SMK-image-text
收藏Hugging Face2025-12-23 更新2025-12-24 收录
下载链接:
https://huggingface.co/datasets/V4ldeLund/SMK-image-text
下载链接
链接失效反馈官方服务:
资源简介:
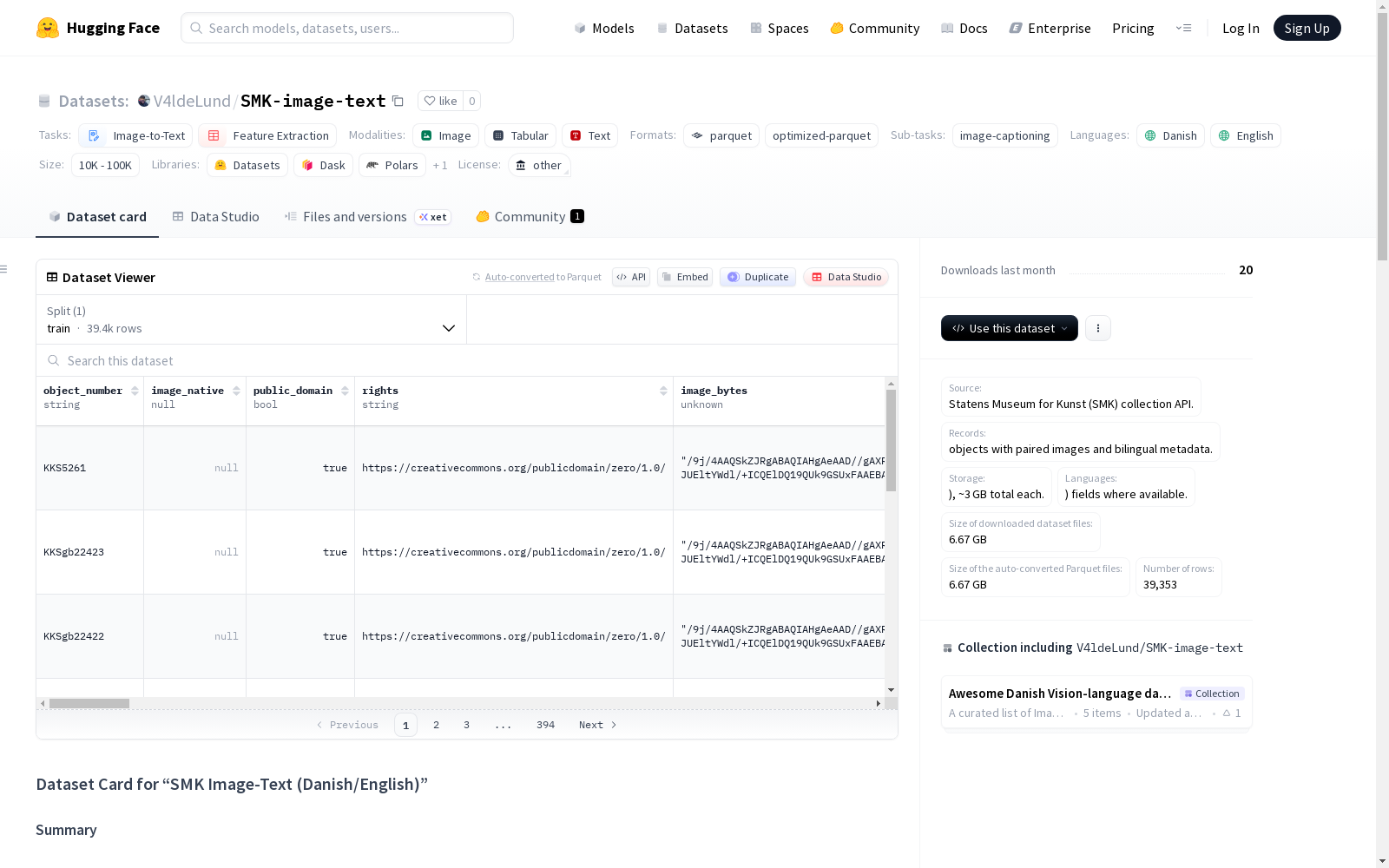
SMK图像-文本数据集(丹麦语/英语)来源于Statens Museum for Kunst(SMK)收藏API,包含39,353个带有配对图像和双语元数据的对象。数据集存储为2个Parquet分片,每个约3GB。支持丹麦语(da)和英语(en)字段。每条记录对应一个SMK收藏对象,包含原始图像字节、缩略图、基本图像统计信息(宽度/高度/大小、熵、对比度等)、丹麦语和英语的对象元数据(标题、对象名称、艺术家/创作者、生产日期、技术、材料、铭文、标签、文档参考等)以及权利信息(公共领域标志和每个对象的权利文本)。数据集适用于图像字幕生成、图像文本检索、元数据补全、博物馆收藏探索、多语言视觉语言建模等用途。
创建时间:
2025-12-22
原始信息汇总
SMK Image-Text (Danish/English) 数据集概述
基本信息
- 数据集名称: SMK Image-Text (Danish/English)
- 发布平台: Hugging Face
- 维护者: Vladimir Salnikov (v4ldesalnikov@gmail.com)
- 许可证: other
- 语言: 丹麦语 (da)、英语 (en)
- 数据规模: 10K<n<100K
- 任务类别: 图像到文本 (image-to-text)、特征提取 (feature-extraction)
- 具体任务: 图像描述生成 (image-captioning)
数据来源与规模
- 来源: Statens Museum for Kunst (SMK) 收藏品 API。
- 记录数量: 39,353 个对象,每个对象包含配对的图像和双语元数据。
- 存储格式: 数据集在 Hub 上存储为 2 个 Parquet 分片 (
data/train-*.parquet),每个约 3 GB。
数据结构与内容
每个数据行对应一个 SMK 收藏品对象,包含以下关键字段:
图像信息
image_bytes(binary): 完整分辨率的图像字节流,可使用datasets.Image()解码。- 缩略图及基本图像属性:
image_thumbnail(URL)、image_width、image_height、image_size、image_orientation、image_cropped、colors、suggested_bg_color、entropy、contrast、brightness、saturation、colortemp。
对象标识与基本信息
object_number、id、object_url、frontend_url、responsible_department。
日期与尺寸
acquisition_date、acquisition_date_precision。- 生产日期:
production_date_en/da(包含start、end、start_prec、end_prec、period字段的列表)。 - 尺寸:
dimensions(包含value、unit、part、type、notes、precision字段的列表)。
标题与名称
- 标题:
titles_en/da(包含language、title、type、notes、translation字段的列表)。 - 对象名称:
object_names_en/da(包含name、classification_notes字段的列表)。
创作者信息
- 艺术家:
artist_en/da(字符串列表)。 - 生产信息:
production_en/da(包含creator、creator_forename、creator_surname、creator_gender、creator_nationality、creator_role、creator_history、creator_lref、creator_qualifier、craftsman、出生/死亡日期、notes 等字段的列表)。
技术与材料
techniques_en/da、materials_en/da、medium_en/da。
上下文与文献
- 标签:
labels_en/da(包含date、source、text、type字段的列表)。 - 题字:
inscriptions_en/da(包含content、description、language、type、date、notes字段的列表)。 - 文献:
documentation_en/da(包含author、title、shelfmark、page_reference、year_of_publication、notes字段的列表)。 content_description_en/da、production_dates_notes_en/da。
权利信息
public_domain(布尔值) 和rights(字符串)。
预期用途
- 图像描述生成、图像文本检索、元数据补全、博物馆藏品探索、多模态视觉语言建模。
使用方式
python from datasets import load_dataset, Image
ds = load_dataset("V4ldeLund/SMK-image-text", split="train")
将图像字节流解码为 PIL 图像
ds = ds.cast_column("image_bytes", Image()) sample = ds[0] sample["image_bytes"].show()
示例:打印英文标题和生产信息
print(sample["titles_en"], sample["production_en"])
支持与联系
- 问题与讨论: 请在数据集的 Hugging Face 页面发起讨论:https://huggingface.co/datasets/V4ldeLund/SMK-image-text
搜集汇总
数据集介绍
构建方式
该数据集源自丹麦国家美术馆的藏品API,系统性地整合了馆藏艺术品的图像与多语言元数据。构建过程涉及从原始API中提取每件艺术品的完整信息,包括高分辨率图像字节流以及丹麦语和英语的双语标注。数据经过结构化处理,存储为Parquet格式分片,确保了大规模图像文本对的高效存储与访问。整个流程注重保持艺术品的原始属性和多语言描述的完整性,为跨模态研究提供了可靠的数据基础。
特点
SMK图像文本数据集的核心特点在于其丰富的多模态与多语言结构。每一条记录均包含高分辨率图像及其对应的丹麦语和英语元数据,涵盖标题、创作者、技法、材料、年代等详尽的艺术品属性。数据集特别提供了图像的低级视觉特征,如熵、对比度和饱和度,以及权利信息中的公共领域标识。这种双语平行标注与多层次元数据的结合,为视觉语言建模和跨文化艺术研究创造了独特价值。
使用方法
使用该数据集时,可通过Hugging Face的datasets库直接加载,并利用Image解码器将图像字节流转换为PIL图像对象。研究人员可便捷访问双语元数字段,进行图像描述生成、跨语言检索或元数据补全等任务。数据集支持对艺术品生产日期、技法材料等结构化字段的深入分析,适用于博物馆数字化探索或多语言视觉语言模型的训练与评估。
背景与挑战
背景概述
在数字人文与跨模态人工智能研究蓬勃发展的背景下,SMK-image-text数据集应运而生,旨在为艺术领域的多模态学习提供关键资源。该数据集由Vladimir Salnikov等人基于丹麦国家美术馆(Statens Museum for Kunst,SMK)的馆藏API构建,收录了超过三万九千件艺术品的图像与双语元数据。其核心研究问题聚焦于如何利用结构化的视觉与文本信息,推动图像描述生成、跨语言检索及文化遗产的数字化理解。该资源不仅为视觉语言模型提供了丰富的训练素材,亦为博物馆学、艺术史及多语言计算研究开辟了新的探索路径。
当前挑战
该数据集致力于解决艺术领域图像与文本跨模态对齐的复杂挑战,具体包括如何从非结构化的博物馆元数据中提取并规范化多语言描述,以及如何确保图像内容与历史、技法等专业文本的语义一致性。在构建过程中,研究者需克服数据异构性带来的困难,例如处理不同时期艺术品的残缺或模糊元数据,统一多语言字段的表述格式,并在尊重版权的前提下平衡高分辨率图像的可访问性与存储效率。这些挑战共同塑造了数据集在支持细粒度艺术分析与多模态模型训练时的独特价值。
常用场景
经典使用场景
在跨模态人工智能研究中,SMK-image-text数据集以其丰富的图像与双语文本配对,为图像描述生成任务提供了经典范例。该数据集整合了丹麦国家美术馆的高质量艺术品图像及详尽的元数据,使得研究者能够训练模型学习从视觉内容到自然语言描述的映射,尤其在多语言环境下,模型可同时生成丹麦语和英语的精准描述,推动了图像理解与语言生成的深度融合。
实际应用
在实际应用中,SMK-image-text数据集被广泛用于博物馆数字化服务、智能导览系统以及多语言内容管理平台。基于该数据集训练的模型能够自动生成艺术品的双语介绍,辅助策展人进行藏品分类与检索,同时提升公众在线浏览体验。此外,其公开领域标志支持合规的文化遗产再利用,为教育、旅游等产业提供了技术支撑。
衍生相关工作
围绕SMK-image-text数据集,已衍生出多项经典研究工作,包括多语言视觉语言预训练模型、艺术风格跨模态检索算法以及元数据自动补全系统。这些工作利用数据集的丰富标注,推动了跨模态表示学习在文化遗产领域的应用,例如开发能够理解艺术品历史背景的AI工具,为后续的学术探索与技术创新奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


