evals-speech-recognition
收藏Hugging Face2025-08-06 更新2025-08-07 收录
下载链接:
https://huggingface.co/datasets/DewiBrynJones/evals-speech-recognition
下载链接
链接失效反馈官方服务:
资源简介:
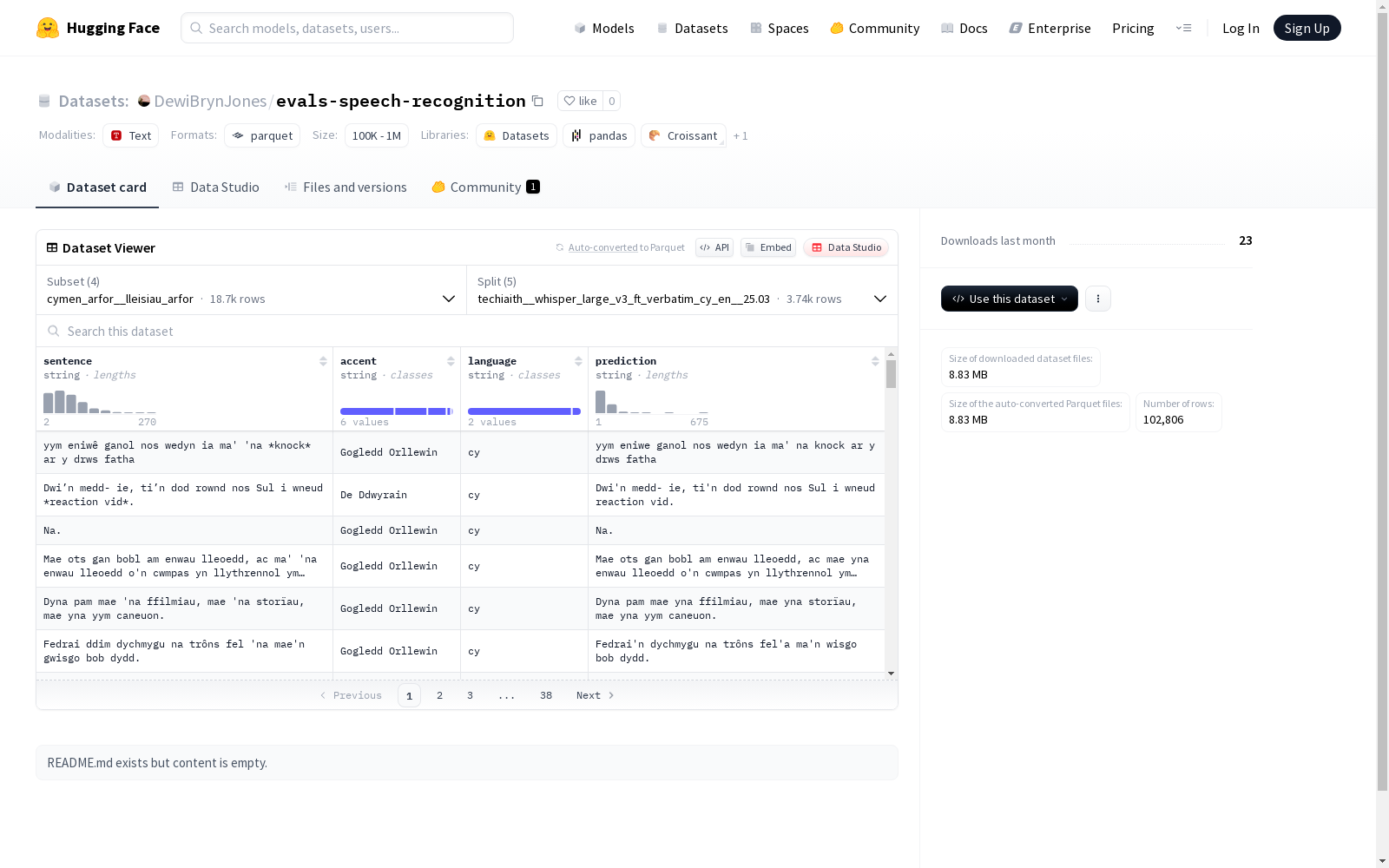
该数据集包含了四个不同的配置,每个配置都有句子、口音、语言和预测四种特征。数据集的不同部分(分割)包含了不同数量的示例和字节数。具体包括:cymen_arfor__lleisiau_arfor、techiaith__banc_trawsgrifiadau_bangor、techiaith__commonvoice_18_0_cy和techiaith__commonvoice_18_0_cy_en。
创建时间:
2025-08-06
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: evals-speech-recognition
- 数据集地址: https://huggingface.co/datasets/DewiBrynJones/evals-speech-recognition
- 配置数量: 4
配置详情
配置1: cymen_arfor__lleisiau_arfor
- 特征:
- sentence (string)
- accent (string)
- language (string)
- prediction (string)
- 分片:
- techiaith__whisper_large_v3_ft_verbatim_cy_en__25.03: 3735 个样本, 554542 字节
- techiaith__whisper_large_v3_ft_verbatim_cy_en__24.10: 3735 个样本, 548885 字节
- techiaith__kaldi_cy__main: 3735 个样本, 529991 字节
- mistralai__Voxtral_Mini_3B_2507__main: 3735 个样本, 586233 字节
- techiaith__wav2vec2_btb_cv_ft_cv_cy__24.10: 3735 个样本, 514166 字节
- 下载大小: 1670634 字节
- 数据集大小: 2733817 字节
配置2: techiaith__banc_trawsgrifiadau_bangor
- 特征:
- sentence (string)
- prediction (string)
- 分片:
- techiaith__whisper_large_v3_ft_verbatim_cy_en__25.03: 3899 个样本, 450321 字节
- techiaith__whisper_large_v3_ft_verbatim_cy_en__24.10: 3899 个样本, 450976 字节
- techiaith__kaldi_cy__main: 3899 个样本, 442881 字节
- mistralai__Voxtral_Mini_3B_2507__main: 3899 个样本, 497556 字节
- techiaith__wav2vec2_btb_cv_ft_cv_cy__24.10: 3899 个样本, 431061 字节
- 下载大小: 1609587 字节
- 数据集大小: 2272795 字节
配置3: techiaith__commonvoice_18_0_cy
- 特征:
- sentence (string)
- language (string)
- prediction (string)
- 分片:
- techiaith__whisper_large_v3_ft_verbatim_cy_en__25.03: 5386 个样本, 611648 字节
- techiaith__whisper_large_v3_ft_verbatim_cy_en__24.10: 5386 个样本, 612733 字节
- techiaith__kaldi_cy__main: 5386 个样本, 603167 字节
- mistralai__Voxtral_Mini_3B_2507__main: 5386 个样本, 631250 字节
- 下载大小: 1721286 字节
- 数据集大小: 2458798 字节
配置4: techiaith__commonvoice_18_0_cy_en
- 特征:
- sentence (string)
- language (string)
- prediction (string)
- 分片:
- techiaith__whisper_large_v3_ft_verbatim_cy_en__25.03: 10773 个样本, 1346958 字节
- techiaith__whisper_large_v3_ft_verbatim_cy_en__24.10: 10773 个样本, 1412060 字节
- techiaith__kaldi_cy__main: 10773 个样本, 1253653 字节
- mistralai__Voxtral_Mini_3B_2507__main: 10773 个样本, 1332635 字节
- 下载大小: 3823728 字节
- 数据集大小: 5345306 字节
搜集汇总
数据集介绍
构建方式
在语音识别技术快速发展的背景下,evals-speech-recognition数据集通过整合多个权威来源构建而成。该数据集包含cymens_arfor__lleisiau_arfor、techiaith__banc_trawsgrifiadau_bangor等四个子集,每个子集均采用Whisper Large V3、Kaldi等多种先进语音识别模型进行标注。数据采集过程注重语种多样性,特别关注威尔士语和英语的双语场景,通过严格的质量控制流程确保标注准确性。
特点
该数据集以其多模型对比特性脱颖而出,每个语音样本均包含原始语句和不同模型的识别结果。数据覆盖威尔士语单语及威尔士语-英语双语场景,包含口音、语言类型等丰富元数据。各子集规模均衡,样本量在3735至10773之间,为研究者提供充足的对比分析空间。不同模型预测结果的并置,为语音识别系统的性能评估创造了独特条件。
使用方法
研究者可通过HuggingFace平台直接加载数据集,利用其标准化的数据结构和丰富的元数据进行多维度分析。该数据集特别适合用于语音识别模型的横向对比研究,通过比较不同模型在相同语音样本上的表现,可深入评估模型性能。数据集中的预测结果字段可直接用于错误分析,而语言和口音标签则支持针对特定语音特征的专项研究。
背景与挑战
背景概述
evals-speech-recognition数据集由Techiaith等机构构建,专注于威尔士语(Cymraeg)及其与英语(English)双语场景下的语音识别任务。该数据集整合了多个子集,包括Common Voice 18.0的威尔士语及双语版本、Bangor转录库等,旨在解决低资源语言在自动语音识别(ASR)领域的数据稀缺问题。通过融合Whisper、Kaldi、Wav2Vec2等前沿模型的预测结果,该数据集为威尔士语语音技术的开发与评估提供了重要基准,推动了少数语言在人工智能领域的平等发展。
当前挑战
该数据集面临的核心挑战体现在两方面:在领域问题层面,威尔士语作为低资源语言,存在方言多样性、音素复杂性以及双语混合现象,导致传统ASR模型准确率显著下降;在构建过程中,需协调多模型预测差异(如Whisper与Kaldi的转录分歧),处理非标准拼写与口语化表达,同时确保不同子集(如Common Voice与Bangor库)的标注一致性。此外,数据规模受限与计算资源消耗的平衡,亦是优化多模型集成策略时的关键难点。
常用场景
经典使用场景
在语音识别领域,evals-speech-recognition数据集以其多语言和方言覆盖的特点,成为评估自动语音识别(ASR)系统性能的重要基准。该数据集包含威尔士语和英语的语音样本,涵盖了不同口音和语言变体,为研究者提供了丰富的语料库以测试模型在复杂语言环境下的表现。
衍生相关工作
基于该数据集,研究者开发了包括Whisper Large V3、Kaldi-CY在内的多个针对威尔士语的语音识别模型。这些工作不仅提升了少数语言的识别精度,还为后续研究提供了可比较的基线模型,促进了语音技术在小语种领域的应用探索。
数据集最近研究
最新研究方向
在语音识别技术快速发展的背景下,evals-speech-recognition数据集因其包含威尔士语和英语双语数据而备受关注。该数据集的最新研究方向聚焦于多语言语音识别模型的性能评估与优化,特别是在低资源语言环境下的应用。前沿研究利用Whisper、Kaldi和Voxtral等先进模型进行跨语言迁移学习,探索如何提升模型在复杂口音和方言环境下的识别准确率。随着全球对语言多样性保护的重视,该数据集在推动小语种语音技术发展方面展现出重要价值,为构建包容性更强的语音识别系统提供了关键数据支持。
以上内容由遇见数据集搜集并总结生成


