eno-newspapers-enriched
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/chcaa/eno-newspapers-enriched
下载链接
链接失效反馈官方服务:
资源简介:
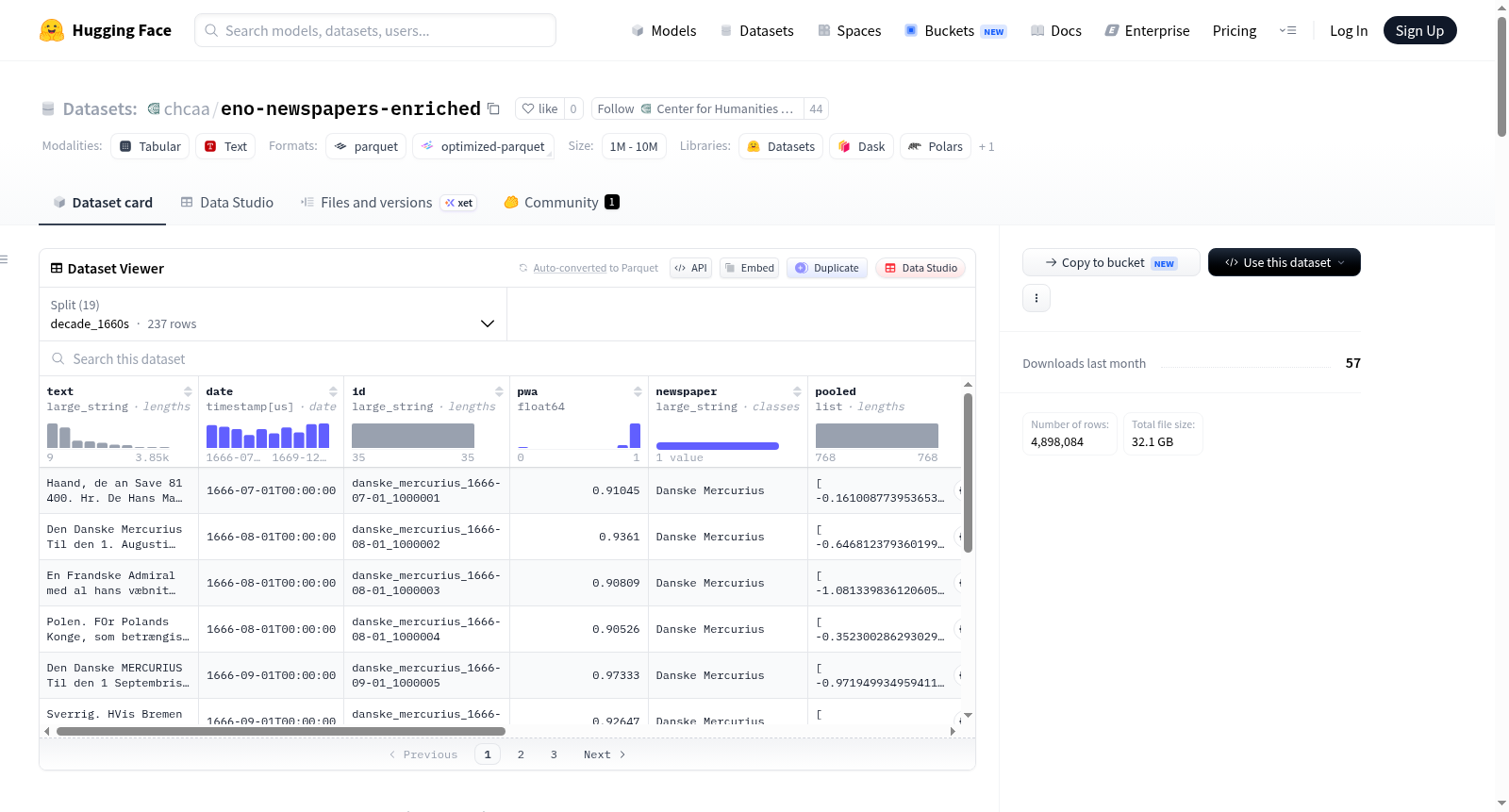
该数据集名为Danish Historical Newspaper Articles Dataset (enriched),是一个包含约490万篇丹麦历史报纸文章(覆盖1666年至1850年)的丰富资源,源自28种丹麦-挪威时期的历史报纸和期刊的数字化内容。数据集以丹麦语(da)为主,格式为Parquet文件,总文章数约为4,898,084篇,未压缩大小约33.7 GB,下载大小约25.1 GB。关键特征包括:`text`(完整文章文本)、`date`(发布日期)、`id`(唯一文章标识符)、`pwa`(概率加权属性)、`newspaper`(报纸标题)、`pooled`(使用Old_News_Segmentation_SBERT_V0.1模型生成的预计算嵌入向量,用于语义分析)、`year`(出版年份)、`decade`(出版年代)、`predicted_category`(自动分配的内容类别,如国内新闻、国际新闻、广告、副文本等)、`fictionality_tag`(自动分配的虚构性标签:小说/非小说)、`fiction_prob`/`non_fiction_prob`(虚构性标签的对应概率)。数据集按年代(decade)分片(例如decade_1660s, decade_1670s等),便于按时间范围加载和采样。其旨在通过主要新闻来源为研究丹麦语言、文化和历史提供全面的语料库,适用于自然语言处理任务,如历史语言分析、文本分类(基于类别和虚构性)、语义相似度计算(利用嵌入向量)以及数字人文研究。自动标注详细信息包括:预测类别标签通过在Old_News模型嵌入上训练的Logistic回归分类器生成,在广告、国内新闻和国际新闻类别上实现高F1分数(0.93–0.97);预测虚构性标签同样使用基于Old_News嵌入的Logistic回归分类器生成,并通过分层组k折交叉验证进行性能验证,在小说和非小说类别上实现约0.88–0.89的精确率/召回率,概率校准良好(Brier分数0.024),其中约77,513篇文章(约1.58%)被分类为小说。已知限制包括:可能存在的OCR错误(由于印刷质量、纸张退化或OCR限制)、文章边界识别不准确可能导致文章合并或拆分、内容反映当时时期的观点、偏见和社会态度(可能包含有偏见的看法)、数字化可能无法覆盖所有时间段或报纸、丹麦语言、拼写和正字法随时间演变、可用的报纸可能无法平等代表所有地区、政治观点或社会阶层。数据集由Alie Lassche、Pascale Feldkamp和Johan Heinsen策划,原始数字化由Johan Heinsen和Camilla Bøgeskov在ENO项目下完成。
The dataset is named Danish Historical Newspaper Articles Dataset (enriched), a rich resource containing approximately 4.9 million Danish historical newspaper articles (covering 1666 to 1850), derived from digitized content of 28 historical newspapers and periodicals from the Danish-Norwegian period. The dataset is primarily in Danish (da), formatted as Parquet files, with a total of approximately 4,898,084 articles, an uncompressed size of about 33.7 GB, and a download size of about 25.1 GB. Key features include: `text` (full article text content), `date` (publication date), `id` (unique article identifier), `pwa` (probability-weighted attribute), `newspaper` (newspaper title), `pooled` (precomputed embedding vectors generated using the Old_News_Segmentation_SBERT_V0.1 model for semantic analysis), `year` (publication year), `decade` (publication decade), `predicted_category` (automatically assigned content categories such as domestic news, international news, advertisements, paratext, etc.), `fictionality_tag` (automatically assigned fictionality label: fiction/non-fiction), and `fiction_prob`/`non_fiction_prob` (corresponding probabilities for fictionality labels). The dataset is sharded by decade (e.g., decade_1660s, decade_1670s, etc.) to facilitate loading and sampling by time range. It aims to provide a comprehensive corpus for studying Danish language, culture, and history through primary news sources, and is suitable for natural language processing tasks such as historical language analysis, text classification (based on categories and fictionality), semantic similarity computation (using embedding vectors), and digital humanities research. Automatic annotation details include: predicted category labels are generated by a Logistic Regression classifier trained on Old_News model embeddings, achieving high F1 scores (0.93–0.97) for categories like advertisements, domestic news, and international news; predicted fictionality labels are similarly generated using a Logistic Regression classifier based on Old_News embeddings, with performance validated via stratified group k-fold cross-validation, achieving precision/recall of approximately 0.88–0.89 for fiction and non-fiction categories, good probability calibration (Brier score 0.024), with about 77,513 articles (approximately 1.58%) classified as fiction. Known limitations include: potential OCR errors due to print quality, paper degradation, or OCR limitations; inaccurate article boundary identification may lead to article merging or splitting; content reflects the perspectives, biases, and social attitudes of the period, which may include biased views; digitization may not cover all time periods or newspapers; the Danish language, spelling, and orthography have evolved over time; and available newspapers may not equally represent all regions, political views, or social classes. The dataset is curated by Alie Lassche, Pascale Feldkamp, and Johan Heinsen, with original digitization performed by Johan Heinsen and Camilla Bøgeskov under the ENO project.
提供机构:
Center for Humanities Computing Aarhus
创建时间:
2026-05-20
搜集汇总
数据集介绍
构建方式
该数据集源自丹麦与挪威国家图书馆珍藏的报刊史料,经由数字化扫描与光学字符识别技术提取文本。研究团队采用专用句子嵌入模型Old_News_Segmentation_SBERT_V0.1为每篇文章生成文档级别的向量表征(pooled embeddings)。在此基础上,通过逻辑回归分类器对文章进行内容类别(国内新闻、国际新闻、广告、杂项)与虚构性(虚构与非虚构)的自动标注,并以概率形式呈现分类置信度,从而构建出一个富含语义与元数据注释的历史报刊语料库。
使用方法
用户可通过HuggingFace Datasets库便捷调用该资源。加载完整语料库仅需一行代码:load_dataset("chcaa/eno-newspapers-enriched", split="train")。针对特定十年的研究需求,可直接指定子集名称如"decade_1760s"快速访问相应数据。若需跨年代组合分析,可利用concatenate_datasets函数合并多个十年期分片。得益于此分片存储设计,研究者既能高效处理大规模语料,又能灵活提取特定时间窗口的文本进行精细考察。
背景与挑战
背景概述
该数据集由奥胡斯大学人文计算中心的Alie Lassche、Pascale Feldkamp与Johan Heinsen等学者于2026年创建,旨在系统性地整合丹麦历史报纸中的叙事文本,以支持语言演变、文化史与公共话语研究。其核心研究问题在于如何通过大规模数字化语料揭示近代早期丹麦-挪威联合王国中新闻文体与虚构文学的互动关系。数据集收录了1666年至1850年间约490万篇报纸文章,涵盖28种报纸和期刊,并附有基于Old_News模型生成的文档嵌入及虚构性标签,为数字人文学者提供了前所未有的时间纵深与语义分析基础。该成果在LREC 2026等顶级会议上发表,已成为丹麦历史文本挖掘领域的标杆资源。
当前挑战
该数据集面临的挑战首先在于历史报纸特有的领域问题:OCR技术对老旧纸张和变化字体的识别精度有限,导致文本中存在大量错误;同时,新闻与广告等非叙事内容的混杂使得语义分类的边界模糊。构建过程中,研究人员需克服跨世纪语言演变带来的词汇和拼写差异,并处理数字化覆盖不均衡所导致的年代偏见。此外,对文章边界的自动分割易产生段落合并或断裂,而虚构性标签的分类任务则需在极低比率(仅1.58%为虚构)的样本中维持高精度,这要求模型在概率校准与过拟合控制之间取得精细平衡。
常用场景
经典使用场景
eno-newspapers-enriched数据集汇聚了约490万篇丹麦历史报纸文章,时间跨度从1666年至1850年,覆盖了丹麦-挪威联合王国时期的28种重要报刊。每一篇文章不仅保留了完整的文本内容,还附带了出版日期、报纸名称、自动分类标签以及基于Old_News模型生成的语义向量。尤为独特的是,该数据集通过逻辑回归分类器为每篇文章标记了虚构性标签(fiction/non-fiction),并提供了相应的置信度概率。这使得研究者能够从海量历史新闻中精准筛选出虚构类文学片段,用于探讨早期现代公共领域中的文学形态与叙事演变。数据以Parquet格式存储,按年代划分数据分片,便于高效加载与时序分析,是数字人文与历史语言学研究领域的珍贵资源。
解决学术问题
该数据集的核心学术贡献在于填补了早期丹麦语新闻语料在语义标注与虚构性识别方面的空白。传统历史新闻数据集往往缺乏细粒度的内容分类与文学性判断,而eno-newspapers-enriched通过自动化的类别预测(如国家新闻、国际新闻、广告等)和虚构性概率评分,系统性地解决了从大规模OCR文本中识别文学叙事的难题。研究者可借此探讨17至19世纪丹麦公共领域中的虚构与非虚构文本边界,分析广告、新闻报道与文学创作之间的互动关系,并追溯早期印刷文化中‘公共舆论’的形成机制。它为计算文体学、历史社会学和媒介考古学提供了可量化的实证基础,推动了关于印刷资本主义与公共空间演变的跨学科对话。
实际应用
在实际应用层面,该数据集为数字图书馆的语义检索与知识图谱构建提供了坚实基础。图书馆与档案馆可利用其预计算的文章嵌入向量实现跨时代的主题聚类与相似性推荐,帮助用户快速定位特定历史事件或文学潮流的原始报道。新闻史研究者可借助虚构性标签和类别元数据,追溯广告文体如何从纯商业信息转型为虚构故事载体,或者分析不同报纸对国际冲突的报道策略差异。此外,教育领域也可从中提取适配特定年代的丹麦语文本素材,用于历史语言学课程中的语境化语言教学,或作为训练OCR后文本纠错模型的半监督语料,提升对18世纪丹麦语特殊拼写的识别精度。
数据集最近研究
最新研究方向
该数据集聚焦于丹麦历史报纸文本的自动注释与语义分析前沿,通过嵌入模型(Old_News_Segmentation_SBERT_V0.1)与逻辑回归分类器,大规模自动化识别新闻类别与虚构性标签,并提供了高置信度的概率指标。相关研究深入探讨了18至19世纪丹麦公共领域中的虚构文学演变,结合热点事件(如印刷文化扩张与公众舆论形成),揭示了报纸作为历史社会镜像的潜力。该数据集不仅为计算语言学中的历史文本理解提供标准化基准,还推动了对早期现代知识传播、叙事模式及文化偏见的量化考察,具有跨学科的方法论意义。
以上内容由遇见数据集搜集并总结生成


