Full-Duplex-Bench-v3 (FDB-v3)
收藏arXiv2026-04-07 更新2026-04-07 收录
下载链接:
https://daniellin94144.github.io/FDB-v3-demo/
下载链接
链接失效反馈官方服务:
资源简介:
Full-Duplex-Bench-v3(FDB-v3)是由台湾大学和英伟达联合创建的语音交互评估数据集,旨在测试语音代理在真实场景中的多步骤工具使用能力。该数据集包含100条真实人类语音记录,覆盖了五种不同的语言不流畅现象(如填充词、停顿、犹豫等),并标注了四种任务领域的多步骤API调用场景。数据来源于12名不同背景的说话者在非受控环境下的自然语音采集,通过系统性的难度分级和确定性API设计确保评估的可靠性。该数据集主要应用于语音代理的实时交互、工具调用和状态回滚等研究领域,旨在解决语音代理在真实世界应用中面临的语言不流畅和多步骤任务执行难题。
Full-Duplex-Bench-v3 (FDB-v3) is a speech interaction evaluation dataset co-developed by National Taiwan University and NVIDIA, aiming to evaluate the multi-step tool use capabilities of speech agents in real-world scenarios. This dataset includes 100 real human speech recordings, covering five distinct types of speech disfluencies such as filled pauses, silent pauses and hesitations, and is annotated with multi-step API call scenarios across four task domains. The data is collected from natural speech of 12 speakers with diverse backgrounds in uncontrolled environments. The reliability of the evaluation is guaranteed through systematic difficulty grading and deterministic API design. This dataset is mainly applied to research fields including real-time interaction, tool invocation and state rollback of speech agents, and targets to address the challenges of speech disfluencies and multi-step task execution faced by speech agents in real-world applications.
提供机构:
台湾大学; 英伟达
创建时间:
2026-04-07
搜集汇总
数据集介绍
构建方式
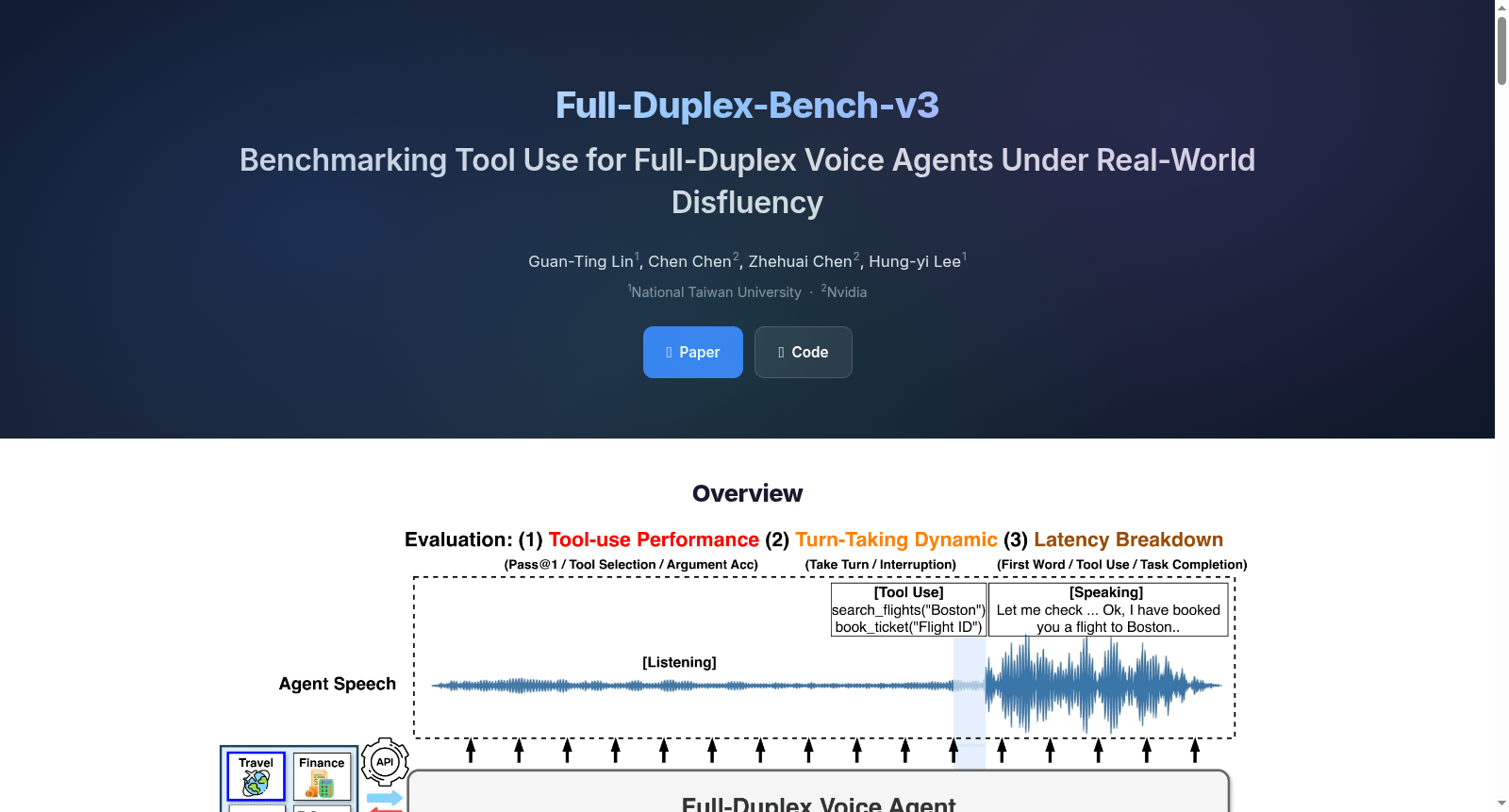
在语音智能体领域,对实时交互与多步工具调用的评估需求日益增长。Full-Duplex-Bench-v3(FDB-v3)的构建采用了系统化的方法,其核心在于采集真实人类语音数据并模拟多步骤API调用场景。数据集包含100个由12位说话者在非受控环境中录制的语音样本,覆盖了旅行与身份、金融与账单、住房与位置以及电子商务支持四个任务领域。每个语音样本均针对填充词、停顿、犹豫、错误起始和自我纠正五类不流畅现象进行了精细标注,并设计了包含易、中、难三个难度等级的测试场景,其中21个场景专门用于评估模型在意图中途变更时的状态回滚能力。通过本地执行的零延迟模拟API,该基准测试确保了评估过程不受网络波动等外部因素干扰,从而专注于模型自身的推理与交互性能。
特点
该数据集在语音智能体评估领域展现出若干鲜明特点。其首要特征在于全部采用真实人类语音,而非合成音频,这确保了评估环境贴近实际应用中的自然对话场景,包括各种口音和背景噪声。数据集系统性地标注了五类常见的不流畅现象,为模型在鲁棒性分析方面提供了细粒度的评估维度。另一个关键特点是设计了需要链式API调用的多步骤任务场景,覆盖四个不同的现实领域,并要求模型在部分场景中处理用户中途更改意图的复杂情况,从而测试其动态状态更新能力。此外,通过结合工具调用准确性、延迟和对话轮转等多维度指标,数据集提供了对语音智能体综合性能的全面评估框架。
使用方法
该数据集主要用于评估实时语音智能体在多步工具调用场景下的性能。研究人员或开发者可以将待评估的语音模型接入由LiveKit Realtime Voice Agent框架支持的测试环境中,模型将接收数据集中真实的语音流输入,并需要在交互中调用相应的模拟API来完成任务。评估过程自动进行,通过对比模型输出的工具调用序列、参数准确性以及语音响应内容与预设的确定性答案,计算包括工具选择F1分数、参数准确率、任务完成率(Pass@1)以及响应质量在内的核心指标。同时,系统会精确测量从用户语音结束到模型首次响应、首次工具调用及任务完成的关键延迟时间点,并分析模型的轮转行为与中断模式,从而全面量化其在真实不流畅语音条件下的工具使用效能与交互流畅性。
背景与挑战
背景概述
在语音智能体领域,将工具调用能力与实时对话相结合是提升实用价值的关键方向。Full-Duplex-Bench-v3(FDB-v3)由国立台湾大学与NVIDIA的研究团队于2026年提出,旨在填补现有评估体系的空白。该数据集聚焦于全双工语音代理在真实世界不流利语音条件下的多步骤工具使用性能,核心研究问题是衡量模型在自然语音交互中处理复杂API链式调用、动态意图更新与低延迟响应之间的平衡能力。通过整合完全来自真实人类音频的语料,并系统标注五种不流利类别,FDB-v3为语音代理的鲁棒性评估设立了新标准,对推动实时对话系统向更实用、更人性化的方向发展具有重要影响力。
当前挑战
FDB-v3所针对的领域挑战在于评估语音代理在真实不流利语音环境下执行多步骤工具调用的综合能力,这超越了传统的单轮对话或合成语音测试。具体构建挑战包括:第一,采集与标注真实人类语音中的不流利现象(如填充词、自我修正),需确保音频的自然性与标注的一致性;第二,设计涵盖多个任务领域且需链式API调用的复杂场景,特别是包含意图中途更改的自我修正案例,以测试模型的动态状态回滚能力;第三,在评估体系中平衡工具执行准确度、响应延迟与对话轮转动态等多维度指标,以全面反映模型在真实交互中的性能瓶颈。
常用场景
经典使用场景
在语音智能体研究领域,评估模型在真实对话环境下的工具调用能力一直面临挑战。Full-Duplex-Bench-v3(FDB-v3)的经典使用场景在于为实时全双工语音代理提供一个标准化测试平台,专门针对包含自然语言不流利现象的多步骤工具链执行任务。该数据集通过整合真实人类音频,并系统标注填充词、停顿、犹豫、错误起始和自我修正等五类不流利特征,模拟了用户在旅行预订、金融交易等实际场景中可能出现的复杂交互。研究者利用这一基准,能够全面测评语音模型在连续语音输入下的API选择准确性、状态回滚鲁棒性以及对话时序协调性,从而推动更接近人类自然交流的语音助手发展。
解决学术问题
FDB-v3主要解决了语音智能体研究中几个关键学术问题。其一,它填补了现有评估工具在真实语音与多步骤工具调用结合方面的空白,此前基准多依赖合成音频或仅关注单步动作。其二,该数据集通过引入自我修正和状态回滚场景,直接应对用户意图中途变更这一核心难题,为模型动态更新内部状态的能力提供了量化评估框架。其三,它系统考察了延迟与准确性之间的权衡关系,揭示了端到端模型与传统级联架构在实时处理中的性能差异。这些贡献使得学术界能够更精确地诊断语音代理在复杂、不完美语音输入下的失败模式,为算法优化提供了明确方向。
衍生相关工作
FDB-v3的推出,继承并拓展了Full-Duplex-Bench系列的研究脉络,同时也催生和连接了多项相关经典工作。其前代版本(v1, v1.5, v2)逐步建立了针对语音重叠、多轮对话的评估体系。而FDB-v3与同期基准如Audio MultiChallenge(专注真实语音但无工具调用)、τ-Voice和AudioCRAG(评估工具调用但使用合成音频)形成了鲜明对比与互补。该数据集的设计思想也影响了后续对语音智能体在流式处理、静默推理等行为模式的研究,为比较GPT-Realtime、Gemini Live等专有系统与Ultravox等开源模型提供了公开、可复现的基准,推动了整个领域向更严谨、更贴近现实的评估范式演进。
以上内容由遇见数据集搜集并总结生成


