IFEval_tr
收藏数据集卡片 for IFEval_tr
数据集描述
IFEval_tr 是 IFEval 数据集的土耳其语本地化版本。它包含原始数据集的人工标注和人工翻译版本,以及全新创建的条目(ID > 5000)。该数据集排除了需要模型以特定语言响应的任务,专注于土耳其语认知能力。
数据集摘要
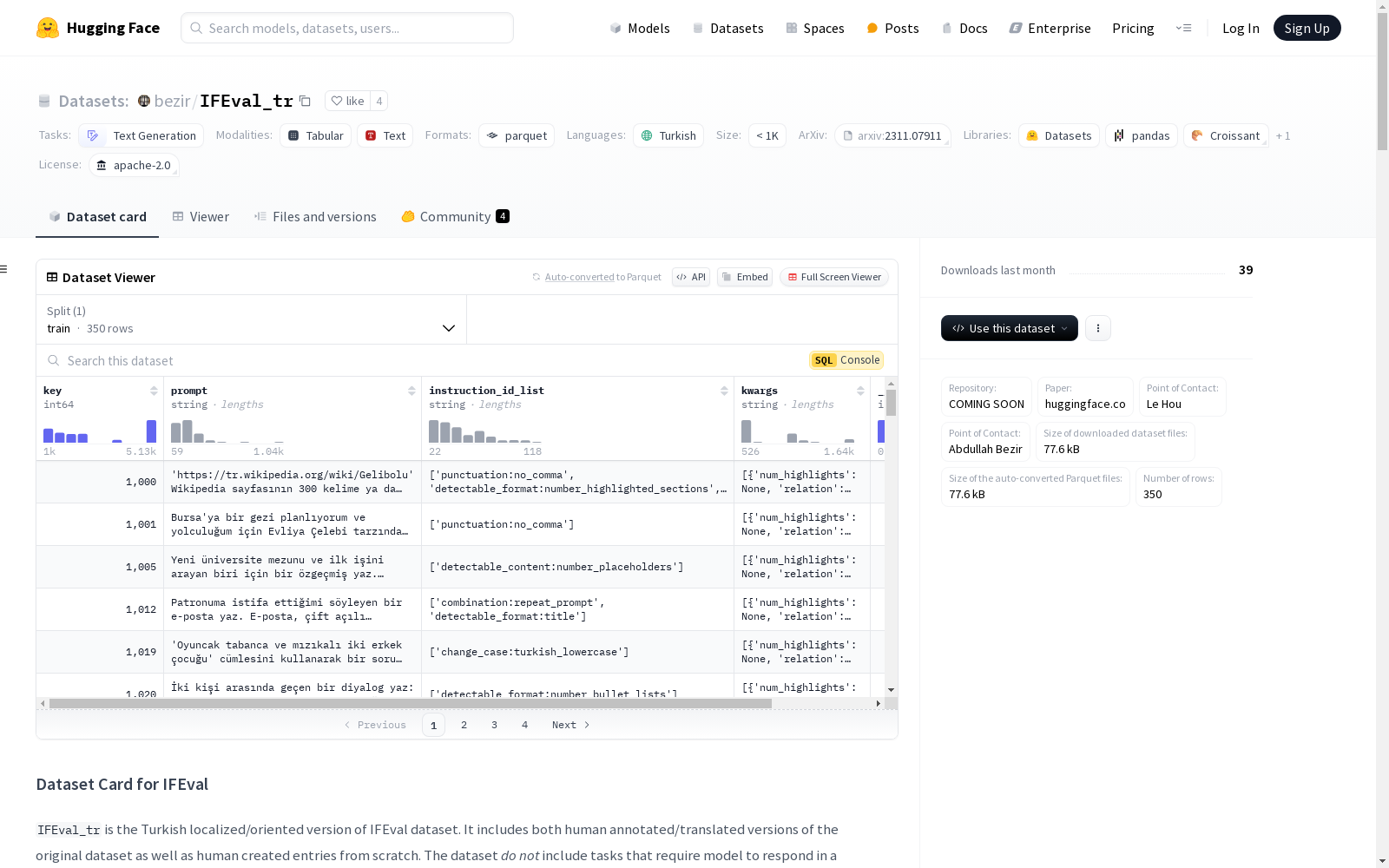
该数据集包含 350 条“可验证指令”,基于 Instruction-Following Eval (IFEval) 基准 论文中提出的方法。它包括通过启发式方法生成的可验证指令,例如“写一个超过 400 字的答案”或“在响应中至少包含单词 artificial 3 次”。
支持的任务和排行榜
IFEval-tr 数据集是具有对话能力的模型(通过指令训练)的核心测试基准,类似于原始数据集。
数据集结构
数据实例
一个 train 分割的示例如下:
json { "key": 1000, "prompt": "https://tr.wikipedia.org/wiki/Gelibolu Wikipedia sayfasının 300 kelime ya da daha uzun bir özetini yaz. Cevabında virgül kullanma ve en az 3 bölümü verdiğim örnek biçiminde vurgula. Örnek vurgu: vurgulanan bölüm 1 vurgulanan bölüm 2 vurgulanan bölüm 3.", "instruction_id_list": [ "punctuation:no_comma", "detectable_format:number_highlighted_sections", "length_constraints:number_words" ], "kwargs": [ { "num_highlights": None, "relation": None, "num_words": None, "num_placeholders": None, "prompt_to_repeat": None, "num_bullets": None, "section_spliter": None, "num_sections": None, "capital_relation": None, "capital_frequency": None, "keywords": None, "num_paragraphs": None, "language": None, "let_relation": None, "letter": None, "let_frequency": None, "end_phrase": None, "forbidden_words": None, "keyword": None, "frequency": None, "num_sentences": None, "postscript_marker": None, "first_word": None, "nth_paragraph": None }, { "num_highlights": 3, "relation": None, "num_words": None, "num_placeholders": None, "prompt_to_repeat": None, "num_bullets": None, "section_spliter": None, "num_sections": None, "capital_relation": None, "capital_frequency": None, "keywords": None, "num_paragraphs": None, "language": None, "let_relation": None, "letter": None, "let_frequency": None, "end_phrase": None, "forbidden_words": None, "keyword": None, "frequency": None, "num_sentences": None, "postscript_marker": None, "first_word": None, "nth_paragraph": None }, { "num_highlights": None, "relation": "at least", "num_words": 300, "num_placeholders": None, "prompt_to_repeat": None, "num_bullets": None, "section_spliter": None, "num_sections": None, "capital_relation": None, "capital_frequency": None, "keywords": None, "num_paragraphs": None, "language": None, "let_relation": None, "letter": None, "let_frequency": None, "end_phrase": None, "forbidden_words": None, "keyword": None, "frequency": None, "num_sentences": None, "postscript_marker": None, "first_word": None, "nth_paragraph": None } ] }
数据字段
数据字段如下:
key: 提示的唯一 ID。ID > 5000 对应于从零开始创建的条目,其他可能对应于原始数据集。prompt: 描述模型应执行的任务。instruction_id_list: 可验证指令的数组。请参阅论文中的表 1 以获取完整集合及其描述。kwargs: 用于指定instruction_id_list中每个可验证指令的参数数组。
数据分割
| train | |
|---|---|
| IFEval | 350 |
测试
测试环境是通过在 LM Evaluation Harness 仓库中更新 IFEval 任务为土耳其语来设置的。代码将很快开源。评分是 inst_level_strict_acc 和 prompt_level_strict_acc 的平均值。
IFEval-TR 排行榜
| 模型 | IFEval 土耳其语得分 |
|---|---|
| google/gemma-2-9b-it | 39.65 |
| gemma-2-2b-it | 31.06 |
| Qwen/Qwen2-7B-Instruct | 29.05 |
| meta-llama/Meta-Llama-3.1-8B-Instruct | 26.99 |
| Metin/LLaMA-3-8B-Instruct-TR-DPO | 25.47 |
| ytu-ce-cosmos/Turkish-Llama-8b-Instruct-v0.1 | 25.18 |
| mistralai/Mistral-7B-Instruct-v0.3 | 21.78 |
| VeriUS/VeriUS-LLM-8b-v0.2 | 19.73 |
| Trendyol/Trendyol-LLM-7b-chat-v1.8 | 19.26 |
许可信息
该数据集在 Apache 2.0 许可证 下提供。
引用信息
plaintext @misc{zhou2023instructionfollowingevaluationlargelanguage, title={Instruction-Following Evaluation for Large Language Models}, author={Jeffrey Zhou and Tianjian Lu and Swaroop Mishra and Siddhartha Brahma and Sujoy Basu and Yi Luan and Denny Zhou and Le Hou}, year={2023}, eprint={2311.07911}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2311.07911}, } @misc{IFEval_tr, author = {Abdullah Bezir}, title = {bezir/IFEval_tr}, year = {2024}, publisher = {Abdullah Bezir}, howpublished = {https://huggingface.co/datasets/bezir/IFEval_tr} }