EstNER
收藏Hugging Face2024-09-07 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tartuNLP/EstNER
下载链接
链接失效反馈官方服务:
资源简介:
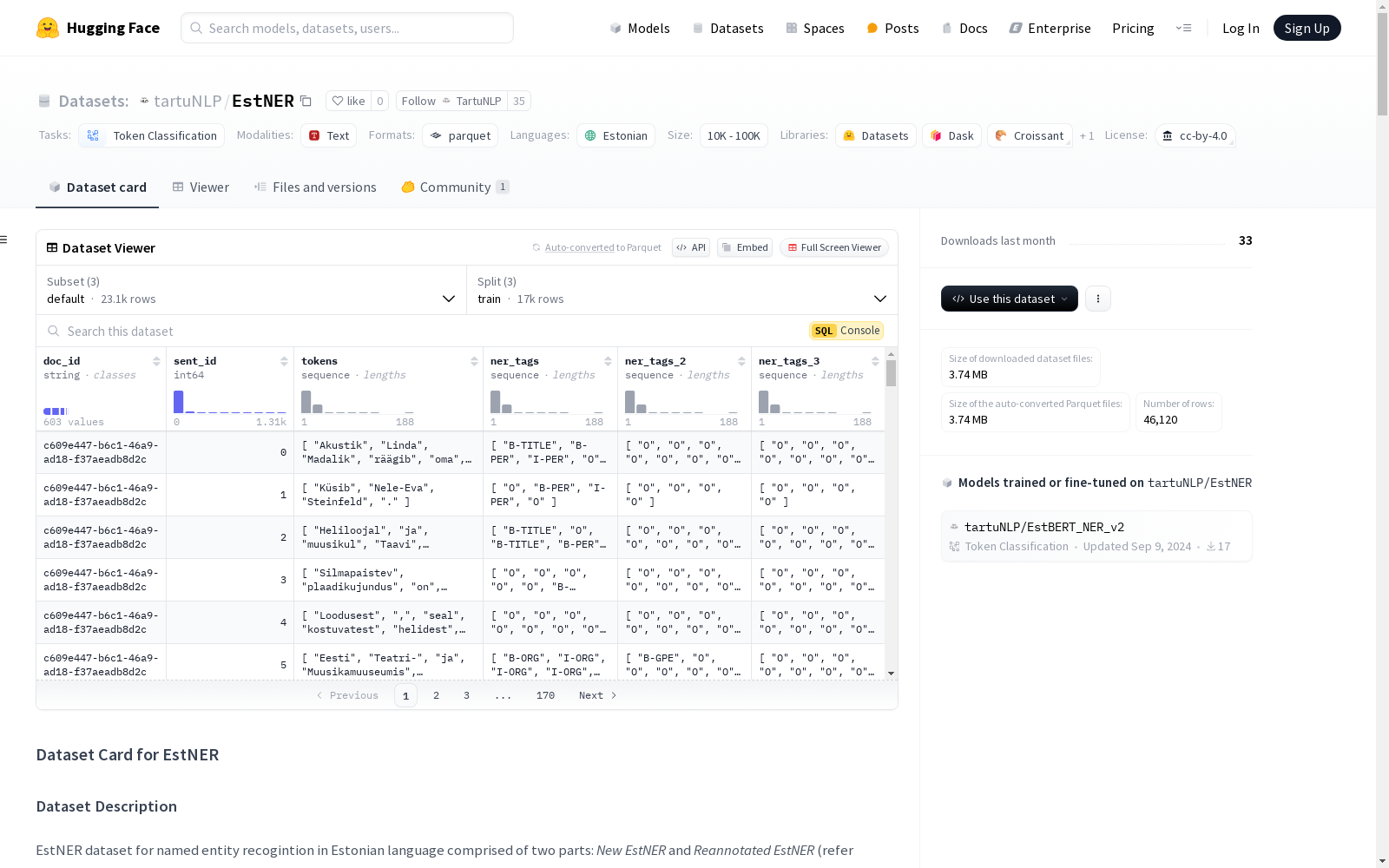
EstNER数据集用于爱沙尼亚语的命名实体识别(NER),包含两个部分:'新爱沙尼亚NER数据集'和'重新标注的爱沙尼亚NER数据集'。每个部分进一步分为训练、开发和测试集。数据集包含多达三个层次的嵌套实体的分层标注。标注的实体包括人名、地缘政治实体、地理位置、组织、产品、事件、日期、时间、头衔、货币表达和百分比。README文件还提供了每个数据集部分的统计数据,包括文档数量、句子数量、标记数量和每个层次的实体数量。此外,README文件包含用于引用的BibTeX条目。
提供机构:
TartuNLP
创建时间:
2024-09-07
搜集汇总
数据集介绍
构建方式
EstNER数据集的构建基于爱沙尼亚语的新闻和社交媒体文本,通过人工标注的方式对命名实体进行识别。数据集分为两个主要部分:新爱沙尼亚NER数据集和重新标注的爱沙尼亚NER数据集。新数据集主要来源于新闻和社交媒体文本,而重新标注的数据集则是对已有数据集进行扩展和丰富,增加了更多的实体类别。数据集的标注过程遵循严格的指南,确保标注的一致性和准确性。
特点
EstNER数据集的特点在于其丰富的实体类别和层次化标注结构。数据集涵盖了11种不同的实体类型,包括人名、地名、组织名、产品名等。此外,标注的层次化结构允许实体嵌套,最多可达三层。这种层次化标注为研究复杂实体关系提供了丰富的资源。数据集还提供了详细的统计信息,包括文档、句子、词和实体数量的分布情况,便于研究者进行深入分析。
使用方法
EstNER数据集的使用方法灵活多样,用户可以通过Hugging Face的`datasets`库加载整个数据集或单独加载其子集。默认情况下,加载的是联合版本的数据集,用户也可以通过指定配置名称加载新数据集或重新标注的数据集。加载后的数据集可以直接用于训练和评估命名实体识别模型。数据集的层次化标注结构也为研究复杂实体关系提供了便利,用户可以根据需要选择不同层次的实体进行模型训练和评估。
背景与挑战
背景概述
EstNER数据集是爱沙尼亚语命名实体识别(NER)领域的重要资源,由TartuNLP团队创建并维护。该数据集最初由Tkachenko等人于2010年提出,并在2013年进一步扩展。2023年,Sirts等人对其进行了重新标注,并引入了新的文本数据,涵盖了新闻和社交媒体领域的语料。数据集包含两个主要部分:新标注的EstNER和重新标注的EstNER,共标注了11种实体类型,包括人名、组织名、地理位置、事件、日期等。该数据集为爱沙尼亚语的自然语言处理研究提供了重要的基础支持,尤其是在多领域文本的实体识别任务中展现了其独特价值。
当前挑战
EstNER数据集在构建和应用中面临多重挑战。首先,爱沙尼亚语作为一种资源稀缺的语言,缺乏大规模的标注数据,导致模型训练时数据不足的问题尤为突出。其次,数据集中包含的实体类型多样且层次复杂,尤其是三层嵌套实体的标注增加了数据处理的难度。此外,新闻和社交媒体文本的领域差异对模型的泛化能力提出了更高要求。在构建过程中,标注一致性、实体边界的模糊性以及多义词的处理也是需要克服的技术难点。这些挑战不仅影响了数据集的标注质量,也对后续模型的性能优化提出了更高的要求。
常用场景
经典使用场景
EstNER数据集在爱沙尼亚语命名实体识别(NER)领域具有重要应用,尤其是在处理新闻和社交媒体文本时。该数据集通过提供丰富的实体标注,支持多层次实体识别,使得研究者能够深入分析爱沙尼亚语中的复杂实体结构。其经典使用场景包括训练和评估NER模型,特别是在处理嵌套实体和多层次实体时,EstNER提供了宝贵的资源。
解决学术问题
EstNER数据集解决了爱沙尼亚语命名实体识别中的多个学术研究问题。首先,它填补了爱沙尼亚语NER数据集的空白,为研究者提供了高质量的训练和测试数据。其次,通过引入多层次实体标注,该数据集支持对嵌套实体的研究,这在NER任务中是一个具有挑战性的问题。此外,EstNER还扩展了实体类型,涵盖了从人名到货币表达等多种实体,为NER模型的泛化能力提供了支持。
衍生相关工作
EstNER数据集催生了一系列相关研究工作,特别是在基于Transformer的NER模型训练和评估方面。研究者利用该数据集开发了多种先进的NER模型,并在爱沙尼亚语NER任务中取得了显著的性能提升。此外,EstNER还促进了跨语言NER研究,通过与其他语言的NER数据集结合,推动了多语言NER模型的发展。这些工作不仅提升了爱沙尼亚语NER的技术水平,也为其他低资源语言的NER研究提供了借鉴。
以上内容由遇见数据集搜集并总结生成


