NSFW-T2I
收藏Hugging Face2024-07-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/zxbsmk/NSFW-T2I
下载链接
链接失效反馈官方服务:
资源简介:
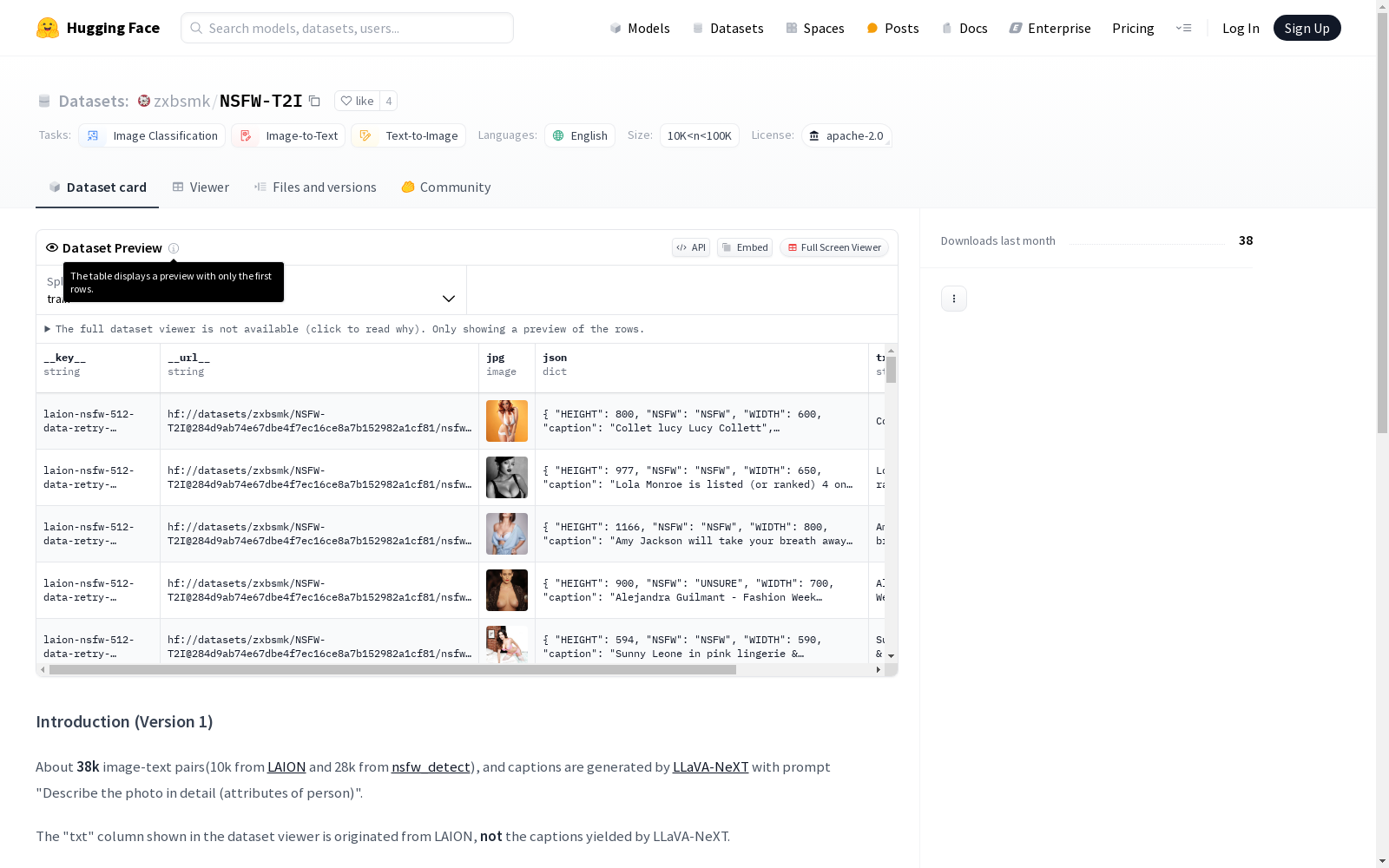
数据集包含约38,000个图像-文本对,其中10,000个来自LAION数据集,28,000个来自nsfw_detect数据集。这些图像的描述是由LLaVA-NeXT模型生成的,使用特定的提示语'Describe the photo in detail (attributes of person)'。数据集的'txt'列来自LAION,并非由LLaVA-NeXT生成的描述。
This dataset contains approximately 38,000 image-text pairs, where 10,000 pairs are sourced from the LAION dataset and the remaining 28,000 pairs are from the nsfw_detect dataset. The image descriptions were generated by the LLaVA-NeXT model using the specific prompt: "Describe the photo in detail (attributes of person)". The 'txt' column of the dataset is derived from LAION, and does not refer to the descriptions generated by the LLaVA-NeXT model.
创建时间:
2024-07-02
原始信息汇总
数据集概述
基本信息
- 许可证:Apache-2.0
- 任务类别:
- 图像分类
- 图像到文本
- 文本到图像
- 语言:英语
- 数据规模:10K<n<100K
数据内容
- 数据来源:
- 10K 来自 LAION
- 28K 来自 nsfw_detect
- 数据量:约 38K 图像-文本对
- 文本生成:使用 LLaVA-NeXT 生成描述,提示为 "Describe the photo in detail (attributes of person)"
数据集结构
- txt 列:来自 LAION,非 LLaVA-NeXT 生成的描述
代码示例
- 预训练模型:"lmms-lab/llama3-llava-next-8b"
- 模型名称:"llava_llama3"
- 设备:"cuda:2"
- 设备映射:"auto"
- 图像处理:使用
process_images函数处理图像 - 对话模板:"llava_llama_3"
- 生成文本:使用
model.generate函数生成描述文本
搜集汇总
数据集介绍
构建方式
NSFW-T2I数据集构建于两个主要来源:LAION和nsfw_detect,共计约38,000张图像-文本对。其中,10,000对来自LAION数据集,28,000对来自nsfw_detect数据集。每张图像的详细描述由LLaVA-NeXT模型生成,使用特定的提示词“详细描述照片中的人物属性”来引导模型生成文本描述。这种构建方式确保了数据集的多样性和丰富性,同时通过自动化工具提高了数据生成的效率。
使用方法
使用NSFW-T2I数据集时,研究人员可以通过加载预训练的LLaVA-NeXT模型来处理图像并生成相应的文本描述。具体步骤包括加载模型、处理图像、生成文本描述等。数据集适用于图像分类、图像到文本生成以及文本到图像生成等多种任务,特别是在需要详细人物属性描述的场合。通过这种方式,数据集能够支持复杂的视觉和语言处理研究,推动相关领域的技术进步。
背景与挑战
背景概述
NSFW-T2I数据集是一个专注于图像分类、图像到文本以及文本到图像生成任务的多模态数据集,包含了约38,000个图像-文本对。该数据集由LAION和nsfw_detect两个来源的数据整合而成,其中文本描述由LLaVA-NeXT模型生成,旨在提供详细的图像描述,特别是人物属性的描述。该数据集的创建时间不详,但其核心研究问题在于如何通过多模态数据提升图像理解与生成的准确性,尤其是在涉及敏感内容(如NSFW内容)的场景下。NSFW-T2I数据集的出现为图像生成与分类领域提供了新的研究资源,尤其是在处理敏感内容时,能够帮助模型更好地理解与生成符合伦理规范的图像描述。
当前挑战
NSFW-T2I数据集面临的挑战主要集中在两个方面。首先,在领域问题方面,该数据集旨在解决图像分类与生成任务中的敏感内容处理问题,尤其是如何在不违反伦理规范的前提下生成准确的图像描述。这一任务要求模型在理解图像内容的同时,能够识别并避免生成不适当的内容,这对模型的鲁棒性与伦理意识提出了较高要求。其次,在数据集构建过程中,挑战主要来自于数据来源的多样性与文本描述的生成质量。尽管LLaVA-NeXT模型能够生成详细的图像描述,但其生成的描述可能存在偏差或不准确性,尤其是在涉及复杂场景或多人物图像时。此外,如何确保数据集的多样性与代表性,避免数据偏差对模型性能的影响,也是构建过程中需要解决的关键问题。
常用场景
经典使用场景
NSFW-T2I数据集在图像分类和文本生成领域具有广泛的应用,尤其是在处理包含敏感内容的图像时。该数据集通过结合LAION和nsfw_detect的图像-文本对,提供了一个丰富的资源库,用于训练和评估图像到文本的生成模型。经典的使用场景包括图像描述生成、内容审核系统的开发以及多模态学习模型的训练。
解决学术问题
NSFW-T2I数据集解决了图像与文本对齐的学术研究问题,特别是在处理敏感内容时。通过提供高质量的图像-文本对,该数据集帮助研究人员更好地理解图像内容与文本描述之间的关系,进而提升图像生成和分类模型的性能。此外,该数据集还为内容审核和敏感信息过滤提供了重要的数据支持,推动了相关领域的研究进展。
实际应用
在实际应用中,NSFW-T2I数据集被广泛用于开发内容审核系统,帮助平台自动识别和过滤不适宜的内容。此外,该数据集还被用于训练多模态学习模型,提升图像描述生成和文本到图像生成的准确性。这些应用不仅提高了内容审核的效率,还为社交媒体和在线平台提供了更安全的环境。
数据集最近研究
最新研究方向
在图像生成与文本描述领域,NSFW-T2I数据集的最新研究方向聚焦于提升图像与文本对的质量与多样性。通过结合LAION和nsfw_detect两大来源的图像数据,并利用LLaVA-NeXT模型生成详细描述,该数据集为研究者提供了丰富的实验材料。当前研究热点包括优化图像分类与文本生成的联合模型,探索多模态学习在NSFW内容检测中的应用,以及提升生成描述的准确性与自然度。这些研究不仅推动了图像生成技术的发展,也为内容安全与伦理审查提供了新的解决方案。
以上内容由遇见数据集搜集并总结生成


