CiferAI/Cifer-Fraud-Detection-Dataset-AF
收藏Hugging Face2025-08-02 更新2025-04-12 收录
下载链接:
https://hf-mirror.com/datasets/CiferAI/Cifer-Fraud-Detection-Dataset-AF
下载链接
链接失效反馈资源简介:
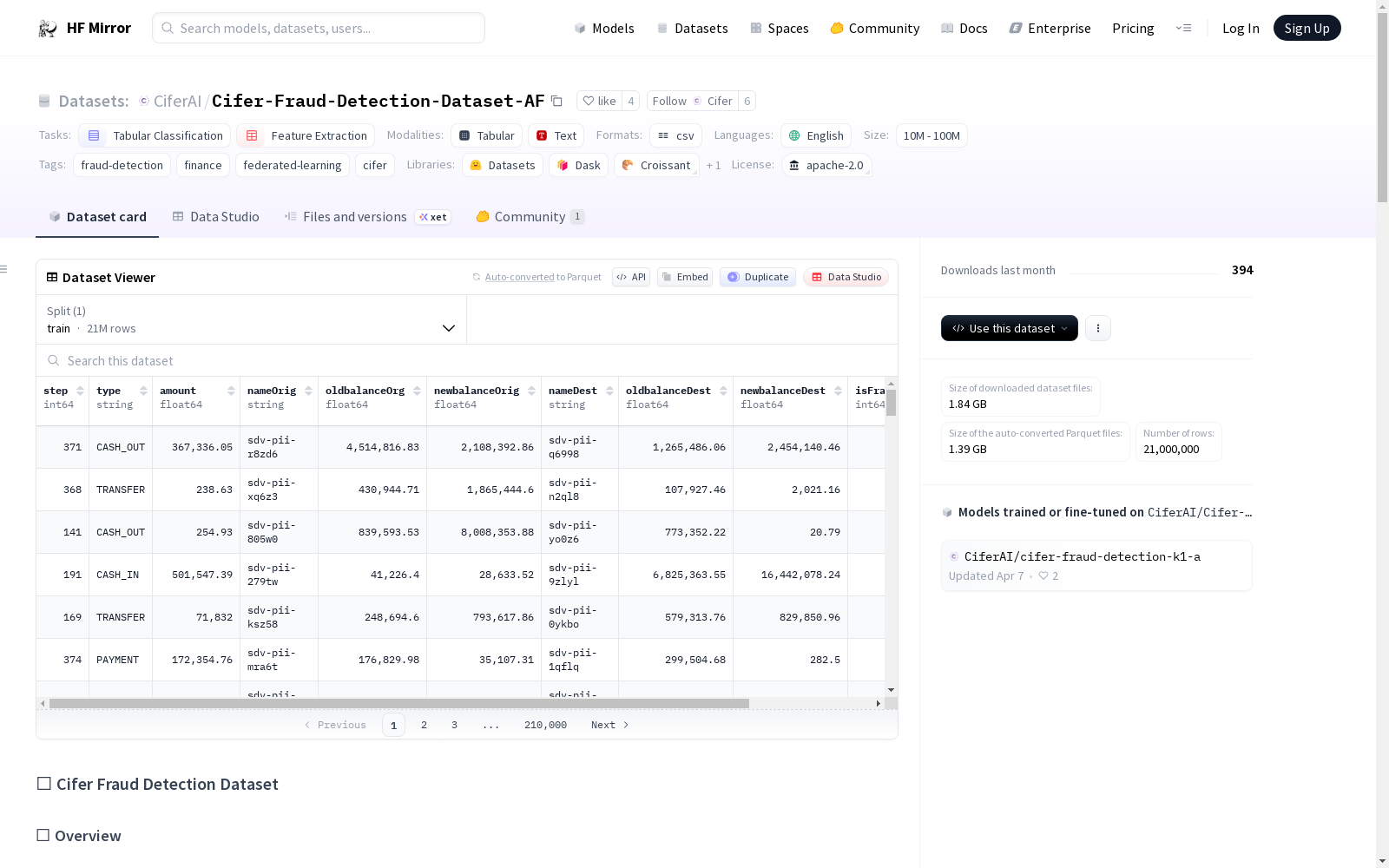
Cifer-Fraud-Detection-Dataset-AF是一个高保真、完全合成的数据集,旨在支持金融欺诈检测中隐私保护、联邦和去中心化机器学习系统的发展和基准测试。该数据集基于PaySim模拟器构建,并扩展到了600万个样本,优化了联邦学习环境,并针对现实世界数据集进行了性能验证。数据集是安全的,可以进行公开发布,与联邦学习兼容,适合隐私保护的机器学习以及鲁棒性测试,可以与现实世界的欺诈数据集进行基准测试,并支持公平性评估。
The Cifer-Fraud-Detection-Dataset-AF is a high-fidelity, fully synthetic dataset designed to support the development and benchmarking of privacy-preserving, federated, and decentralized machine learning systems for financial fraud detection. The dataset is built upon the PaySim simulator and extended to 6 million samples, optimized for federated learning environments, and validated against real-world datasets. It is safe for public release, compatible with federated learning, suitable for privacy-preserving machine learning and robustness testing, benchmarkable against real-world fraud datasets, and supports fairness evaluation.
提供机构:
CiferAI
AI搜集汇总
数据集介绍
构建方式
在金融欺诈检测领域,数据隐私与模型泛化能力是核心挑战。Cifer-Fraud-Detection-Dataset-AF采用完全合成的方式构建,其生成过程借鉴了PaySim模拟器的结构框架,该框架源自真实移动货币交易数据的聚合分析。通过内部仿真引擎,该数据集模拟了金融行为模式、代理动态及欺诈策略,生成了2100万条样本,并针对联邦学习环境进行了优化,包括多智能体测试、异步训练支持以及不平衡标签分布的设计,确保了数据的高保真度与实用性。
特点
该数据集具备多项显著特点,其完全合成的特性保障了数据公开使用的安全性,同时避免了敏感信息泄露。数据集专为联邦学习场景设计,支持跨孤岛、异步及多智能体等分布式机器学习范式,适用于隐私保护机器学习与模型鲁棒性测试。通过模拟真实的欺诈标记机制与不平衡标签分布,它能够有效支持公平性评估与对抗性欺诈建模,为去中心化人工智能系统提供了可靠的基准测试平台。
使用方法
在应用层面,该数据集主要用于金融欺诈检测的基准测试,特别是在去中心化AI系统中评估模型性能。研究人员可将其用于联邦学习仿真,涵盖模型训练、评估与聚合全流程。数据集支持多文件分区加载,便于大规模与分布式处理,同时可用于模型偏差缓解与公平性测试。通过模拟交易类型、金额、余额等多维特征,用户能够构建并验证欺诈检测模型,推动隐私保护机器学习技术的发展。
背景与挑战
背景概述
在金融科技与隐私计算交叉领域,CiferAI/Cifer-Fraud-Detection-Dataset-AF数据集应运而生,旨在为分布式机器学习系统提供高保真基准。该数据集由Cifer AI团队构建,其核心研究问题聚焦于如何在保护数据隐私的前提下,于联邦学习环境中高效检测金融欺诈行为。数据集的结构灵感源自PaySim模拟器,后者基于真实移动货币交易数据构建,而Cifer在此基础上将样本规模扩展至2100万条,并针对异步训练与多智能体测试进行了优化。自发布以来,该数据集已成为评估隐私保护算法与联邦学习框架的重要工具,推动了金融安全与分布式人工智能的融合研究。
当前挑战
该数据集致力于解决金融欺诈检测领域的关键挑战,即在数据孤岛与隐私约束下实现高精度模型训练。具体而言,欺诈交易通常呈现极度不平衡的类别分布,且欺诈模式动态演化,要求模型具备强大的泛化与实时适应能力。在构建过程中,挑战主要集中于生成既符合真实金融行为统计特性,又能支持联邦学习分区与异步训练的合成数据。这需要精确模拟交易时序、用户交互模式以及欺诈策略的复杂性,同时确保合成数据与真实数据集在模型性能上具有可比性,例如达到99.93%的准确率基准,以验证其仿真有效性。
常用场景
经典使用场景
在金融科技领域,欺诈检测模型的开发常受限于真实交易数据的隐私与安全约束。Cifer-Fraud-Detection-Dataset-AF作为高保真合成数据集,其经典使用场景在于为隐私保护机器学习与联邦学习系统提供标准化基准测试环境。该数据集模拟了移动货币交易中的行为模式与欺诈策略,包含2100万条样本,支持跨设备、异步及多智能体的分布式训练框架,使研究人员能够在无需接触敏感信息的前提下,有效评估模型在去中心化架构下的检测性能与泛化能力。
实际应用
在实际应用中,该数据集被金融机构与科技公司用于构建和优化分布式欺诈检测系统。它支持跨机构协作建模,允许各参与方在数据不出本地的前提下共同训练高性能检测模型,显著提升了反欺诈系统的覆盖范围与响应速度。同时,其合成的交易流与欺诈标签可用于模拟新型欺诈手法,帮助开发团队提前部署防御策略,增强金融基础设施的韧性与适应性。
衍生相关工作
基于该数据集衍生的经典工作主要集中在联邦学习框架的优化与隐私保护机制的创新上。例如,研究者利用其多分区特性设计了异步聚合算法,以应对网络延迟与设备异构性挑战;另有工作结合差分隐私技术,在保证模型精度的同时强化用户数据保密性。此外,该数据集也催生了针对欺诈检测的公平性评估基准,促进了检测算法在人口统计学维度上的偏差量化与缓解研究。
以上内容由AI搜集并总结生成


