MMLU-Pro
收藏arXiv2024-06-05 更新2024-06-17 收录
下载链接:
https://huggingface.co/datasets/TIGER-Lab/MMLU-Pro
下载链接
链接失效反馈官方服务:
资源简介:
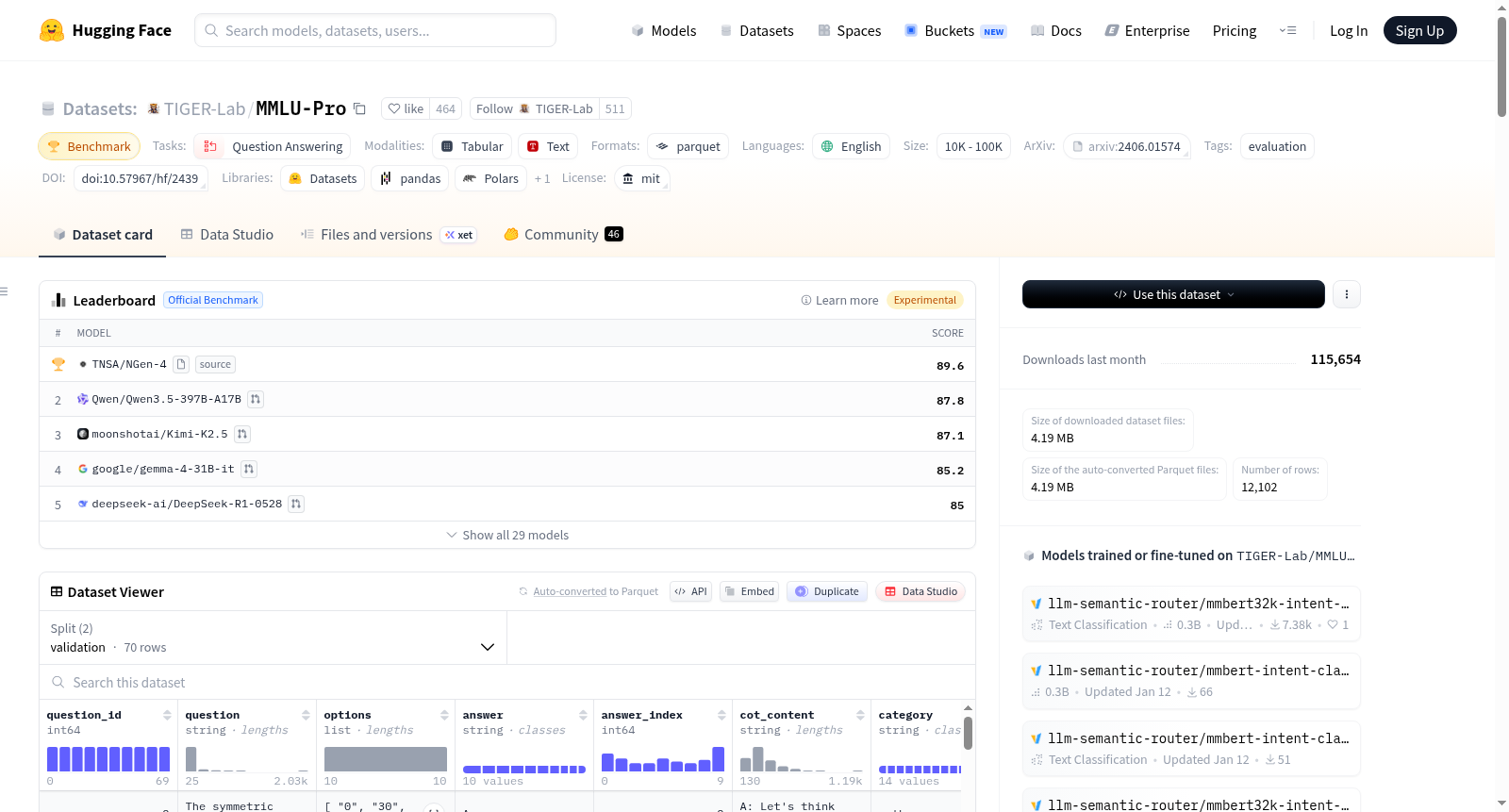
MMLU-Pro是由滑铁卢大学等机构创建的综合性语言理解与推理基准数据集,包含12,032个问题,覆盖14个不同的学科领域。该数据集通过增加选项数量和引入更多需要深思熟虑推理的大学水平考试问题,显著提高了挑战性和鲁棒性。创建过程中,数据集经历了两轮专家评审,以减少数据噪声并确保问题质量。MMLU-Pro旨在通过提供更复杂、更具挑战性的问题,推动大型语言模型在多学科语言理解和推理能力上的进步。
MMLU-Pro is a comprehensive language understanding and reasoning benchmark dataset created by institutions including the University of Waterloo, containing 12,032 questions spanning 14 distinct academic disciplines. This dataset significantly enhances challenge and robustness by increasing the number of answer options and introducing more college-level exam questions that require deliberate, well-considered reasoning. During its development, the dataset underwent two rounds of expert reviews to reduce data noise and ensure high-quality questions. MMLU-Pro aims to advance the multi-disciplinary language understanding and reasoning capabilities of large language models (LLMs) by providing more complex and challenging questions.
提供机构:
滑铁卢大学
创建时间:
2024-06-04
搜集汇总
数据集介绍
构建方式
在大型语言模型评估领域,MMLU-Pro数据集的构建旨在应对现有基准测试中模型性能趋于饱和的挑战。该数据集以原始MMLU为核心,通过整合STEM网站、TheoremQA和SciBench等高质量资源,扩展了问题的来源与难度。构建过程首先对原始MMLU进行筛选,利用多个模型过滤掉过于简单的问题,随后引入外部题目并采用GPT-4-Turbo生成额外干扰项,将选项从四个扩充至十个。为确保数据质量,专家团队进行了两轮审查,验证答案准确性并消除虚假选项,最终形成涵盖14个学科、超过12,000道题目的综合性基准。
特点
MMLU-Pro数据集展现出显著的特点,其核心在于提升评估的区分度与鲁棒性。通过将选择题选项增至十个,大幅降低了随机猜测的概率,增强了问题的挑战性。数据集强调推理能力,特别是STEM领域的问题要求模型进行多步骤计算与逻辑推导,而非单纯依赖知识记忆。实验表明,模型在MMLU-Pro上的表现对提示词的敏感性显著降低,波动范围从MMLU的4-5%减少至2%,体现了更高的稳定性。此外,思维链推理方法在该数据集上能带来显著性能提升,凸显了其深度推理导向的设计理念。
使用方法
使用MMLU-Pro进行评估时,通常采用少样本思维链提示策略,以激发模型的推理能力。评估过程中,模型被要求逐步分析问题并最终输出答案选项,答案提取通过正则表达式匹配完成,确保格式一致性。该数据集支持对开源与闭源模型的广泛测试,涵盖数学、物理、法律等多个学科,用户可通过官方排行榜比较模型性能。值得注意的是,由于问题难度较高,直接回答与思维链推理的结果差异显著,建议在评估中优先采用推理增强的方法,以全面衡量模型的复杂问题解决能力。
背景与挑战
背景概述
在大型语言模型迅猛发展的时代背景下,评估模型在跨领域语言理解与推理任务中的能力成为推动人工智能进步的关键。MMLU-Pro数据集于2024年由滑铁卢大学、多伦多大学及卡内基梅隆大学的研究团队联合推出,旨在应对现有基准如MMLU因模型性能饱和而难以区分先进模型能力的挑战。该数据集聚焦于提升多任务语言理解评估的难度与鲁棒性,通过整合更多需要复杂推理的大学水平试题,并将选项从四个扩展至十个,显著增强了基准的判别力。MMLU-Pro涵盖了数学、物理、法律、工程等14个学科,包含超过12,000道题目,其构建不仅消除了原始数据集中的噪声与简单问题,还引入了两轮专家评审以确保质量。这一数据集的问世,为追踪语言模型向专家级智能发展的进程提供了更为精准的测量工具,对推动自然语言处理领域的评估方法论产生了深远影响。
当前挑战
MMLU-Pro数据集致力于解决多任务语言理解评估中模型性能区分度不足的核心问题。在领域挑战方面,原始MMLU基准因题目多为知识驱动且选项有限,导致先进模型表现趋同,无法有效辨识模型在复杂推理能力上的差异。MMLU-Pro通过引入更多需要多步推导与逻辑分析的题目,并大幅增加干扰选项,迫使模型依赖思维链等深层推理机制,从而更真实地反映模型在专业级问题解决上的潜力。在构建挑战层面,研究团队面临多重困难:首先,需从原始MMLU中筛选并剔除过于简单或标注错误的题目,同时整合来自STEM网站、TheoremQA及SciBench等多个来源的高质量试题,确保数据集的广度与难度平衡;其次,在选项扩充过程中,生成既具迷惑性又符合学科逻辑的干扰项,需借助大模型与人工专家协同验证,以避免误引入正确选项;此外,维持数据集的低噪声水平要求进行多轮专家评审,以修正答案错误、剔除不适宜选择题形式的题目,并保证选项的有效性,这一过程耗费大量人力与计算资源。这些挑战共同塑造了MMLU-Pro在评估语言模型推理能力方面的权威性与前瞻性。
常用场景
经典使用场景
在大型语言模型评估领域,MMLU-Pro作为一项增强型多任务语言理解基准,其经典使用场景在于对前沿模型进行精细化能力区分。该数据集通过整合更具挑战性的推理密集型问题,并扩展选项至十个,有效克服了原始MMLU中因模型性能饱和导致的区分度不足问题。研究者在模型对比与能力评估中,广泛采用MMLU-Pro来衡量模型在数学、物理、法律等14个学科领域的深层推理与知识应用水平,尤其侧重于检验链式思维推理的有效性。
实际应用
在实际应用层面,MMLU-Pro被广泛用于指导模型开发与优化过程。人工智能研发团队利用该基准识别模型在特定学科领域的薄弱环节,例如工程学中的公式推导或法律领域的复杂条文理解,从而针对性地调整训练策略或引入领域知识。此外,教育科技领域可借助MMLU-Pro评估智能辅导系统的学科解答能力,确保其具备足够的专业深度与推理准确性。该数据集还为模型选型提供了关键依据,帮助企业在部署语言模型时更精准地匹配实际业务对复杂问题处理的需求。
衍生相关工作
围绕MMLU-Pro衍生出一系列重要的相关研究工作。许多研究团队以该数据集为基础,开发了专门针对多选项推理的评估框架与提示工程方法,例如优化链式思维提示在十选项场景下的有效性。同时,部分工作聚焦于分析模型在MMLU-Pro上的错误类型,系统性地揭示了当前语言模型在逻辑推理、专业知识和计算能力等方面的共性缺陷。这些衍生研究不仅深化了对模型能力边界的理解,也推动了诸如专业领域微调、推理模块增强等新技术的演进,持续拓展着语言模型评估与优化的方法论体系。
以上内容由遇见数据集搜集并总结生成


