Eval-Actions
收藏arXiv2026-01-27 更新2026-01-28 收录
下载链接:
https://term-bench.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
Eval-Actions是由北京大学团队构建的机器人操作评估基准数据集,旨在解决当前模仿学习领域评估可信度不足的问题。该数据集包含13,000条轨迹数据,其中创新性地整合了2,800条失败场景数据,覆盖单臂/双臂操作任务,数据来源同时包含人类遥操作和策略生成轨迹。数据集通过专家评分(EG)、排序引导偏好(RG)和思维链(CoT)三重监督信号,对动作平滑度、安全性等细粒度质量维度进行标注。其构建过程采用混合模态采集方案,包含RGB-D传感器数据和文本描述。该数据集主要应用于机器人模仿学习的可信评估领域,可有效诊断策略执行的源真实性和动作质量,为开发安全可靠的部署方案提供基准支持。
Eval-Actions is a robotic manipulation evaluation benchmark dataset developed by the Peking University team, designed to address the insufficient credibility issue in current imitation learning evaluation. This dataset contains 13,000 trajectory samples, among which 2,800 failed scenario trajectories are innovatively integrated, covering both single-arm and dual-arm manipulation tasks. The dataset’s sources include both human teleoperation trajectories and policy-generated trajectories. It annotates fine-grained quality dimensions such as motion smoothness and safety using three types of supervision signals: Expert Rating (EG), Ranking-guided Preference (RG), and Chain-of-Thought (CoT). The dataset is constructed via a hybrid-modal data collection scheme, which incorporates RGB-D sensor data and textual descriptions. Mainly applied in the field of trustworthy evaluation for robotic imitation learning, this dataset can effectively diagnose the source authenticity and motion quality of policy execution, providing benchmark support for the development of safe and reliable robotic deployment solutions.
提供机构:
北京大学
创建时间:
2026-01-27
原始信息汇总
TERM-Bench 数据集概述
数据集名称
TERM-Bench (Trustworthy Evaluation of Robotic Manipulation)
核心目标
为机器人操作建立可信赖的评估基准,解决当前评估方法在来源真实性和执行质量两个关键信任维度上的不足。
基准构成:Eval-Actions 数据集
- 数据内容:包含视觉-动作(VA)和视觉-语言-动作(VLA)策略执行轨迹、人类遥操作数据,并明确包含失败场景。
- 任务规模:覆盖150多个场景,包括单臂交互和复杂的双手协调任务。
- 数据类型:
- 原始感知数据:RGB、深度(Depth)。
- 精确运动学记录:7/14自由度关节轨迹。
- 细粒度质量雷达图:显式量化四个核心维度(成功度、平滑度、安全性、效率)。
- 监督信号:基于三个核心监督信号构建:
- 专家评分(Expert Grading, EG)
- 排名引导偏好(Rank-Guided preferences, RG)
- 思维链(Chain-of-Thought, CoT)
- 独特之处:与以训练为中心、最大化原始轨迹数量的数据集不同,Eval-Actions 最大化注释密度,独特地提供失败场景、混合轨迹来源和用于诊断评估的细粒度质量评分。
评估框架:AutoEval
一个用于可信赖评估的架构,包含两个分支:
- AutoEval Small (AutoEval-S):
- 针对专家评分和排名引导任务。
- 采用时空聚合策略将高频运动细节压缩为复合视觉标记。
- 通过监督微调(SFT)使用交叉熵损失进行优化。
- AutoEval Plus (AutoEval-P):
- 针对思维链推理任务。
- 采用组相对策略优化(GRPO)范式。
- 通过包含内容准确性和格式约束的混合奖励函数进行优化,以增强物理推理能力。
关键性能指标
- 评估精度:
- 在专家评分协议下,斯皮尔曼等级相关系数(SRCC)达到 0.81。
- 在排名引导协议下,斯皮尔曼等级相关系数(SRCC)达到 0.84。
- 来源鉴别能力:能够以 99.6% 的准确率区分策略生成的视频和遥操作视频。
数据示例与评分分析
数据集包含不同质量等级的示例,并通过思维链分析进行细粒度评分:
- 低质量(得分:2.0):运动犹豫、不流畅,任务失败。
- 中等质量(得分:5.0):运动平稳、受控,任务完成。
- 高质量(得分:9.0):运动速度适中、控制最优,执行完美。
真实性验证分析
能够基于运动学模式区分人类遥操作与策略执行:
- 人类遥操作:运动表现出自然变异和微调,具有典型的人类生物控制特征。
- 策略执行:运动与计算轨迹在数学上一致,关节运动方差低,具有刻意的、非反应性的控制特征。
策略性能排名示例
基于平均得分对策略进行排名:
- π0:平均得分 4.4702
- ACT:平均得分 3.6959
- RDT:平均得分 2.4304
搜集汇总
数据集介绍
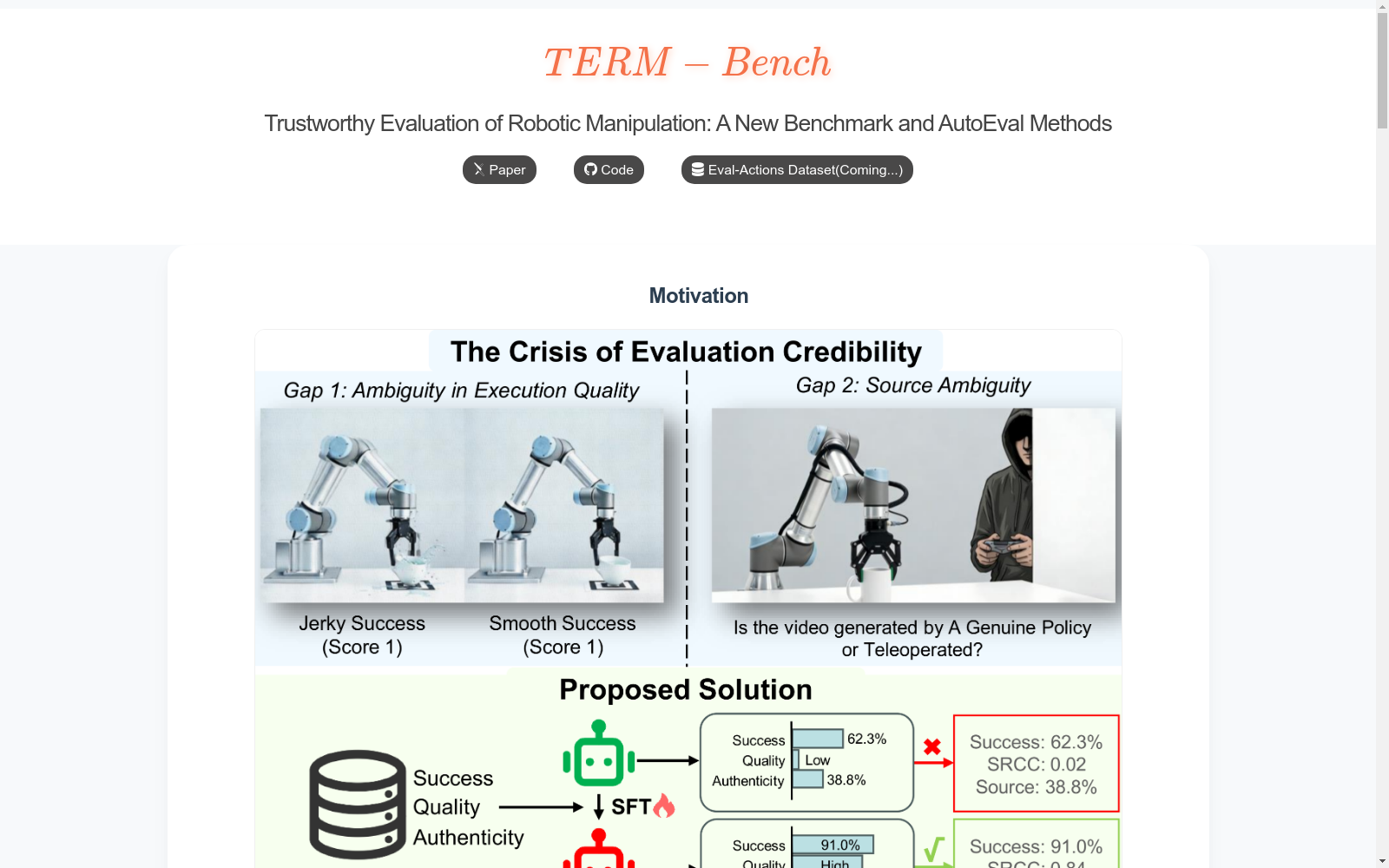
构建方式
在机器人模仿学习领域,数据集的构建传统上侧重于收集成功的人类演示轨迹,这限制了评估方法对执行质量和来源真实性的深入分析。Eval-Actions基准通过创新性的混合采集策略突破了这一局限,不仅整合了来自20名具有多元专业背景的人类操作员的遥操作数据,还系统性地纳入了多种视觉-动作与视觉-语言-动作策略生成的执行轨迹,并明确包含了失败场景。该数据集围绕专家评分、排序引导偏好和思维链三大监督信号进行结构化,总计包含超过13,000条演示片段,覆盖150余项任务,并提供了包括RGB-D记录、关节轨迹及精细化质量雷达图在内的多模态信息,为可信赖的机器人评估奠定了诊断性数据基础。
使用方法
该数据集旨在服务于机器人模仿学习策略的可信赖评估。研究者可利用Eval-Actions中带有多维度质量标注和来源标签的轨迹数据,训练或验证如AutoEval之类的自动化评估模型,这些模型能够同时预测动作质量分数、任务成功与否以及轨迹来源。具体而言,数据集中提供的专家评分和排序引导偏好可用于监督模型学习与人类判断对齐的评分能力;思维链注释则可用于增强评估模型的物理推理与解释性。通过在此基准上的测试,可以全面衡量评估框架在量化执行细微差别和鉴别行为真实性方面的效能,从而推动机器人学习向更透明、可靠的方向发展。
背景与挑战
背景概述
在机器人模仿学习领域,随着视觉-动作与视觉-语言-动作模型的飞速发展,机器人操作能力取得了显著进步。然而,评估方法的发展却相对滞后,阻碍了对这些行为进行可信评估标准的建立。为应对这一挑战,由Mengyuan Liu、Juyi Sheng等人于2026年提出了Eval-Actions基准数据集。该数据集旨在为机器人操作建立可信评估标准,其核心研究问题是解决当前评估范式中存在的执行质量模糊性与来源真实性模糊性两大缺陷。Eval-Actions创新性地整合了策略执行轨迹与人类遥操作数据,并明确包含失败场景,通过专家评分、排序引导偏好和思维链三种核心监督信号进行结构化标注。该数据集的构建标志着机器人评估从简单的二元成功率指标转向对执行平滑度、安全性和效率等多维度的细粒度行为诊断,对推动可信赖的具身智能发展具有深远影响力。
当前挑战
Eval-Actions数据集旨在解决的领域核心挑战是机器人操作的可信评估问题。具体而言,它挑战了传统评估仅依赖二元成功率的局限,致力于量化执行的细粒度质量,如动作的平滑性、安全性及效率,并需权威验证演示轨迹的来源真实性,以区分自主策略执行与人类遥操作。在数据集构建过程中,主要面临两大挑战:一是数据采集与标注的复杂性,需要整合异构的机器人本体配置、混合来源的轨迹,并为大量失败场景和成功案例提供密集的多模态信号与细粒度质量评分;二是建立客观评估标准的挑战,需设计并融合专家评分、基于遗传算法的排序引导权重优化以及思维链推理等多种监督信号,以最小化人工评估的主观性,形成与人类可信行为标准对齐的、可解释的评估基础。
常用场景
经典使用场景
在机器人模仿学习领域,评估方法的滞后性长期制约着策略可信度的科学验证。Eval-Actions数据集通过整合视觉-动作与视觉-语言-动作策略的执行轨迹,并创新性地纳入人类遥操作数据与显式失败场景,构建了支持可信度分析的新型基准。其经典使用场景体现在为机器人操作策略提供细粒度行为诊断平台,研究者可利用数据集中的专家评分、排序引导偏好与思维链标注,对策略的执行流畅度、安全性及效率进行多维量化评估,从而超越传统二元成功率指标的局限,实现从结果验证到过程分析的范式转变。
解决学术问题
该数据集致力于解决机器人模仿学习中评估可信度的核心学术难题。传统评估体系因依赖二元成功率而无法区分‘抖动成功’与‘流畅成功’,亦难以验证演示轨迹的来源真实性。Eval-Actions通过提供包含失败案例与混合来源轨迹的标注数据,系统性地应对了执行质量模糊性与来源真实性模糊性两大挑战。其意义在于首次为机器人操作建立了可量化、可验证的细粒度动作质量评估标准,将评估焦点从单一的任务完成转向对运动平滑性、安全边界与执行效率的综合考量,为客观比较不同策略的可靠性与部署安全性奠定了数据基础。
实际应用
在实际应用层面,Eval-Actions为机器人系统的开发与部署提供了关键的验证工具。在工业自动化场景中,该数据集可用于评估抓取、装配等操作的执行质量,识别可能导致设备磨损或生产中断的不稳定策略。在服务与辅助机器人领域,其有助于筛选出动作平滑、安全可靠的交互策略,提升人机共融环境下的信任度。此外,数据集支持的可信度评估框架能够集成到机器人策略的持续集成与测试流程中,作为自动化评估模块,为算法迭代与产品化提供实时的性能反馈与质量保障。
数据集最近研究
最新研究方向
在机器人操作领域,随着视觉-动作(VA)与视觉-语言-动作(VLA)模型的快速发展,模仿学习已显著提升了机器人的操作能力。然而,评估方法的滞后阻碍了可信赖评估体系的建立。当前主流范式依赖二元成功率,未能涵盖信任度的核心维度:来源真实性(区分策略行为与人工遥操作)与执行质量(如平滑度与安全性)。为填补这一空白,Eval-Actions数据集应运而生,其前沿研究聚焦于构建可信赖评估基准与自动化评估架构。该数据集创新性地整合了VA与VLA策略执行轨迹、人类遥操作数据及失败场景,并围绕专家评分、排名引导偏好和思维链三大监督信号构建。基于此,AutoEval架构通过时空聚合策略进行语义评估,并辅以运动学校准信号优化运动平滑度;同时引入群体相对策略优化范式以增强逻辑推理能力。实验表明,该框架在专家评分与排名引导协议下分别达到0.81和0.84的斯皮尔曼等级相关系数,且能以99.6%的准确率区分策略生成与遥操作视频,为机器人操作的可信赖评估设立了新标准。
相关研究论文
- 1Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods北京大学 · 2026年
以上内容由遇见数据集搜集并总结生成


