等场景提供了重要支持。例如,在图像检索系统中,详细的图像描述能够帮助用户更精准地找到所需图像;在虚拟现实领域,长描述可以为场景生成提供更为丰富的语义信息,从而提升用户体验。这些应用场景充分展示了该数据集的实际价值。
衍生相关工作
基于DreamLIP-Long-Captions数据集,研究者们开展了一系列经典工作。例如,利用该数据集进行多模态预训练,显著提升了模型在图像描述生成和零样本分类任务中的表现。此外,该数据集还启发了更多关于长描述生成的研究,推动了多模态大语言模型在图像理解领域的应用。这些工作不仅丰富了学术研究的成果,也为实际应用提供了更多可能性。
以上内容由遇见数据集搜集并总结生成


