bookcorpus
收藏官方服务:
资源简介:
该数据集是对BookCorpus进行清理、去重以及与pg19数据集交叉去重后的结果。此外,数据集还针对多个基准测试进行了去污染处理,包括GLUE、SIQA、PIQA、QASC、CSQA、HellaSWAG、CONLL 2003、BLIMP、MAIN、BoolQ、WinoGrande、ANLI、ARC、RACE、MMLU、MATH、GSM8K、HumanEval、MBPP和GPQA。数据集包含16,235个样本,下载的parquet文件大小为3.3G。
本数据集是对BookCorpus进行清洗、去重,并与pg19数据集完成交叉去重后的结果。此外,本数据集还针对多项基准测试开展了去污染处理,涵盖GLUE、SIQA、PIQA、QASC、CSQA、HellaSWAG、CONLL 2003、BLIMP、MAIN、BoolQ、WinoGrande、ANLI、ARC、RACE、MMLU、MATH、GSM8K、HumanEval、MBPP及GPQA。该数据集共包含16,235个样本,可供下载的parquet文件大小为3.3GB。
创建时间:
2024-12-27
原始信息汇总
数据集概述
基本信息
- 数据集名称: BookCorpus
- 许可证: MIT
- 数据集来源: BookCorpus
- 处理方式: 经过清理、近去重处理,并与pg19数据集进行了交叉去重处理。
去污染处理
该数据集已针对以下基准测试进行了去污染处理,基于n-gram重叠:
- GLUE: SST-2、CoLA、QQP、WNLI、RTE、QNLI、MNLI的开发集;MPRC的测试集
- SIQA、PIQA、QASC、CSQA、HellaSWAG: 所有开发集
- CONLL 2003
- BLIMP
- MAIN
- BoolQ: 开发集
- WinoGrande: 开发集
- ANLI: 测试集
- ARC easy和challenge: 测试集
- RACE middle和high: 测试集
- MMLU: 开发集、验证集和测试集
- MATH、GSM8K: 测试集
- HumanEval: 测试集
- MBPP: 所有974个问题
- GPQA: diamond
数据集规模
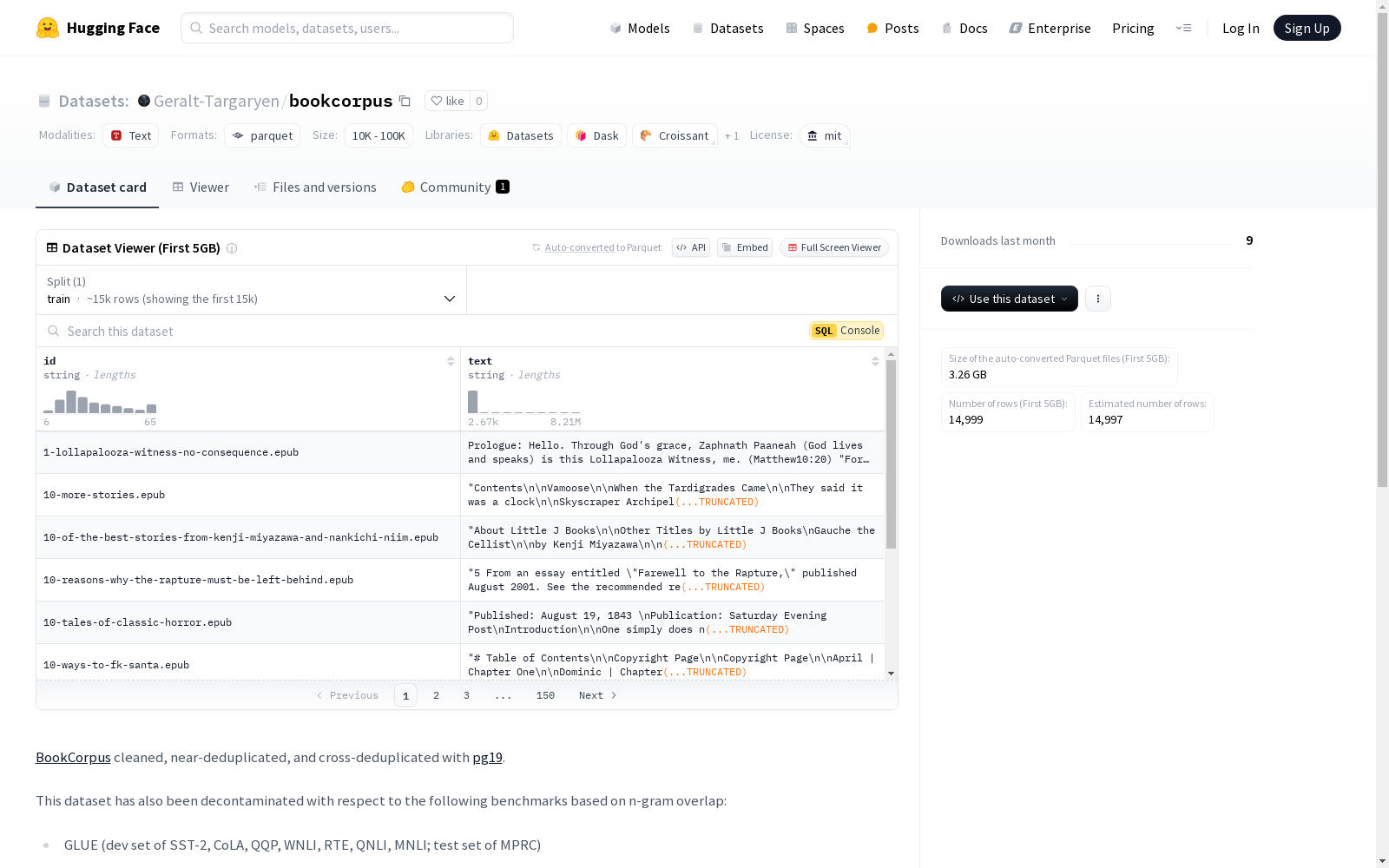
- 样本数量: 16,235
- 下载的parquet文件大小: 3.3G
搜集汇总
数据集介绍
构建方式
BookCorpus数据集通过清理、近重复删除以及与pg19数据集进行交叉去重的方式构建。该数据集还针对多个基准测试进行了去污染处理,确保与GLUE、SIQA、PIQA等基准测试集在n-gram重叠上的独立性。这一过程不仅提升了数据的纯净度,还增强了其在自然语言处理任务中的适用性。
特点
BookCorpus数据集包含16,235个样本,下载的parquet文件大小为3.3G。其显著特点在于经过严格的去重和去污染处理,确保了数据的高质量和低冗余。此外,该数据集覆盖了广泛的自然语言处理任务基准,能够为模型训练和评估提供多样化的文本资源。
使用方法
BookCorpus数据集适用于自然语言处理领域的研究和开发,特别是在预训练语言模型的训练中。用户可以通过HuggingFace平台直接下载该数据集,并利用其提供的parquet文件进行数据处理。该数据集还可用于评估模型在多种基准测试上的表现,确保模型在不同任务中的泛化能力。
背景与挑战
背景概述
BookCorpus数据集自2015年由Yukun Zhu等人首次提出,旨在为自然语言处理(NLP)领域提供大规模的文本数据资源。该数据集主要来源于未出版的书籍,涵盖了广泛的文学类型和主题,为语言模型的训练提供了丰富的语料。BookCorpus的创建不仅推动了语言模型的发展,还在文本生成、情感分析、机器翻译等多个NLP任务中发挥了重要作用。近年来,该数据集经过多次清理和去重,进一步提升了其质量和适用性,成为NLP研究中的重要基准之一。
当前挑战
BookCorpus数据集在构建和应用过程中面临多重挑战。首先,数据集的去重和清理工作极为复杂,尤其是在与pg19等数据集进行交叉去重时,需要确保数据的独特性和多样性。其次,数据集的去污染工作涉及多个基准测试,如GLUE、SIQA等,要求对数据进行精细的n-gram重叠分析,以避免数据泄露问题。此外,数据集的规模和质量平衡也是一个重要挑战,如何在保持数据多样性的同时,确保数据的准确性和一致性,是构建过程中需要解决的关键问题。这些挑战不仅影响了数据集的构建效率,也对后续的模型训练和评估提出了更高的要求。
常用场景
经典使用场景
BookCorpus数据集广泛应用于自然语言处理领域,特别是在语言模型的预训练阶段。由于其包含大量的小说文本,这些文本具有丰富的语言结构和多样的表达方式,因此非常适合用于训练能够理解和生成自然语言的模型。研究人员通常利用BookCorpus来提升模型在文本生成、文本分类和情感分析等任务中的表现。
衍生相关工作
基于BookCorpus数据集,许多经典的自然语言处理模型得以开发,如BERT、GPT等。这些模型在多个基准测试中取得了显著的成绩,推动了自然语言处理技术的进步。此外,BookCorpus还激发了大量关于文本去重、数据清洗和模型预训练的研究,进一步丰富了该领域的研究内容。
数据集最近研究
最新研究方向
在自然语言处理领域,BookCorpus数据集因其广泛的应用和高质量的内容而备受关注。近年来,该数据集在语言模型的预训练和微调中发挥了重要作用,特别是在去重和去污染处理方面取得了显著进展。通过与pg19数据集的交叉去重,BookCorpus进一步提升了数据的纯净度,减少了冗余信息对模型训练的干扰。此外,该数据集在多个基准测试中的去污染处理,如GLUE、SIQA、PIQA等,确保了其在各类任务中的可靠性和有效性。这些改进不仅增强了模型在复杂任务中的表现,也为研究者提供了更加精确的实验数据,推动了自然语言处理技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


