AudioEchoes
收藏Hugging Face2024-08-22 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/infinite-dataset-hub/AudioEchoes
下载链接
链接失效反馈官方服务:
资源简介:
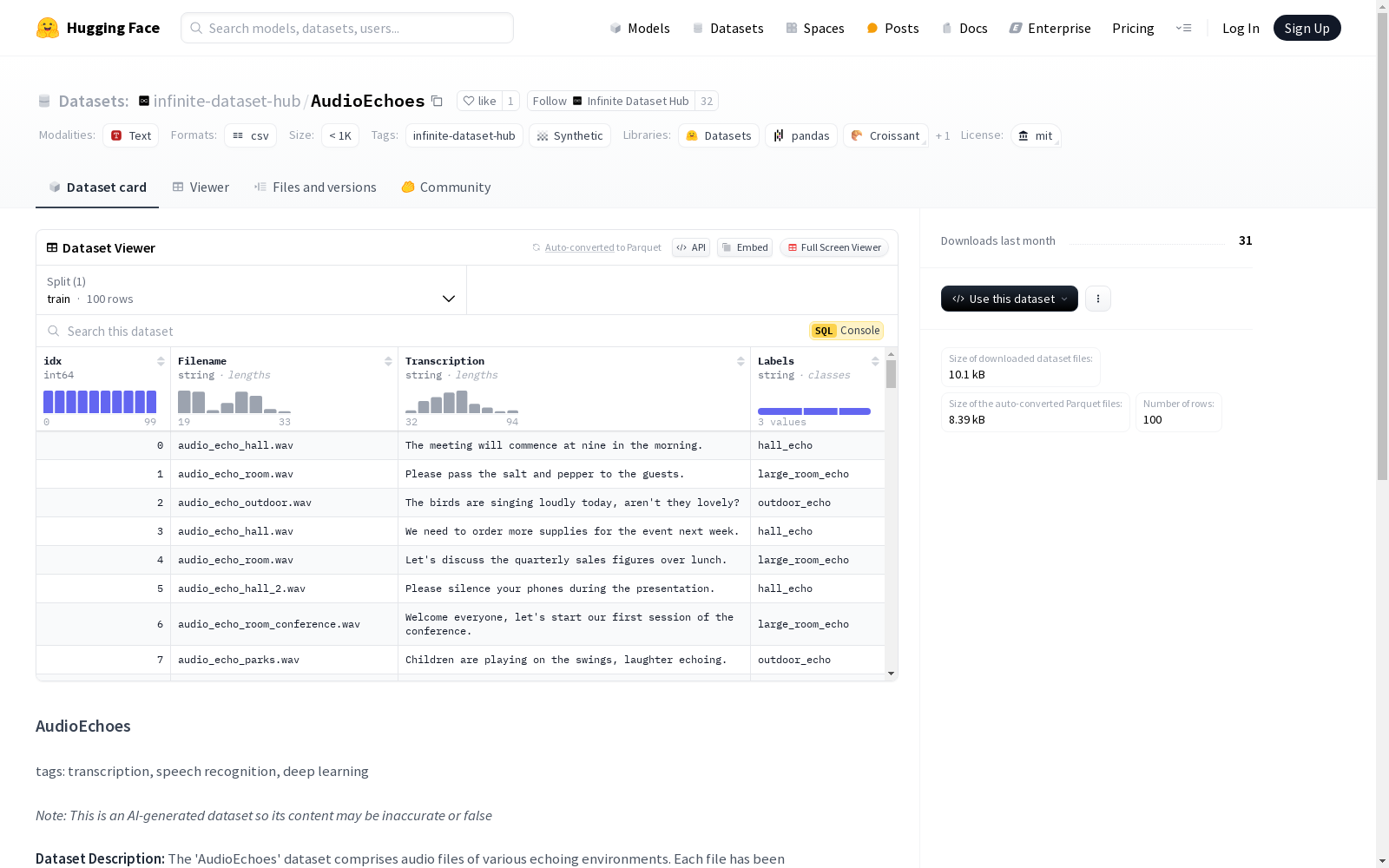
‘AudioEchoes’数据集包含来自多种回声环境的音频文件。每个文件都由最先进的语音识别系统转录,旨在协助开发和评估语音转文本算法,特别是在识别和处理语音信号中的回声方面。数据集包括多种场景,如大厅、大房间和户外环境的回声,并带有指示回声类型的标签。
创建时间:
2024-08-22
原始信息汇总
AudioEchoes 数据集
数据集描述
AudioEchoes 数据集包含多种回声环境的音频文件。每个文件都由先进的语音识别系统转录,旨在帮助开发和评估语音转文本算法,特别是在识别和处理语音信号中的回声方面。数据集包括多种场景,如大厅中的回声、大房间中的回声和户外环境中的回声,标签指示存在的回声类型。
CSV 内容预览
"Filename","Transcription","Labels" "audio_echo_hall.wav","The meeting will commence at nine in the morning.","hall_echo" "audio_echo_room.wav","Please pass the salt and pepper to the guests.","large_room_echo" "audio_echo_outdoor.wav","The birds are singing loudly today, arent they lovely?","outdoor_echo" "audio_echo_hall.wav","We need to order more supplies for the event next week.","hall_echo" "audio_echo_room.wav","Lets discuss the quarterly sales figures over lunch.","large_room_echo"
数据来源
该数据集使用 Infinite Dataset Hub 和 microsoft/Phi-3-mini-4k-instruct 生成,查询为 speech to text:
- 数据集生成页面: https://huggingface.co/spaces/infinite-dataset-hub/infinite-dataset-hub?q=speech+to+text&dataset=AudioEchoes&tags=transcription,+speech+recognition,+deep+learning
- 模型: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct
- 更多数据集: https://huggingface.co/datasets?other=infinite-dataset-hub
搜集汇总
数据集介绍
构建方式
AudioEchoes数据集通过先进的语音识别系统生成,旨在模拟多种回声环境下的语音信号。数据集的构建基于Infinite Dataset Hub平台,利用microsoft/Phi-3-mini-4k-instruct模型进行语音到文本的转换。数据集涵盖了不同场景下的回声效果,如大厅、大房间和户外环境,每种场景均配有相应的标签,以指示回声类型。
使用方法
AudioEchoes数据集适用于开发和评估语音到文本算法,特别是在处理回声环境下的语音识别任务中。研究者可以通过分析不同回声场景下的语音数据,优化现有的语音识别模型。数据集中的标签信息可用于训练和测试模型在不同回声条件下的表现,从而提升模型的鲁棒性和准确性。
背景与挑战
背景概述
AudioEchoes数据集是一个专注于回声环境下语音识别的研究数据集,旨在为语音转文本算法的开发与评估提供支持。该数据集由Infinite Dataset Hub与微软的Phi-3-mini-4k-instruct模型合作生成,涵盖了多种回声场景,如大厅、大房间和户外环境。通过使用先进的语音识别系统对音频文件进行转录,AudioEchoes为研究回声对语音信号的影响提供了丰富的实验数据。这一数据集的出现,为语音识别领域在复杂声学环境下的技术突破提供了重要参考。
当前挑战
AudioEchoes数据集在解决回声环境下的语音识别问题时,面临多重挑战。首先,回声会显著降低语音信号的清晰度,导致传统语音识别模型的性能下降,如何有效分离回声与原始语音成为关键难题。其次,数据集的构建依赖于合成数据生成技术,尽管采用了先进的模型,但生成的内容可能存在不准确或虚假信息,影响模型的训练效果。此外,回声场景的多样性和复杂性也对数据标注和模型泛化能力提出了更高要求,如何在保证数据质量的同时提升模型的鲁棒性,是未来研究的重要方向。
常用场景
经典使用场景
在语音识别领域,AudioEchoes数据集被广泛应用于开发和评估语音转文本算法,特别是在处理回声环境下的语音信号时。该数据集通过模拟不同回声环境(如大厅、大房间和户外)的音频文件,为研究人员提供了一个多样化的测试平台,帮助他们优化模型在复杂声学条件下的表现。
解决学术问题
AudioEchoes数据集解决了语音识别领域中的一个关键问题,即在回声环境下准确转录语音的挑战。通过提供带有详细标签的回声音频样本,该数据集使研究人员能够深入分析回声对语音识别精度的影响,并开发出更具鲁棒性的算法,从而提升语音识别系统在实际应用中的可靠性。
实际应用
在实际应用中,AudioEchoes数据集为智能语音助手、会议转录系统和远程通信工具的开发提供了重要支持。例如,在嘈杂的回声环境中,智能语音助手可以借助该数据集训练的模型更准确地理解用户指令,而会议转录系统则能够更清晰地捕捉发言内容,提升用户体验和工作效率。
数据集最近研究
最新研究方向
在语音识别领域,回声环境下的语音信号处理一直是技术难点之一。AudioEchoes数据集的推出,为研究回声环境下的语音识别算法提供了重要的实验基础。该数据集通过模拟不同场景下的回声效果,如大厅、大房间和户外环境,生成了丰富的语音样本,并配备了高质量的转录文本。这些数据不仅能够帮助研究人员评估现有语音识别系统在复杂声学环境中的表现,还为开发新的回声抑制和语音增强算法提供了宝贵的训练资源。随着深度学习技术的不断进步,AudioEchoes数据集有望在语音识别、语音增强以及智能语音助手的开发中发挥重要作用,推动相关领域的技术突破。
以上内容由遇见数据集搜集并总结生成


