research-plan-gen
收藏Hugging Face2025-12-29 更新2025-12-30 收录
下载链接:
https://huggingface.co/datasets/facebook/research-plan-gen
下载链接
链接失效反馈官方服务:
资源简介:
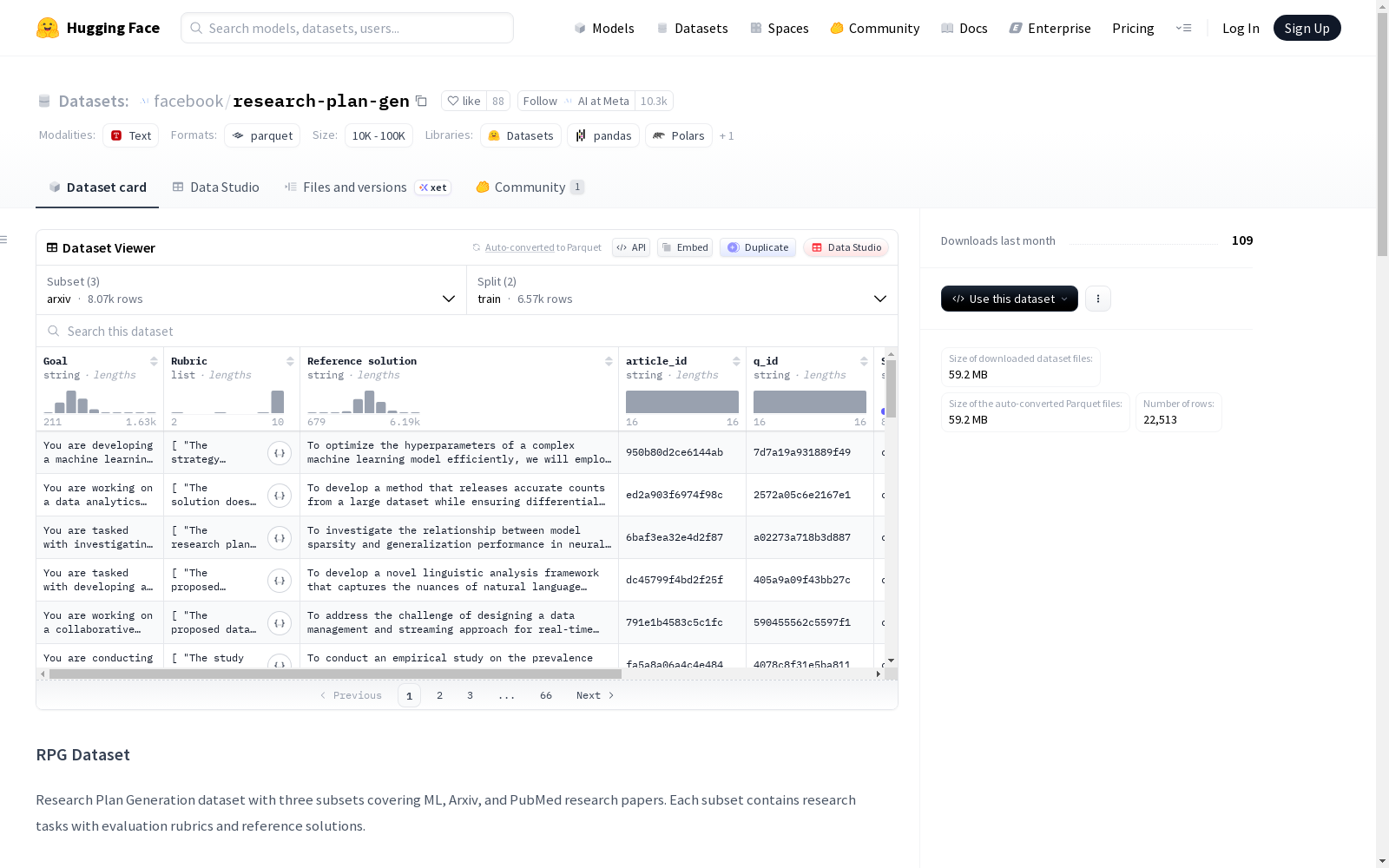
RPG数据集是一个研究计划生成数据集,包含三个子集,分别覆盖机器学习(ML)、Arxiv和PubMed研究论文。每个子集包含研究任务、评估标准和参考解决方案。数据集总共有22,513个样本,其中训练集19,868个,测试集2,645个。每个样本包含目标(Goal)、评估标准(Rubric)、参考解决方案(Reference solution)、文章ID(article_id)、问题ID(q_id)、子领域(Subdomain)、类别(Category)和标识符(Identifier)等字段。数据集主要用于基准测试,使用CC-by-NC许可证,并需遵守Llama 4许可证的要求。
提供机构:
AI at Meta
创建时间:
2025-12-28
原始信息汇总
数据集概述
基本信息
- 数据集名称: RPG Dataset (Research Plan Generation)
- 发布者: Facebook
- 访问地址: https://huggingface.co/datasets/facebook/research-plan-gen
- 许可证: CC-by-NC (仅用于基准测试目的)
- 引用文献:
@article{goel2025training, title={Training AI Co-Scientists using Rubric Rewards}, author={Goel, Shashwat and Hazra, Rishi and Jayalath, Dulhan and Willi, Timon and Jain, Parag and Shen, William F. and Leontiadis, Ilias and Barbieri, Francesco and Bachrach, Yoram and Geiping, Jonas and Whitehouse, Chenxi}, journal={arXiv preprint arXiv:2512.XXXXX}, year={2025}}
数据集构成与规模
该数据集包含三个子集,分别涵盖机器学习、Arxiv和PubMed研究论文。
数据统计
| 子集 | 训练集样本数 | 测试集样本数 | 总样本数 |
|---|---|---|---|
| ML | 6,872 | 685 | 7,557 |
| Arxiv | 6,573 | 1,496 | 8,069 |
| Pubmed | 6,423 | 464 | 6,887 |
| 总计 | 19,868 | 2,645 | 22,513 |
配置文件与数据文件
- 配置名称:
ml- 训练集路径:
ml/train/*.parquet - 测试集路径:
ml/test/*.parquet
- 训练集路径:
- 配置名称:
arxiv- 训练集路径:
arxiv/train/*.parquet - 测试集路径:
arxiv/test/*.parquet
- 训练集路径:
- 配置名称:
pubmed- 训练集路径:
pubmed/train/*.parquet - 测试集路径:
pubmed/test/*.parquet
- 训练集路径:
数据模式
每个样本包含以下字段:
- Goal (字符串): 需要完成的研究任务或目标。
- Rubric (字符串列表): 用于评估生成计划的标准列表。
- Reference solution (字符串): 参考解决方案,是Llama4-maverick生成的关于作者如何解决该研究任务的摘要。
- article_id (字符串): 源文章的唯一标识符。
- q_id (字符串): 问题/任务标识符(是目标字符串的SHA256哈希的前16个字符)。
- Subdomain (字符串): 研究子领域(仅Arxiv子集填充此字段,ML和Pubmed子集为空字符串)。
- Category (字符串): 研究类别(仅Arxiv子集和ML测试集填充此字段,ML训练集和Pubmed子集为空字符串)。
- Identifier (字符串): 用于查找原始论文的附加标识符字段。对于ML论文是Openreview论坛ID,对于Arxiv论文是Arxiv标识符,对于Pubmed论文是PMID。
数据加载方式
使用 datasets 库加载数据集:
python
from datasets import load_dataset
加载特定子集
ml_data = load_dataset("facebook/research-plan-gen", "ml") arxiv_data = load_dataset("facebook/research-plan-gen", "arxiv") pubmed_data = load_dataset("facebook/research-plan-gen", "pubmed")
访问数据划分
train_data = ml_data[train] test_data = ml_data[test]
获取样本
sample = train_data[0] print(sample[Goal])
数据示例
python { Goal: You are tasked with fine-tuning a Large Multimodal Model..., Rubric: [ The proposed method should be parameter-efficient..., The method should allow for intuitive control..., ... ], Reference solution: To fine-tune a Large Multimodal Model..., article_id: zxg6601zoc, q_id: a396a61f2da8ce60, Subdomain: , Category: , Identifier: zxg6601zoc }
重要声明
- 目标、评分标准和解决方案是Llama 4的输出,受Llama 4许可证约束(https://github.com/meta-llama/llama-models/tree/main/models/llama4)。
- 如果使用这部分数据来创建、训练、微调或以其他方式改进AI模型,并且该模型被分发或提供,则必须在任何此类AI模型名称的开头包含“Llama”。
- 从其他位置提取的第三方内容受其自身许可证的约束,您在使用该内容时可能受其他法律义务或限制的约束。
搜集汇总
数据集介绍
构建方式
在人工智能辅助科研的背景下,research-plan-gen数据集通过系统化地整合与处理来自三个核心学术领域的文献而构建。其构建过程首先从机器学习会议论文、arXiv预印本以及PubMed生物医学文献中提取原始研究任务,随后利用先进的Llama 4模型为每个任务生成对应的研究目标、评估准则及参考解决方案。数据以Parquet格式组织,并依据来源划分为ML、ArXiv和PubMed三个独立子集,每个子集均包含训练集与测试集,确保了数据的结构清晰与高效访问。
使用方法
使用该数据集时,研究人员可通过Hugging Face的datasets库便捷加载特定子集。典型流程包括导入库函数、指定配置名称以加载ML、ArXiv或PubMed数据,随后访问其训练与测试划分。数据加载后,用户可直接获取样本中的目标、准则及参考方案等字段,用于训练或评估研究计划生成模型。鉴于数据遵循CC-by-NC许可并包含大模型生成内容,使用者需注意相关许可条款,确保在符合规定的范围内将其用于学术研究与基准测试。
背景与挑战
背景概述
在人工智能与自然语言处理领域,自动生成高质量研究计划是推动科学探索自动化的关键环节。研究计划生成数据集research-plan-gen由Meta的研究团队于2025年构建,旨在通过整合机器学习、Arxiv及PubMed三大子集的学术论文数据,为模型提供结构化任务目标、评估准则与参考解决方案。该数据集的核心研究问题聚焦于如何利用大语言模型模拟科研人员的思维过程,生成逻辑严谨、可评估的研究方案,从而辅助或自动化部分科研工作流程,对学术写作、智能科研助手等方向具有显著影响力。
当前挑战
该数据集致力于解决研究计划自动生成这一复杂自然语言生成任务的挑战,其核心难点在于确保生成计划不仅符合学术规范,还需具备创新性、逻辑连贯性及可执行性。在构建过程中,研究人员面临多重挑战:首先,需从海量学术文献中精准提取研究目标并设计多维度的评估准则,这要求对领域知识有深刻理解;其次,数据标注依赖大语言模型生成参考方案,可能引入模型固有偏见或错误,影响数据质量;此外,整合多源异构数据(如OpenReview、Arxiv、PubMed)时,需统一格式并处理许可协议差异,确保数据合规性与一致性。
常用场景
经典使用场景
在人工智能驱动的学术研究领域,research-plan-gen数据集为研究计划生成任务提供了标准化的评估基准。该数据集整合了机器学习、Arxiv和PubMed三大子集,每个样本包含研究目标、评估准则和参考解决方案,使得研究人员能够系统地训练和测试模型在生成结构化研究计划方面的能力。其经典使用场景在于作为基准测试平台,用于评估大型语言模型在理解复杂学术任务、遵循多维度评估准则并生成高质量研究方案上的表现,从而推动自动化研究辅助工具的发展。
解决学术问题
该数据集有效应对了学术研究中自动化规划生成领域的若干核心挑战。它通过提供带有明确评估准则和参考解决方案的大规模数据,解决了研究计划生成任务中缺乏标准化评估框架的问题,使得不同模型之间的性能比较成为可能。同时,数据集覆盖多个学科领域,有助于探究模型在跨领域知识迁移和适应性方面的能力,为研究自动化、智能学术助手等方向提供了坚实的数据基础,促进了人工智能与科学研究交叉领域的理论探索与方法创新。
实际应用
在实际应用层面,research-plan-gen数据集能够赋能一系列智能研究工具的开发。例如,它可以用于构建学术写作助手,帮助研究人员快速草拟项目提案或实验设计;在科研教育领域,该数据集能够训练系统为学生提供研究方法和规划方面的指导;此外,在工业研发环境中,基于此数据集开发的模型可以辅助团队进行技术路线规划和创新方案构思,提升研发效率与系统性。这些应用将人工智能的推理与生成能力深度融入知识创造流程。
数据集最近研究
最新研究方向
在人工智能驱动的科研自动化领域,research-plan-gen数据集正推动研究计划生成任务的前沿探索。该数据集整合了机器学习、arXiv及PubMed三大子集,为模型提供了结构化评估框架与参考解决方案,助力开发能够自主规划复杂科研流程的智能体。当前研究聚焦于利用大语言模型理解多领域科研目标,并依据评估准则生成可执行的研究方案,这直接关联到AI科研助手与自动化科学发现的热点议题。此类工作有望显著提升科研效率,为跨学科知识合成与创新提供方法论支持,在加速科学进展方面具有深远意义。
以上内容由遇见数据集搜集并总结生成


