PyraNet-Verilog
收藏arXiv2024-12-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/bnadimi/PyraNet-Verilog
下载链接
链接失效反馈官方服务:
资源简介:
PyraNet-Verilog是由南佛罗里达大学开发的开放源代码数据集,专门用于Verilog代码生成。该数据集包含235个高质量的Verilog代码样本,分为不同复杂度等级,从基础到专家级别。数据集的创建过程包括从公开的GitHub仓库收集代码,使用商业大语言模型生成代码样本,并通过多重过滤步骤确保数据质量。PyraNet-Verilog主要用于硬件设计领域的代码生成和模型微调,旨在提高Verilog代码生成的准确性和功能性。
PyraNet-Verilog is an open-source dataset developed by the University of South Florida, specifically tailored for Verilog code generation. It contains 235 high-quality Verilog code samples categorized into multiple complexity levels, ranging from basic to expert-level. The dataset's creation process involves collecting code from public GitHub repositories, generating code samples using commercial large language models (LLMs), and implementing multiple filtering steps to ensure data quality. PyraNet-Verilog is primarily used for code generation and model fine-tuning in the hardware design domain, aiming to improve the accuracy and functionality of Verilog code generation.
提供机构:
南佛罗里达大学
创建时间:
2024-12-10
搜集汇总
数据集介绍
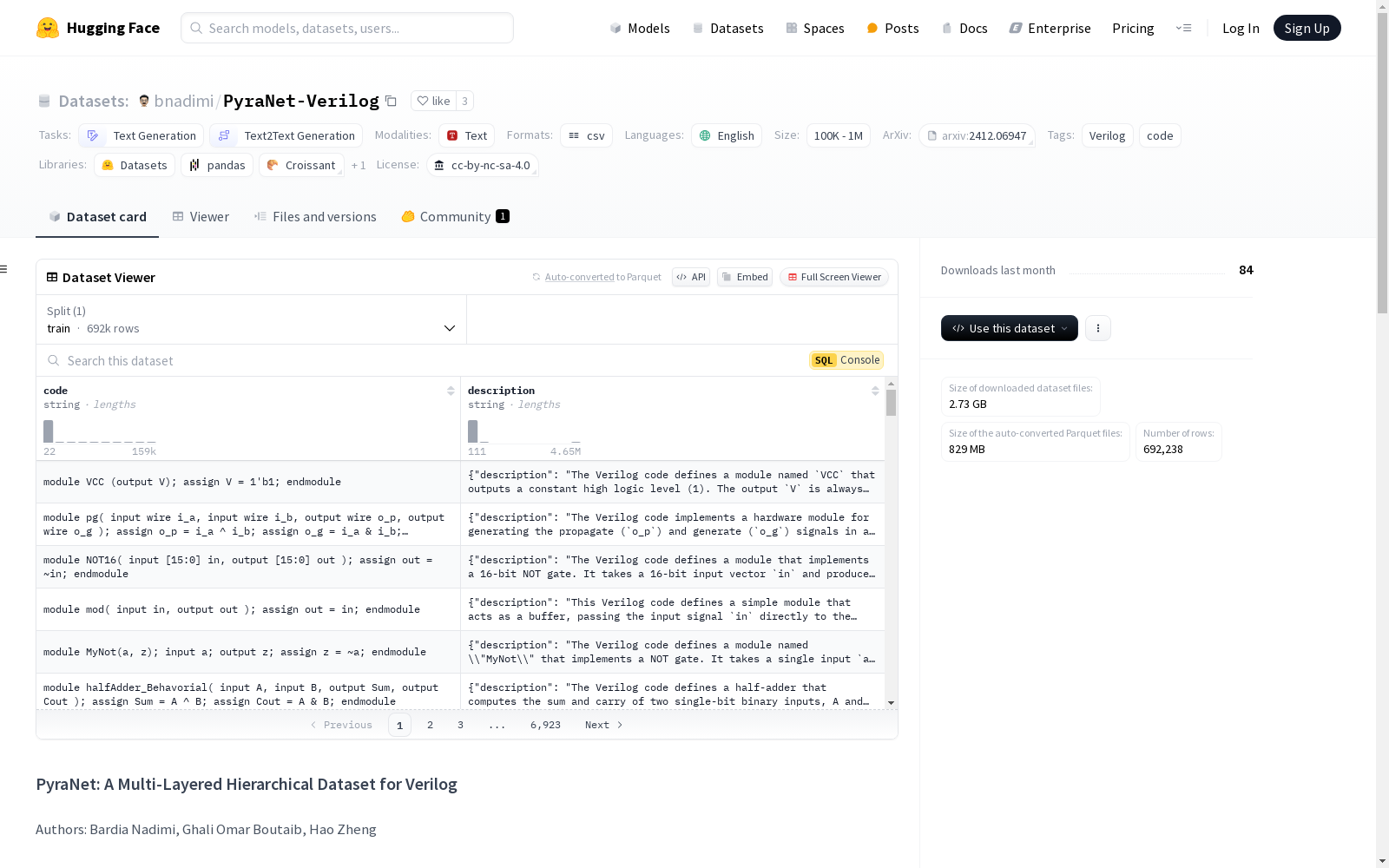
构建方式
PyraNet-Verilog数据集的构建过程融合了多种高质量的Verilog代码样本,主要来源于公开的GitHub仓库以及通过商业大语言模型(如GPT-4o-mini)生成的代码。在收集代码后,数据集经历了多重过滤步骤,包括去除空文件、损坏文件、无模块声明的文件,并通过Jaccard相似度算法进行去重。此外,所有代码样本均通过Icarus Verilog进行语法检查,确保数据集的语法正确性。为了进一步丰富数据集,研究人员还通过GPT-4o-mini生成了大量代码样本,并根据复杂度和质量对其进行分级和排名,最终形成了多层次的PyraNet数据集结构。
特点
PyraNet-Verilog数据集的核心特点在于其多层次的结构设计,数据集被划分为六个层级,每个层级根据代码的质量和复杂度进行分类。最高层级的代码样本具有最高的质量和效率,而较低层级的样本则包含更多的依赖问题或较低的编译成功率。此外,数据集还引入了复杂度标签,将代码分为基础、中级、高级和专家四个等级,便于模型在训练过程中逐步学习更复杂的代码结构。这种多层次的组织方式使得PyraNet-Verilog能够为不同层次的Verilog代码生成任务提供丰富的训练数据。
使用方法
PyraNet-Verilog数据集的使用方法主要体现在其与大语言模型(LLM)的结合上。研究人员通过引入损失加权和课程学习策略,对模型进行精细调优。具体来说,模型在训练过程中首先从高质量的代码样本开始学习,逐步过渡到复杂度更高的样本,确保模型能够逐步掌握Verilog代码的生成技巧。此外,损失加权策略通过为不同层级的数据样本分配不同的损失权重,进一步优化模型的学习效果。通过这种多层次的训练方法,PyraNet-Verilog数据集能够显著提升模型在Verilog代码生成任务中的表现,尤其是在语法和功能正确性方面。
背景与挑战
背景概述
近年来,随着大型语言模型(LLMs)在硬件描述语言(HDL)代码生成中的应用日益增多,Verilog代码生成的质量问题逐渐凸显。PyraNet-Verilog数据集由南佛罗里达大学的Bardia Nadimi、Ghali Omar Boutaib和Hao Zheng等人于2024年提出,旨在解决当前Verilog代码生成中存在的语法和功能错误问题。该数据集通过多层分级的结构,整合了高质量和低质量的Verilog代码样本,并引入了创新的微调方法,显著提升了生成代码的准确性。PyraNet-Verilog不仅为硬件设计领域提供了高质量的训练数据,还通过其独特的微调技术,推动了LLMs在硬件代码生成中的应用,为硬件设计自动化提供了新的可能性。
当前挑战
PyraNet-Verilog数据集的构建面临多重挑战。首先,Verilog代码生成领域缺乏高质量的标注数据,导致LLMs的微调效果受限。其次,现有数据集中的代码质量参差不齐,如何有效利用这些数据是一个难题。此外,构建过程中需要对大量代码进行筛选和分级,确保数据集的多样性和代表性。在微调过程中,如何平衡高质量和低质量数据的权重,以及如何通过课程学习策略逐步提升模型的复杂度处理能力,也是该数据集面临的挑战。这些问题的解决不仅提升了数据集的质量,也为LLMs在硬件设计领域的应用提供了新的思路。
常用场景
经典使用场景
PyraNet-Verilog数据集的经典使用场景主要集中在Verilog代码生成和硬件设计自动化领域。该数据集通过多层次的结构,提供了丰富的Verilog代码样本,涵盖从基础到专家级别的复杂度。研究者可以利用这些样本进行大规模语言模型的微调,以生成高质量的Verilog代码,从而加速硬件设计的流程,减少人为错误。
解决学术问题
PyraNet-Verilog数据集解决了硬件描述语言(HDL)代码生成中的多个学术问题。首先,它填补了高质量Verilog数据集的空白,为研究人员提供了丰富的训练资源。其次,通过引入多层次的微调策略,该数据集显著提升了生成代码的语法和功能正确性,解决了现有方法中常见的错误问题。此外,该数据集还推动了硬件设计自动化的研究,为未来的硬件设计工具提供了新的思路。
衍生相关工作
PyraNet-Verilog数据集的发布催生了一系列相关的经典工作。例如,基于该数据集的微调方法被广泛应用于其他硬件描述语言的生成任务中,推动了硬件设计自动化的进一步发展。此外,该数据集还启发了其他研究者开发新的数据集和微调策略,以应对不同硬件设计任务中的挑战。这些衍生工作不仅扩展了PyraNet-Verilog的应用范围,还为硬件设计领域的研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


