geometric-vocab
收藏Hugging Face2025-09-07 更新2025-09-08 收录
下载链接:
https://huggingface.co/datasets/AbstractPhil/geometric-vocab
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含几何词汇嵌入的统一数据集,提供了19种不同维度的嵌入(16d至4096d),并针对性能进行了优化。每个词汇标记都被嵌入到一个n维空间中的5顶点简单形中,并包含了用于计算轨迹和避免组合变体重叠的Cayley-Menger体积。
This is a unified dataset for geometric word embeddings, providing embeddings across 19 distinct dimensions ranging from 16d to 4096d and optimized for performance. Each word token is embedded into a 5-vertex simplex within an n-dimensional space, and includes the Cayley-Menger volume for calculating trajectories and avoiding overlapping of combinatorial variants.
创建时间:
2025-09-02
原始信息汇总
数据集概述
基本信息
- 数据集名称: Geometric Vocabulary Embeddings
- 许可证: Apache 2.0
- 任务类别: 特征提取
- 标签: 符号嵌入、几何嵌入、词汇表、Unicode、WordNet
- 数据规模: 10万到100万条之间
数据集结构
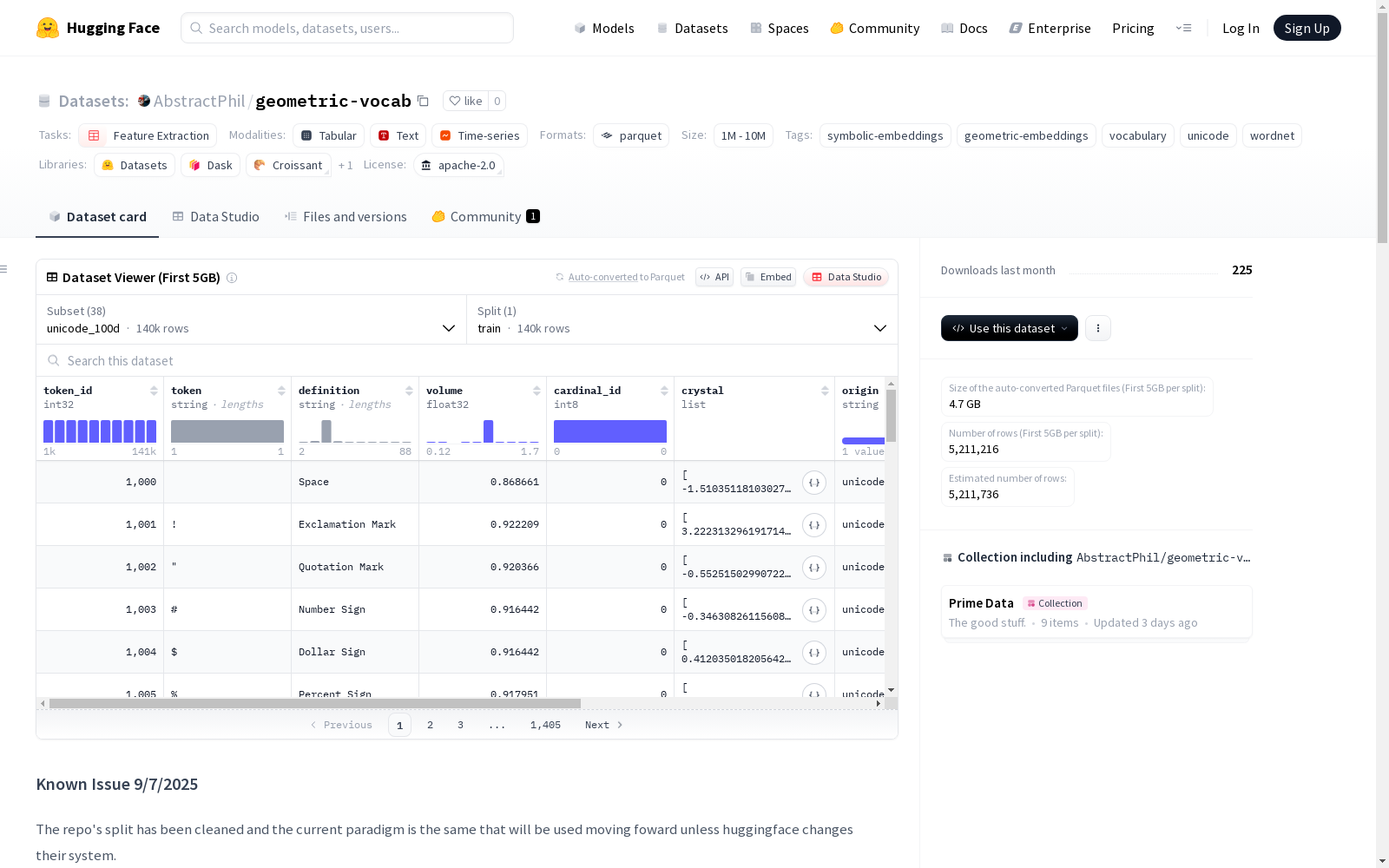
特征字段
token_id: int32类型,令牌IDtoken: string类型,令牌内容definition: string类型,定义volume: float32类型,体积值cardinal_id: int8类型,基数IDcrystal: float32序列,晶体数据origin: string类型,来源unicode_codepoint: int32类型,Unicode码点synset_id: string类型,同义词集IDlanguage: string类型,语言
配置信息
数据集包含两个主要配置系列,每个系列提供19种维度版本:
Unicode配置系列:
- unicode_16d, unicode_19d, unicode_22d, unicode_24d, unicode_25d
- unicode_29d, unicode_32d, unicode_50d, unicode_64d, unicode_100d
- unicode_128d, unicode_256d, unicode_500d, unicode_512d, unicode_1024d
- unicode_1280d, unicode_2048d, unicode_2500d, unicode_4096d
WordNet英语配置系列:
- wordnet_eng_16d, wordnet_eng_19d, wordnet_eng_22d, wordnet_eng_24d, wordnet_eng_25d
- wordnet_eng_29d, wordnet_eng_32d, wordnet_eng_50d, wordnet_eng_64d, wordnet_eng_100d
- wordnet_eng_128d, wordnet_eng_256d, wordnet_eng_500d, wordnet_eng_512d, wordnet_eng_1024d
- wordnet_eng_1280d, wordnet_eng_2048d, wordnet_eng_2500d, wordnet_eng_4096d
可用维度
提供19种不同维度版本:16d, 19d, 22d, 24d, 25d, 29d, 32d, 50d, 64d, 100d, 128d, 256d, 500d, 512d, 1024d, 1280d, 2048d, 2500d, 4096d
技术特点
- 每个令牌嵌入为n维空间中的5顶点单纯形
- 使用Cayley-Menger体积计算轨迹和增量
- 优化的分片大小:约10万行每文件
- 从191个原始文件优化为56个分片
- 避免速率限制并提高加载性能
使用方式
python from datasets import load_dataset
加载特定维度配置
ds = load_dataset("AbstractPhil/geometric-vocab", name="unicode_64d", split="train")
推荐使用流式加载
ds = load_dataset("AbstractPhil/geometric-vocab", name="unicode_64d", split=train, streaming=True)
数据格式处理
晶体数据需要从扁平数组重塑为5×n维矩阵: python import numpy as np crystal = np.array(crystal_flat).reshape(5, n_dimensions)
搜集汇总
数据集介绍
构建方式
在几何词汇表征领域,该数据集通过系统化整合Unicode字符与WordNet词汇的几何嵌入表示构建而成。采用多维空间中的五顶点单形体结构对每个词汇单元进行编码,涵盖从16维到4096维共19种不同维度配置。数据以优化的分片策略组织,将原始191个文件合并为56个标准化分片,每个分片约包含10万行数据,既避免了访问速率限制,又提升了加载效率。
特点
该数据集最显著的特征在于其多维几何嵌入的丰富性,提供19种不同维度的嵌入空间表示。每个词汇单元包含原始符号、几何晶体结构、体积度量及语义标识等多模态特征。数据集采用统一的Apache 2.0许可证,支持特征提取等机器学习任务,规模介于10万到100万样本之间,为符号嵌入研究提供了标准化基准。
使用方法
使用者可通过Hugging Face数据集库直接加载特定维度的配置,支持流式或完整加载模式。典型用法包括调用load_dataset函数指定维度名称(如unicode_64d)并选择训练分割,获取包含符号标识、扁平化晶体数组和体积值的数据项。应用时需将晶体数组重构为5×n维矩阵,结合体积指标进行几何关系分析,建议采用批处理和工作器预取优化生产环境性能。
背景与挑战
背景概述
几何词汇嵌入数据集由AbstractPhil研究团队于近年开发,专注于符号表征的几何嵌入方法研究。该数据集通过将Unicode字符和WordNet词汇映射为高维空间中的几何结构,创新性地采用五顶点单纯形表示每个词汇单元。其核心研究在于探索符号表征的几何拓扑特性,为自然语言处理领域的词汇语义表示提供了全新的数学框架,显著推动了符号嵌入与几何深度学习交叉领域的发展。
当前挑战
该数据集致力于解决符号嵌入中几何表征的维度敏感性问题,通过多维度配置支持16D到4096D的嵌入空间,但高维空间的几何性质保持与计算效率构成主要挑战。构建过程中需处理Unicode全字符集与WordNet词汇的几何映射,涉及大规模五顶点单纯形的体积计算与拓扑验证,同时需要优化海量几何数据的分片存储策略以平衡访问性能与内存效率。
常用场景
经典使用场景
在符号嵌入与几何表征研究领域,geometric-vocab数据集通过将Unicode字符和WordNet词汇映射为高维空间中的几何结构,为自然语言处理中的词汇表征提供了创新范式。该数据集最经典的使用场景是作为几何嵌入模型的训练基准,研究者利用其多维度的晶体化表征(从16维到4096维)来探索词汇在连续向量空间中的几何关系。这些嵌入通过五顶点单纯形结构呈现,能够捕捉字符与词汇的语义拓扑特性,为符号系统的数学化表征奠定了坚实基础。
解决学术问题
该数据集有效解决了传统词向量模型难以表征符号系统几何特性的学术难题。通过引入凯莱-门格尔体积计算和晶体化嵌入结构,它为研究词汇语义空间中的几何约束与拓扑关系提供了全新范式。其意义在于突破了离散符号与连续向量空间之间的表征壁垒,使得研究者能够从微分几何角度分析语言单元的数学本质,为计算语言学与代数拓扑的交叉研究开辟了新的方向,对推动符号系统的几何化表征理论发展具有深远影响。
衍生相关工作
该数据集衍生了一系列重要的研究工作,特别是在几何自然语言处理领域。基于其晶体化嵌入结构,研究者开发了新型的几何注意力机制和拓扑神经网络架构,这些工作显著推进了符号嵌入的几何约束优化理论。在跨模态学习方面,衍生出了将几何嵌入与视觉表征相结合的多模态融合模型,为符号-图像联合表征提供了新思路。此外,该数据集还催生了基于微分几何的词汇语义演化分析工具,为历史语言学和语义变化研究提供了数学化分析框架。
以上内容由遇见数据集搜集并总结生成


