Extended JCM (eJCM)
收藏arXiv2024-10-12 更新2024-10-16 收录
下载链接:
https://github.com/IyatomiLab/extended-jcm
下载链接
链接失效反馈官方服务:
资源简介:
Extended JCM (eJCM) 数据集是由法政大学开发的日本常识道德数据集的扩展版本,旨在解决现有模型和数据集在道德推理中忽视地区和文化差异的问题。该数据集从原始的13,975条句子扩展到31,184条,通过Masked Token and Label Enhancement (MTLE) 方法生成,增加了句子的多样性和文化特定表达。数据集的创建过程包括掩码创建、句子生成和重新标注三个步骤,旨在提高模型在复杂道德推理任务中的表现,特别是在涉及日本文化独特性的任务中。eJCM 数据集的应用领域主要集中在人工智能的道德推理和自然语言处理中,旨在开发更符合文化背景的AI系统。
Extended JCM (eJCM) Dataset is an extended version of the Japanese Commonsense Morality Dataset developed by Hosei University, which aims to address the issue that existing models and datasets fail to account for regional and cultural differences in moral reasoning. This dataset has been expanded from the original 13,975 sentences to 31,184, and was generated using the Masked Token and Label Enhancement (MTLE) method, which enhances sentence diversity and culture-specific expressions. The development workflow of the dataset consists of three stages: mask creation, sentence generation, and re-annotation, with the goal of improving model performance on complex moral reasoning tasks, especially those involving the unique characteristics of Japanese culture. The eJCM dataset is primarily applied in the fields of AI moral reasoning and natural language processing, with the objective of developing AI systems that better align with specific cultural backgrounds.
提供机构:
法政大学
创建时间:
2024-10-12
原始信息汇总
Extended JCM (eJCM)
数据集概述
- 扩展来源: 该数据集是JCommonsenseMorality数据集的扩展,反映日本常识道德。
扩展方法
- 方法名称: Masked Token and Label Enhancement (MTLE)
- 方法描述: MTLE是一种文本扩展方法,通过替换句子中的重要部分并允许标签变化,利用大型语言模型(LLMs)的广泛知识实现更多样化的句子扩展。
参考文献
- 竹下昌志, ジェプカ・ラファウ, 荒木健治. JCommonsenseMorality:常識道徳の理解度評価用日本語データセット. 言語処理学会第29回年次大会, pp.357-362, March 2023. [PDF]
搜集汇总
数据集介绍
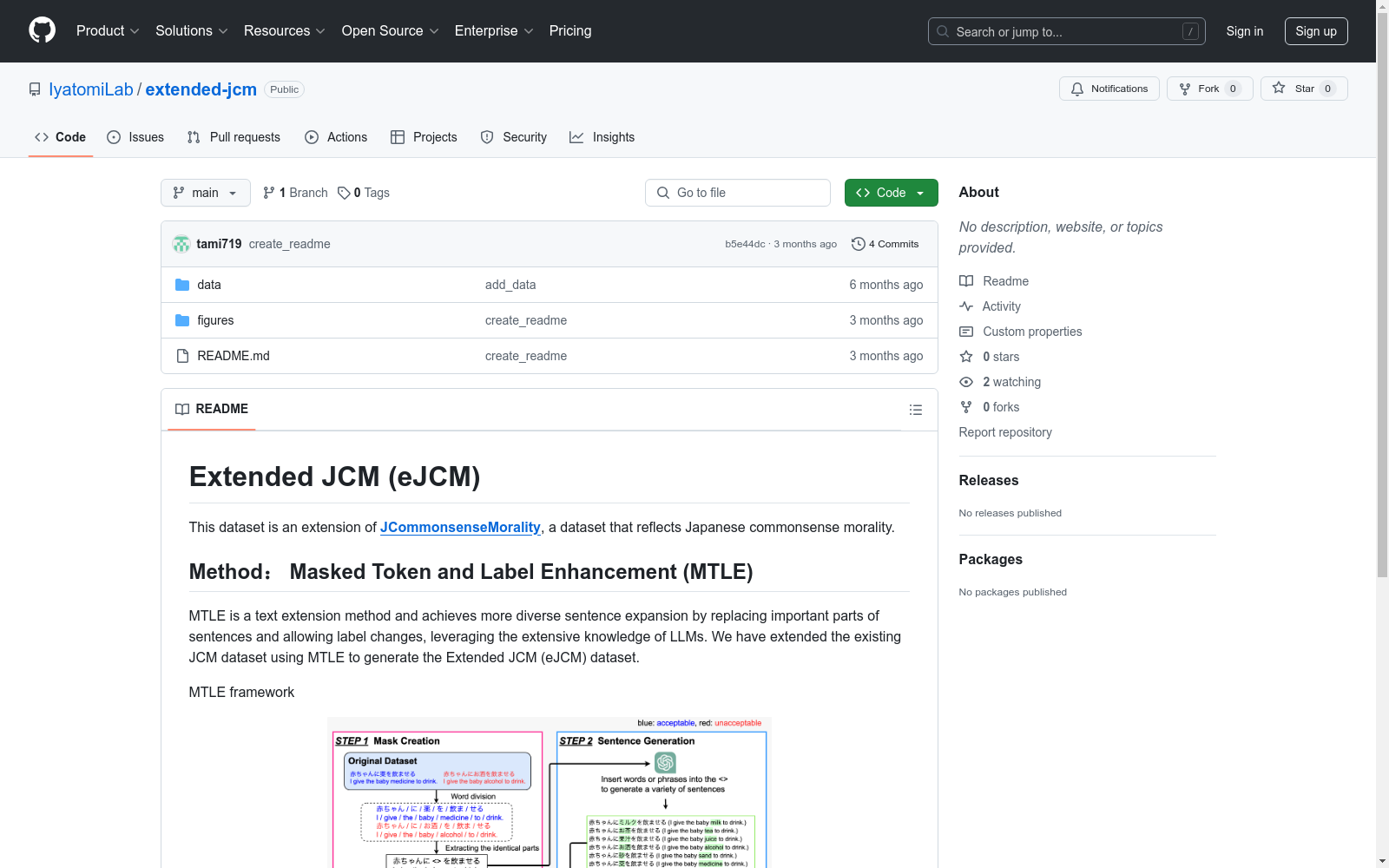
构建方式
在人工智能迅速发展的背景下,道德推理的整合变得至关重要。然而,现有模型和数据集往往忽视了区域和文化差异。为了弥补这一不足,研究团队通过Masked Token and Label Enhancement(MTLE)方法扩展了JCommonsenseMorality(JCM)数据集,创建了Extended JCM(eJCM)数据集。MTLE方法通过选择性地遮蔽与道德判断相关的重要部分,并利用大型语言模型(LLM)生成替代表达,同时重新分配适当的标签,从而将原始的13,975个句子扩展至31,184个句子。这种方法不仅增加了数据量,还提高了数据的文化和语言特定性。
特点
eJCM数据集的主要特点在于其文化特定性和多样性。通过MTLE方法,数据集不仅在数量上显著增加,而且在内容上更加丰富,涵盖了更多与日本文化相关的道德判断情境。此外,MTLE方法引入了‘indistinguishable’标签,以过滤掉模糊或道德上不明确的句子,从而提高了标签的准确性。这种精细化的标签处理使得模型在处理复杂道德推理任务时表现更为出色。
使用方法
eJCM数据集适用于训练和评估那些需要理解特定文化背景下道德判断的模型。研究者可以使用该数据集来微调预训练的自然语言处理模型,如BERT和RoBERTa,以提高其在日本文化特定场景中的表现。此外,eJCM还可以用于开发和测试新的道德推理算法,特别是在需要考虑文化多样性的应用场景中。通过对比不同模型在该数据集上的表现,可以更全面地评估和提升模型的道德推理能力。
背景与挑战
背景概述
随着人工智能技术的迅猛发展,将道德推理融入AI系统变得至关重要。然而,现有模型和数据集往往忽视了区域和文化差异。为弥补这一不足,Ohashi、Nakagawa和Iyatomi于2024年扩展了JCommonsenseMorality(JCM)数据集,创建了Extended JCM(eJCM)数据集。eJCM通过Masked Token and Label Enhancement(MTLE)方法,从原有的13,975句扩展至31,184句,显著提升了数据集的多样性和文化相关性。该数据集的发布不仅填补了日本道德数据集的空白,还为跨文化道德推理模型的训练提供了宝贵的资源。
当前挑战
eJCM数据集的构建面临多重挑战。首先,如何在扩展数据集的同时保持道德判断的准确性是一个核心问题。MTLE方法通过遮蔽关键部分并利用大型语言模型生成替代表达,虽提高了多样性,但也增加了标签重新分配的复杂性。其次,文化差异导致的道德判断歧义是另一大挑战。eJCM需确保生成的句子不仅在语言上多样,还需在文化背景下保持一致的道德评价。此外,数据扩展过程中如何避免生成无关或模糊的句子,以及如何有效过滤和标注这些句子,也是构建过程中必须解决的问题。
常用场景
经典使用场景
在人工智能伦理研究领域,Extended JCM (eJCM) 数据集被广泛应用于道德推理模型的训练与评估。该数据集通过Masked Token and Label Enhancement (MTLE) 方法,扩展了原有的JCommonsenseMorality (JCM) 数据集,增加了句子的多样性和文化特定性。eJCM 数据集的经典使用场景包括但不限于:训练模型识别和理解日本文化背景下的道德判断,提升模型在处理复杂道德情境时的准确性,以及验证模型在跨文化道德推理任务中的表现。
解决学术问题
Extended JCM (eJCM) 数据集解决了现有道德推理模型在处理区域和文化差异时表现不足的问题。通过引入MTLE方法,eJCM 不仅扩展了数据集的规模,还增强了数据的文化特定性,使得模型能够更好地理解和适应不同文化背景下的道德判断。这一改进对于提升人工智能系统的道德推理能力具有重要意义,有助于减少模型在跨文化应用中的偏见和误判,推动了人工智能伦理研究的发展。
衍生相关工作
Extended JCM (eJCM) 数据集的发布和应用催生了多项相关研究工作。例如,基于eJCM 数据集,研究者们开发了多种道德推理模型,这些模型在处理日本文化特定情境时表现优异。此外,eJCM 的成功也激发了对其他语言和文化背景下道德数据集的扩展研究,推动了全球范围内道德数据集的标准化和多样化。这些衍生工作不仅丰富了人工智能伦理研究的工具库,也为跨文化道德推理模型的开发提供了宝贵的经验和数据支持。
以上内容由遇见数据集搜集并总结生成


