embeddings-pre-training-test
收藏魔搭社区2025-12-03 更新2025-09-06 收录
下载链接:
https://modelscope.cn/datasets/lightonai/embeddings-pre-training-test
下载链接
链接失效反馈官方服务:
资源简介:
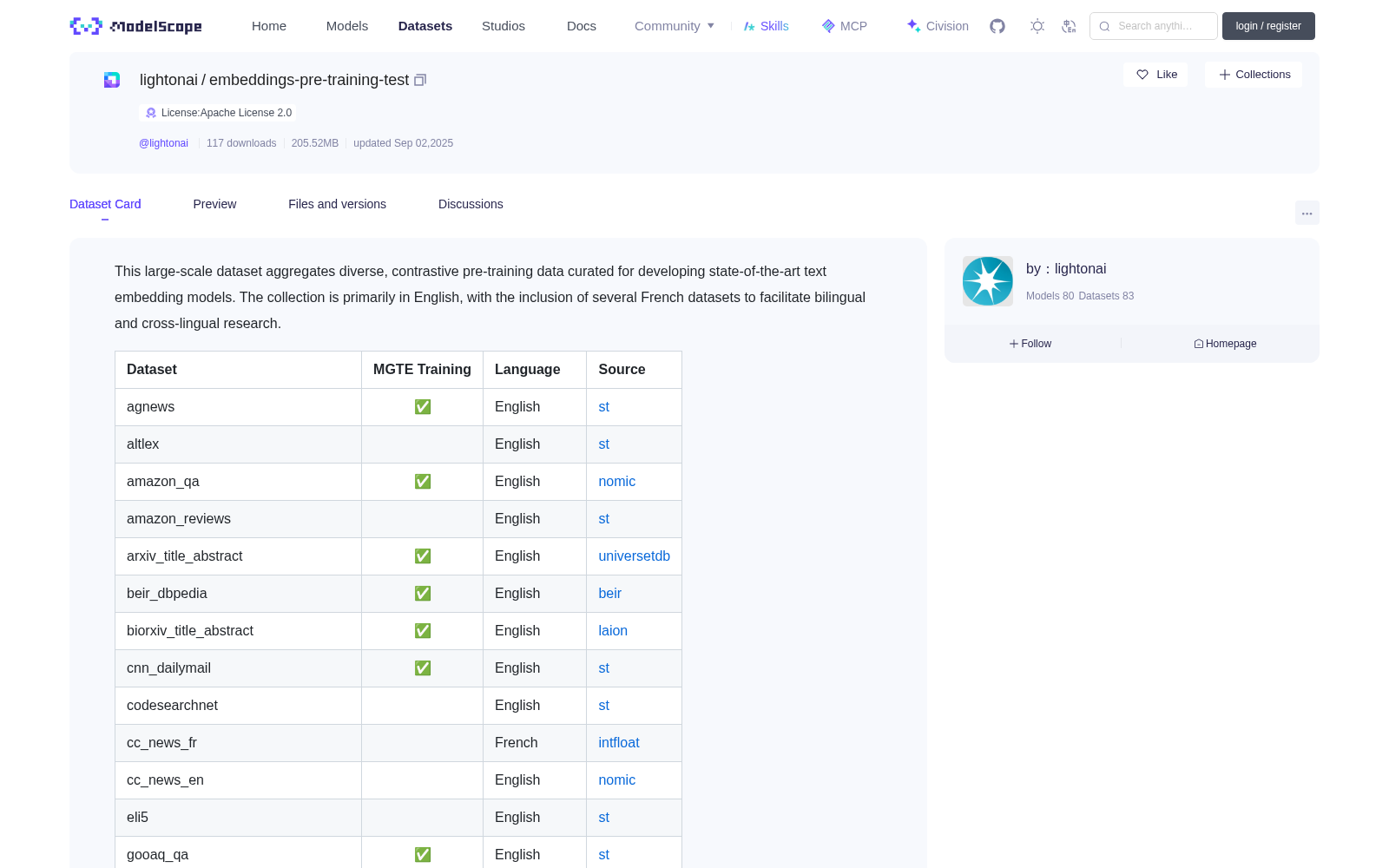
This large-scale dataset aggregates diverse, contrastive pre-training data curated for developing state-of-the-art text embedding models.
The collection is primarily in English, with the inclusion of several French datasets to facilitate bilingual and cross-lingual research.
| Dataset | MGTE Training | Language | Source |
| :---------------------------------- | :-----------: | :------------ | :----- |
| agnews | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/agnews) |
| altlex | | English | [st](https://huggingface.co/datasets/sentence-transformers/altlex) |
| amazon_qa | ✅ | English | [nomic](https://huggingface.co/datasets/nomic-ai/nomic-embed-unsupervised-data) |
| amazon_reviews | | English | [st](https://huggingface.co/datasets/sentence-transformers/amazon-reviews) |
| arxiv_title_abstract | ✅ | English | [universetdb](https://huggingface.co/datasets/UniverseTBD/arxiv-abstracts-large) |
| beir_dbpedia | ✅ | English | [beir](https://huggingface.co/datasets/BeIR/dbpedia-entity) |
| biorxiv_title_abstract | ✅ | English | [laion](https://huggingface.co/datasets/laion/biorXiv_metadata) |
| cnn_dailymail | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| codesearchnet | | English | [st](https://huggingface.co/datasets/sentence-transformers/codesearchnet) |
| cc_news_fr | | French | [intfloat](https://huggingface.co/datasets/intfloat/multilingual_cc_news) |
| cc_news_en | | English | [nomic](https://huggingface.co/datasets/nomic-ai/nomic-embed-unsupervised-data) |
| eli5 | | English | [st](https://huggingface.co/datasets/sentence-transformers/eli5) |
| gooaq_qa | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| medrxiv_title_abstract | ✅ | English | [mteb](https://huggingface.co/datasets/mteb/raw_medrxiv) |
| nllb_eng_fra | | Cross lingual | [allenai](https://huggingface.co/datasets/allenai/nllb) |
| npr | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/npr) |
| paq | | English | [st](https://huggingface.co/datasets/sentence-transformers/paq) |
| reddit | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/reddit) |
| s2orc_abstract_citation | | English | [st](https://huggingface.co/datasets/sentence-transformers/s2orc) |
| s2orc_citation_titles | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/s2orc) |
| s2orc_title_abstract | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/s2orc) |
| sentence_compression | | English | [st](https://huggingface.co/datasets/sentence-transformers/sentence-compression) |
| simplewiki | | English | [st](https://huggingface.co/datasets/sentence-transformers/simple-wiki) |
| stackexchange_body_body | | English | [st](https://huggingface.co/datasets/sentence-transformers/stackexchange-duplicates) |
| stackexchange_duplicate_questions | | English | [st](https://huggingface.co/datasets/sentence-transformers/stackexchange-duplicates) |
| stackexchange_qa | ✅ | English | [flax](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) |
| stackexchange_title_body | ✅ | English | [flax](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) |
| stackoverflow_title_body | ✅ | English | [flax](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) |
| webfaq_eng | | English | [padas-lab](https://huggingface.co/datasets/PaDaS-Lab/webfaq) |
| webfaq_fra | | French | [padas-lab](https://huggingface.co/datasets/PaDaS-Lab/webfaq) |
| wikihow | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| yahoo_answer | | English | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| yahoo_qa | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/yahoo-answers/viewer/title-answer-pair) |
| yahoo_question_body | ✅ | English | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
本大规模数据集汇聚了多样化的对比预训练数据,专为研发顶尖水平的文本嵌入模型(text embedding models)而精心甄选整理。该数据集集合以英文为主,同时纳入多套法语数据集,以支持双语及跨语言研究工作。
| 数据集名称 | MGTE训练 | 语言 | 来源 |
| :---------------------------------- | :-----------: | :------------ | :----- |
| agnews | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/agnews) |
| altlex | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/altlex) |
| amazon_qa | ✅ | 英语 | [nomic](https://huggingface.co/datasets/nomic-ai/nomic-embed-unsupervised-data) |
| amazon_reviews | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/amazon-reviews) |
| arxiv_title_abstract | ✅ | 英语 | [universetdb](https://huggingface.co/datasets/UniverseTBD/arxiv-abstracts-large) |
| beir_dbpedia | ✅ | 英语 | [beir](https://huggingface.co/datasets/BeIR/dbpedia-entity) |
| biorxiv_title_abstract | ✅ | 英语 | [laion](https://huggingface.co/datasets/laion/biorXiv_metadata) |
| cnn_dailymail | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| codesearchnet | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/codesearchnet) |
| cc_news_fr | | 法语 | [intfloat](https://huggingface.co/datasets/intfloat/multilingual_cc_news) |
| cc_news_en | | 英语 | [nomic](https://huggingface.co/datasets/nomic-ai/nomic-embed-unsupervised-data) |
| eli5 | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/eli5) |
| gooaq_qa | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| medrxiv_title_abstract | ✅ | 英语 | [mteb](https://huggingface.co/datasets/mteb/raw_medrxiv) |
| nllb_eng_fra | | 跨语言 | [allenai](https://huggingface.co/datasets/allenai/nllb) |
| npr | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/npr) |
| paq | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/paq) |
| reddit | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/reddit) |
| s2orc_abstract_citation | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/s2orc) |
| s2orc_citation_titles | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/s2orc) |
| s2orc_title_abstract | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/s2orc) |
| sentence_compression | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/sentence-compression) |
| simplewiki | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/simple-wiki) |
| stackexchange_body_body | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/stackexchange-duplicates) |
| stackexchange_duplicate_questions | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/stackexchange-duplicates) |
| stackexchange_qa | ✅ | 英语 | [flax](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) |
| stackexchange_title_body | ✅ | 英语 | [flax](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) |
| stackoverflow_title_body | ✅ | 英语 | [flax](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) |
| webfaq_eng | | 英语 | [padas-lab](https://huggingface.co/datasets/PaDaS-Lab/webfaq) |
| webfaq_fra | | 法语 | [padas-lab](https://huggingface.co/datasets/PaDaS-Lab/webfaq) |
| wikihow | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| yahoo_answer | | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
| yahoo_qa | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/yahoo-answers/viewer/title-answer-pair) |
| yahoo_question_body | ✅ | 英语 | [st](https://huggingface.co/datasets/sentence-transformers/embedding-training-data) |
提供机构:
maas创建时间:
2025-08-27
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个大规模、多样化的对比预训练数据集合,旨在支持先进文本嵌入模型的开发。它主要以英语为主,同时包含法语数据,以促进双语和跨语言研究。数据集由多个来源的子集构成,覆盖了新闻、学术、问答等多种文本类型。
以上内容由遇见数据集搜集并总结生成


