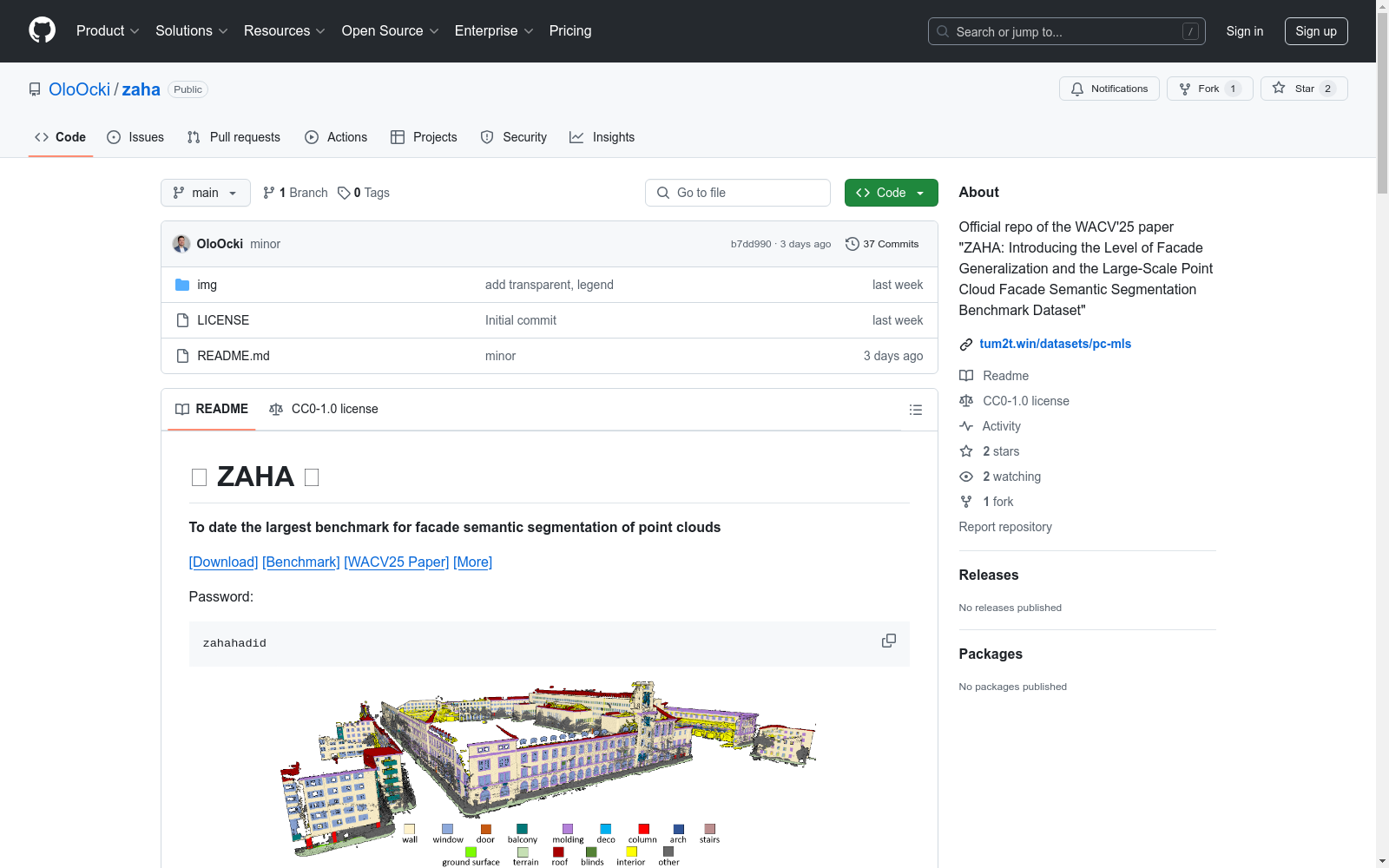
ZAHA
收藏ZAHA 数据集概述
数据集简介
- 名称: ZAHA
- 类型: 点云数据集
- 用途: 立面语义分割
- 规模: 包含 601 百万个标注点
- 特点:
- 引入 LoFG(Level of Facade Generalization),支持立面的层次化理解
- 包含多种建筑风格
- 提供本地和全球(UTM)坐标参考系统
- 文件名指向巴伐利亚官方 CityGML LoD2 建筑模型
数据下载
- 下载链接: 下载地址
- 密码: zahahadid
数据集亮点
- 601 百万标注点
- 引入 LoFG:Level of Facade Generalization,支持立面的层次化理解
- 多种建筑风格
- 本地和全球(UTM)坐标参考系统
- 文件名指向官方 CityGML LoD2 建筑模型
立面语义分割结果
LoFG3 结果
| 模型 | OA | P | R | F1 | IoU |
|---|---|---|---|---|---|
| PointNet | 59.9 | 46.1 | 42.2 | 38.7 | 26.4 |
| PointNet++ | 66.4 | 37.8 | 35.9 | 34.8 | 25.6 |
| Point Transformer | 75.0 | 52.7 | 54.7 | 52.1 | 41.6 |
| DGCNN | 71.1 | 53.6 | 45.8 | 44.5 | 33.4 |
LoFG2 结果
| 模型 | OA | P | R | F1 | IoU |
|---|---|---|---|---|---|
| PointNet | 71.9 | 69.6 | 68.1 | 68.1 | 55.8 |
| PointNet++ | 75.5 | 73.0 | 73.0 | 72.6 | 59.8 |
| Point Transformer | 78.2 | 75.8 | 76.6 | 76.1 | 63.9 |
| DGCNN | 82.6 | 80.0 | 81.8 | 80.4 | 68.5 |
引用
plain @article{wysockietalZAHA, author = {Wysocki, O. and Tan, Y. and Froech, T. and Xia, Y. and Wysocki, M. and Hoegner, L. and Cremers, D. and Holst Ch.}, title = {ZAHA: Introducing the Level of Facade Generalization and the Large-Scale Point Cloud Facade Semantic Segmentation Benchmark Dataset}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, }
plain @misc{wysocki2024zahaintroducinglevelfacade, title={ZAHA: Introducing the Level of Facade Generalization and the Large-Scale Point Cloud Facade Semantic Segmentation Benchmark Dataset}, author={Olaf Wysocki and Yue Tan and Thomas Froech and Yan Xia and Magdalena Wysocki and Ludwig Hoegner and Daniel Cremers and Christoph Holst}, year={2024}, eprint={2411.04865}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2411.04865}, }