Corpus_DiCo
收藏Hugging Face2025-03-30 更新2025-03-31 收录
下载链接:
https://huggingface.co/datasets/datasets-CNRS/Corpus_DiCo
下载链接
链接失效反馈官方服务:
资源简介:
DiCo数据集是一个包含众多关于字典信息的语料库,例如新条目列表、删除条目或统计信息。这些信息是通过完全手动比较同一种字典的连续版本获得的,比如将2005年的小拉鲁斯字典与2006年的版本进行比较,然后再将后者与2007年的版本比较等。数据集中的信息可以用于字典条目的增减及变化分析。
创建时间:
2025-03-19
原始信息汇总
数据集概述
基本信息
- 语言: 法语 (fra)
- 许可证: CC-BY-NC-SA 4.0
- 数据集来源: DiCo
数据集配置
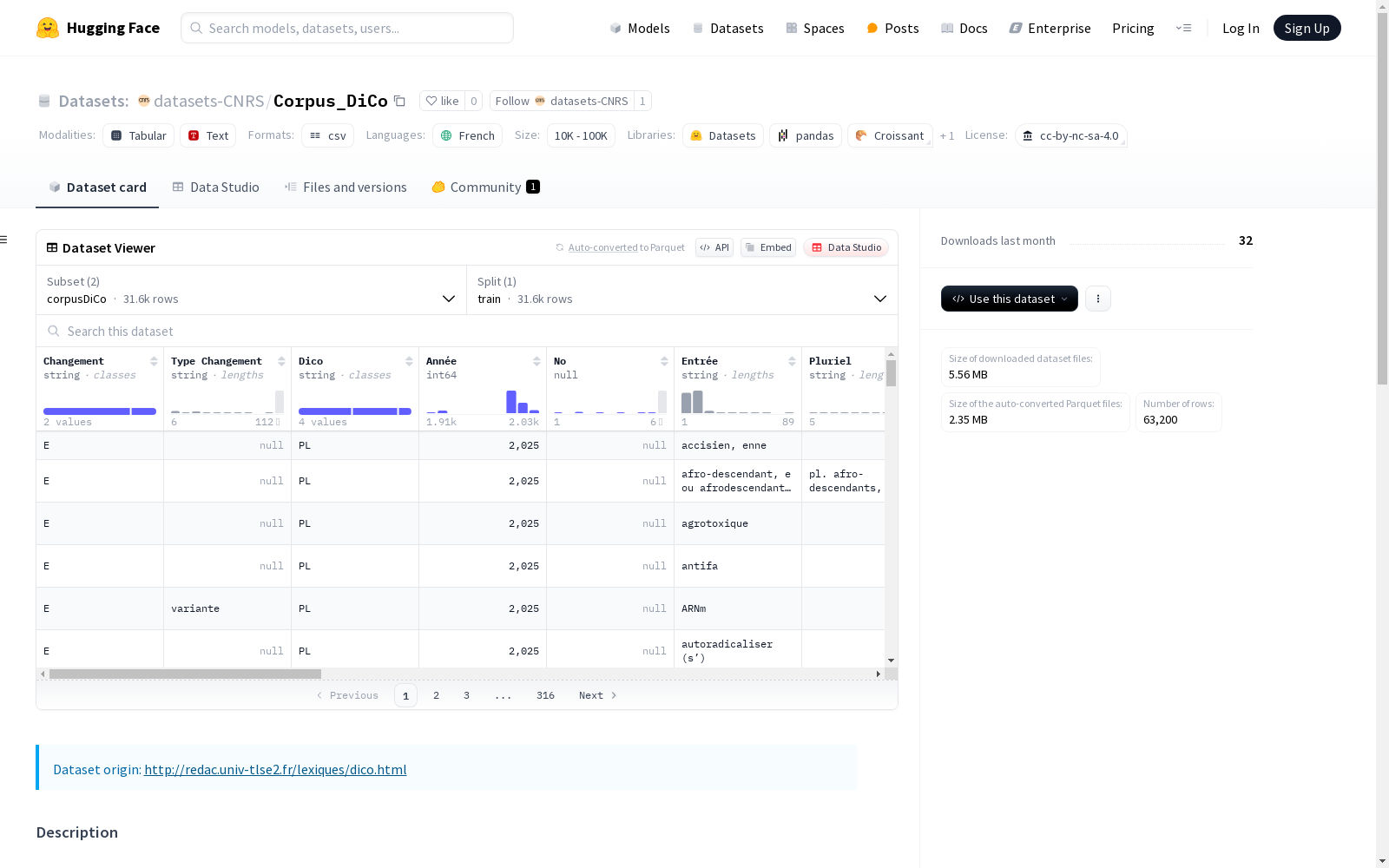
-
corpusDiCo
- 数据文件:
data/corpusDiCo_v3.6.1.csv - 分隔符:
; - 拆分:
train
- 数据文件:
-
corpusDiCo_Hausmann
- 数据文件:
data/corpusDiCo_v3.6.1_H89.csv - 分隔符:
; - 拆分:
train
- 数据文件:
描述
DiCo是一个包含大量词典信息的语料库,例如新词条列表、删除词条列表和统计数据。这些信息是通过完全手动比较同一词典的连续版本获得的,例如比较《Petit Larousse 2005》与《Petit Larousse 2006》,然后后者与2007年版比较等。比较方法的详细描述可参考以下引用的文章。
数据展示
参考文献
- Martinez, C. (2009). Une base de données des entrées et sorties dans la nomenclature dun corpus de dictionnaires: présentation et exploitation. Études de linguistique appliquée, 156(4), 499–509.
- Martinez, C. (2013). La comparaison de dictionnaires comme méthode dinvestigation lexicographique. Lexique, 21, 193–220.
- Sajous, F., & Martinez, C. (2022). Metalexicographical Investigations with the DiCo Database. International Journal of Lexicography, 35(1), 75–106. DOI
搜集汇总
数据集介绍
构建方式
Corpus_DiCo数据集通过系统化的人工对比方法构建,专注于词典编纂学的动态演变研究。研究人员采用逐版对照的方式,例如将《小拉鲁斯》2005版与2006版进行全文本比对,继而延续至后续版本,精确捕捉词条的新增、删除及修订情况。该方法在Martinez(2009,2013)的文献中有详尽阐述,确保了数据采集的严谨性与可追溯性,为词典版本学提供了可靠的微观分析基础。
使用方法
研究者可通过HuggingFace平台直接获取CSV格式的原始数据,利用分号分隔符进行字段解析。建议配合附带的学术文献(Martinez,2009,2013; Sajous&Martinez,2022)理解数据采集逻辑,其中详细阐述了词典比对方法论。数据集适用于词汇演变分析、词典编纂策略研究等场景,用户可基于时间序列数据建立词汇消长模型,或结合自然语言处理技术进行自动化词典学分析。官方文档提供的PDF说明文件包含完整的字段解释与用例指导。
背景与挑战
背景概述
Corpus_DiCo是由法国图卢兹大学研究人员Camille Martinez等人构建的词典学研究专用语料库,其雏形最早可追溯至2009年发表的奠基性研究。该数据集通过人工比对《小拉鲁斯》等法语词典的连续版本(如2005版与2006版),系统记录词条新增、删除及修订等元数据,为词典演化分析提供了首个结构化数据库。作为金属词典学研究的标杆资源,其独创的纵向对比方法论被后续多篇核心论文引用,特别是2022年发表于《国际词典学杂志》的研究进一步拓展了其在数字人文领域的应用价值。
当前挑战
该数据集首要解决的是词典版本差异量化这一传统依赖专家经验的难题,其核心挑战在于建立跨版本词条的精确映射关系,特别是处理拼写变体、词性合并等复杂情况。数据构建过程中,研究人员面临人工比对海量词条的工作量挑战,需设计特殊标记体系来区分词形相似但语义不同的条目。此外,不同词典版本间的结构异构性也导致数据标准化困难,需开发专用清洗流程确保时间序列数据的一致性。
常用场景
经典使用场景
Corpus_DiCo数据集在词典学和计算语言学领域具有重要价值,其经典使用场景包括词典编纂的演变分析和词汇动态变化研究。通过对比同一词典不同版本的条目变化,研究人员能够追踪新词的产生、旧词的消亡以及词义的演变过程。这种基于时间维度的词典对比分析,为理解语言变迁提供了独特视角。
解决学术问题
该数据集有效解决了词典学研究中的关键问题,特别是关于词典内容演变的量化分析难题。通过系统记录词典条目在不同版本间的变化,它使得研究者能够客观评估词典编纂策略的调整、社会语言变迁对词典的影响,以及词汇更新的规律性。这种基于实证的数据分析方法,显著提升了词典学研究的科学性和可重复性。
实际应用
在实际应用中,Corpus_DiCo为词典出版商提供了宝贵的质量控制工具,帮助他们评估修订效果并优化编纂流程。教育机构可利用该数据集开发词汇教学材料,展示词汇系统的动态特性。数字人文领域的研究者则将其用于构建更精准的历时语言模型,支持文本年代判定等应用。
数据集最近研究
最新研究方向
在词典学和计算语言学领域,Corpus_DiCo数据集为研究词典演变和词汇动态提供了重要资源。近年来,该数据集被广泛应用于基于时间序列的词汇变迁分析,特别是在追踪新词产生、旧词消亡以及词义演变等方面展现出独特价值。随着自然语言处理技术的进步,研究者开始将传统词典比较方法与深度学习模型相结合,利用该数据集训练词向量模型以捕捉词汇语义的历时变化。2022年Sajous和Martinez的研究进一步拓展了数据集在元词典学领域的应用,通过量化分析揭示了词典编纂中的系统性规律。这些研究不仅深化了对词典编纂实践的理解,也为数字人文研究提供了新的方法论视角。
以上内容由遇见数据集搜集并总结生成


