memory-reasoning-split-eval-sets
收藏Hugging Face2026-04-19 更新2026-04-20 收录
下载链接:
https://huggingface.co/datasets/hyunseoki/memory-reasoning-split-eval-sets
下载链接
链接失效反馈官方服务:
资源简介:
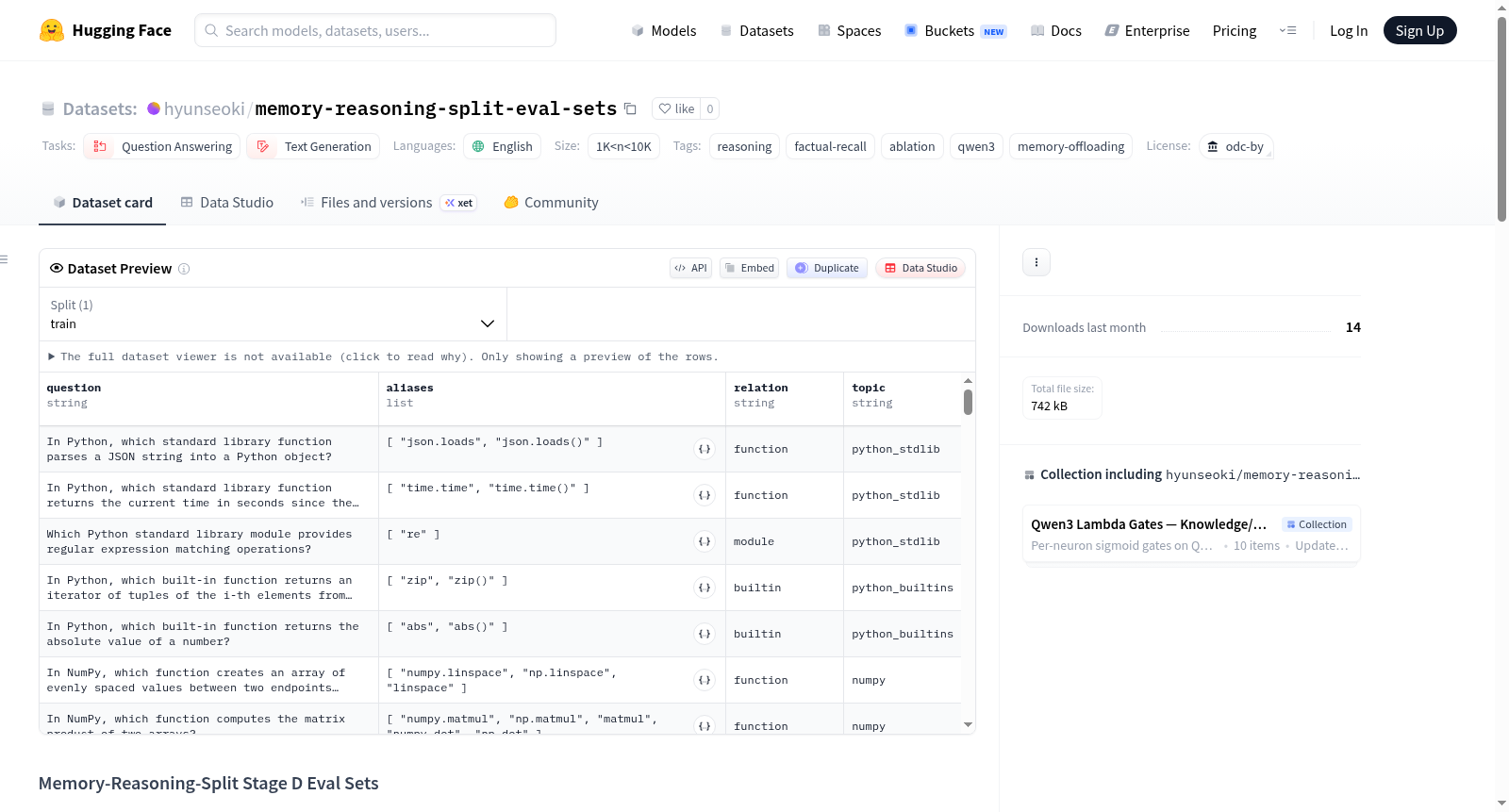
Memory-Reasoning-Split Stage D Eval Sets 是一个用于测量语言模型在选择性遗忘不同领域知识后,领域事实保留与推理能力之间权衡的评估数据集。数据集包含五个主要文件:popqa_general.jsonl(1232行,通用领域闭卷问答)、math_facts.jsonl(100行,手工整理的数学常数、定理和公式)、code_api_facts.jsonl(101行,手工整理的编程API签名和琐事)、sciq.jsonl(500行,SciQ测试集的子集)和humaneval_prompts.jsonl(164行,HumanEval测试集的完整分割)。所有事实行共享统一的模式,包括问题、别名、关系、主题和来源数据集字段。数据集适用于闭卷事实评估和代码可用性测试,旨在与特定的保留语料库和遗忘语料库配对使用。数据集许可信息包括CC BY-NC 3.0(SciQ)、MIT(PopQA和HumanEval)和CC BY-SA 4.0(手工整理部分)。
The Memory-Reasoning-Split Stage D Eval Sets is an evaluation dataset constructed to measure the trade-off between domain-specific factual retention and reasoning abilities of language models following their selective forgetting of knowledge across various domains. This dataset includes five primary files: popqa_general.jsonl (1232 lines, general-domain closed-book question answering), math_facts.jsonl (100 lines, manually curated mathematical constants, theorems, and formulas), code_api_facts.jsonl (101 lines, manually curated programming API signatures and trivia), sciq.jsonl (500 lines, a subset of the SciQ test set), and humaneval_prompts.jsonl (164 lines, a full split of the HumanEval test set). All fact entries follow a unified schema that includes the fields: question, alias, relation, subject, and source dataset. This dataset is suitable for closed-book factual evaluation and code availability testing, and is intended to be paired with specific retention corpora and forgetting corpora. The dataset's licensing information includes CC BY-NC 3.0 for SciQ, MIT License for PopQA and HumanEval, and CC BY-SA 4.0 for the manually curated portions.
创建时间:
2026-04-18
原始信息汇总
Memory-Reasoning-Split Stage D Eval Sets 数据集概述
数据集基本信息
- 许可证: odc-by
- 任务类别: 问答、文本生成
- 语言: 英语
- 标签: 推理、事实回忆、消融、qwen3、内存卸载
- 数据集名称: Memory-Reasoning-Split Stage D Eval Sets
- 数据规模: 1K<n<10K
数据集描述
本数据集是用于评估在 memory_reasoning_split Stage D/E 遗忘语料消融中,各领域事实退化与推理保留之间权衡的精选闭卷评估集。所有事实行共享统一的模式,以便单一评估器进行评分。
统一模式如下:
{ "question": str, "aliases": list[str], # 任何标准化的别名匹配都计为命中 "relation": str, "topic": str, "source_dataset": str (仅 popqa_general / sciq 子集;自定义分割省略) }
文件构成
| 文件 | 行数 | 类型 | 来源 |
|---|---|---|---|
popqa_general.jsonl |
1232 | 通用领域闭卷问答 | https://huggingface.co/datasets/akariasai/PopQA 测试子集,重塑为包含别名、关系和主题的统一模式 |
math_facts.jsonl |
100 | 手动整理的闭卷事实 | 常数、定理、公式(微积分、线性代数、概率、几何、三角学、数论等) |
code_api_facts.jsonl |
101 | 手动整理的闭卷事实 | Python/NumPy/PyTorch/Pandas/JS/C++/Rust/Go/SQL API 签名以及 shell/git/HTTP 琐事 |
sciq.jsonl |
500 | https://huggingface.co/datasets/allenai/sciq test 分割的子集,经过重塑 |
转换为统一的问答模式 |
humaneval_prompts.jsonl |
164 | 完整的 https://huggingface.co/datasets/openai_humaneval test 分割 |
提示 + 规范解决方案 + 测试 + 入口点 |
设计说明
- 选择
popqa_general的原因:Stage D 的遗忘语料源自维基百科,因此最自然的“你是否破坏了通用领域事实回忆?”探针是通用主题的 PopQA(1232 行,涵盖如occupation、place_of_birth、capital等关系)。它与 https://huggingface.co/datasets/hyunseoki/popqa-mini-ner-knowledge-masks 处的 NER 掩码训练语料配对使用。
预期用途
本数据集旨在作为即插即用的评估套件,用于测量在不同遗忘语料上进行选择性遗忘训练的适配器的各领域事实保留和代码可用性。它与以下资源配对使用:
- 保留语料:https://huggingface.co/datasets/hyunseoki/qwen3-0p6b-openthoughts-self-distill-10k
- NER 掩码遗忘语料:https://huggingface.co/datasets/hyunseoki/popqa-mini-ner-knowledge-masks
- 去重索引:https://huggingface.co/datasets/hyunseoki/openthoughts3-dedup-index
所有资产均归类于 https://huggingface.co/collections/hyunseoki/qwen3-lambda-gates-knowledge-reasoning-disentanglement-69e20c8e64960042ed4c3159 集合下。
许可证与归属
- SciQ 行 © Allen AI (CC BY-NC 3.0)。
- HumanEval 行 © OpenAI (在
openai_humaneval数据集卡片中根据 MIT 许可证发布;请遵循其条款)。 - PopQA 行 © Asai et al. (MIT 许可证)。
- 手动整理的
math_facts和code_api_facts采用 CC BY-SA 4.0 许可证。
搜集汇总
数据集介绍
构建方式
在知识推理解耦研究领域,该评估集通过多源数据整合与规范化处理构建而成。其核心方法涉及从既有基准数据集中提取并重塑样本,例如将PopQA测试子集和SciQ数据集转换为统一的问答模式,同时手工编制数学与编程领域的知识条目。所有事实性数据均遵循预设的标准化模式,确保了评估过程的一致性。
特点
本数据集的一个显著特点是其跨领域覆盖与结构化设计。它不仅囊括了通用领域的事实问答,还专门集成了数学定理、编程接口签名等专业知识,并完整保留了HumanEval的代码生成评估框架。这种多维度评估结构使得研究者能够精确度量模型在不同知识域上的事实保留与推理能力之间的权衡关系。
使用方法
该数据集主要用于闭卷知识评估与代码生成能力的系统性测试。使用者可通过配套的脚本,针对经过选择性遗忘训练的适配器模型,并行执行多个评估任务。评估过程支持配置驱动,能够灵活调用不同领域的子集,并生成标准化的性能报告,从而为知识编辑与模型能力解耦研究提供可靠的量化基准。
背景与挑战
背景概述
在大型语言模型的知识与推理能力解耦研究领域,Memory-Reasoning-Split Stage D Eval Sets数据集应运而生,旨在精细化评估模型在选择性遗忘干预后的性能表现。该数据集由研究人员hyunseoklee-ai及其团队于近期构建,隶属于Qwen3 Lambda Gates知识推理解耦项目集合。其核心研究问题聚焦于探究模型在经历特定领域知识遗忘后,跨不同领域的事实性记忆保留与通用推理能力维持之间的权衡关系。通过整合PopQA通用知识问答、SciQ科学问答、人工构建的数学与代码事实以及HumanEval编程挑战等多个评估子集,该数据集为系统化衡量模型在知识编辑过程中的领域特异性退化提供了标准化基准,对推动语言模型的可控知识管理及鲁棒性评估具有重要影响力。
当前挑战
该数据集旨在解决语言模型知识编辑中一个核心挑战:如何精确量化模型在特定知识被移除后,其在不同领域的事实回忆能力与泛化推理技能所受到的影响。构建过程中的挑战则体现于多源异构数据的整合与标准化,例如需将来自PopQA、SciQ等不同结构的原始数据统一转化为具备问题、别名、关系、主题等字段的规范模式。同时,为确保评估的严谨性,人工构建的数学与代码事实子集需精心设计并收录足够多的别名以覆盖表面形式的多样性,而评估流程本身也需协调闭卷事实问答与代码生成任务等多种异构评测方式,对评估框架的通用性与自动化程度提出了较高要求。
常用场景
经典使用场景
在语言模型的知识与推理能力解耦研究中,该数据集作为核心评估工具,用于量化模型在选择性遗忘特定领域知识后,其事实性记忆与推理能力之间的权衡关系。通过封闭式问答任务,研究者能够系统测量模型在通用领域、数学、代码API及科学问题上的事实保留度,同时结合HumanEval代码生成任务评估推理功能的完整性,为模型能力分析提供多维基准。
衍生相关工作
围绕该数据集衍生的经典工作主要集中于知识-推理解耦架构与选择性遗忘算法。例如,其配套的memory_reasoning_split框架探索了通过语料库划分进行可控遗忘的方法;同时,相关工作利用该评估集验证了多种知识掩码与适配器训练策略的有效性,促进了如Lambda Gates等项目在模型能力精细调控方面的持续探索。
数据集最近研究
最新研究方向
在大型语言模型的知识与推理能力解耦研究中,Memory-Reasoning-Split Stage D Eval Sets数据集正成为评估选择性遗忘技术效果的关键工具。该数据集通过整合通用领域问答、数学定理、代码API及科学问题等多个维度的封闭式评估任务,旨在精确量化模型在特定知识遗忘后,其跨领域事实召回与推理保留之间的权衡关系。当前前沿探索聚焦于利用此类评估集,分析模型在经历Wikipedia衍生遗忘语料库干预后,如何在保持代码生成与数学解题等推理能力的同时,最小化通用事实知识的退化。这一研究方向与模型轻量化、知识编辑及安全对齐等热点议题紧密相连,为构建更可控、更高效的语言模型提供了可复现的评估基准,推动了知识管理技术在人工智能领域的深入应用。
以上内容由遇见数据集搜集并总结生成


