有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
名称: Flickr-Faces-HQ Dataset (FFHQ)
描述: FFHQ是一个高质量的人脸图像数据集,包含70,000张分辨率为1024×1024的PNG格式图片。该数据集在年龄、种族和图像背景方面具有显著的多样性,并涵盖了眼镜、太阳镜、帽子等配饰。数据来源于Flickr网站,经过自动对齐和裁剪处理。
用途: 主要用于生成对抗网络(GAN)的研究,不应用于面部识别技术的开发或改进。
download_ffhq.py脚本,用于自动下载和验证数据集文件。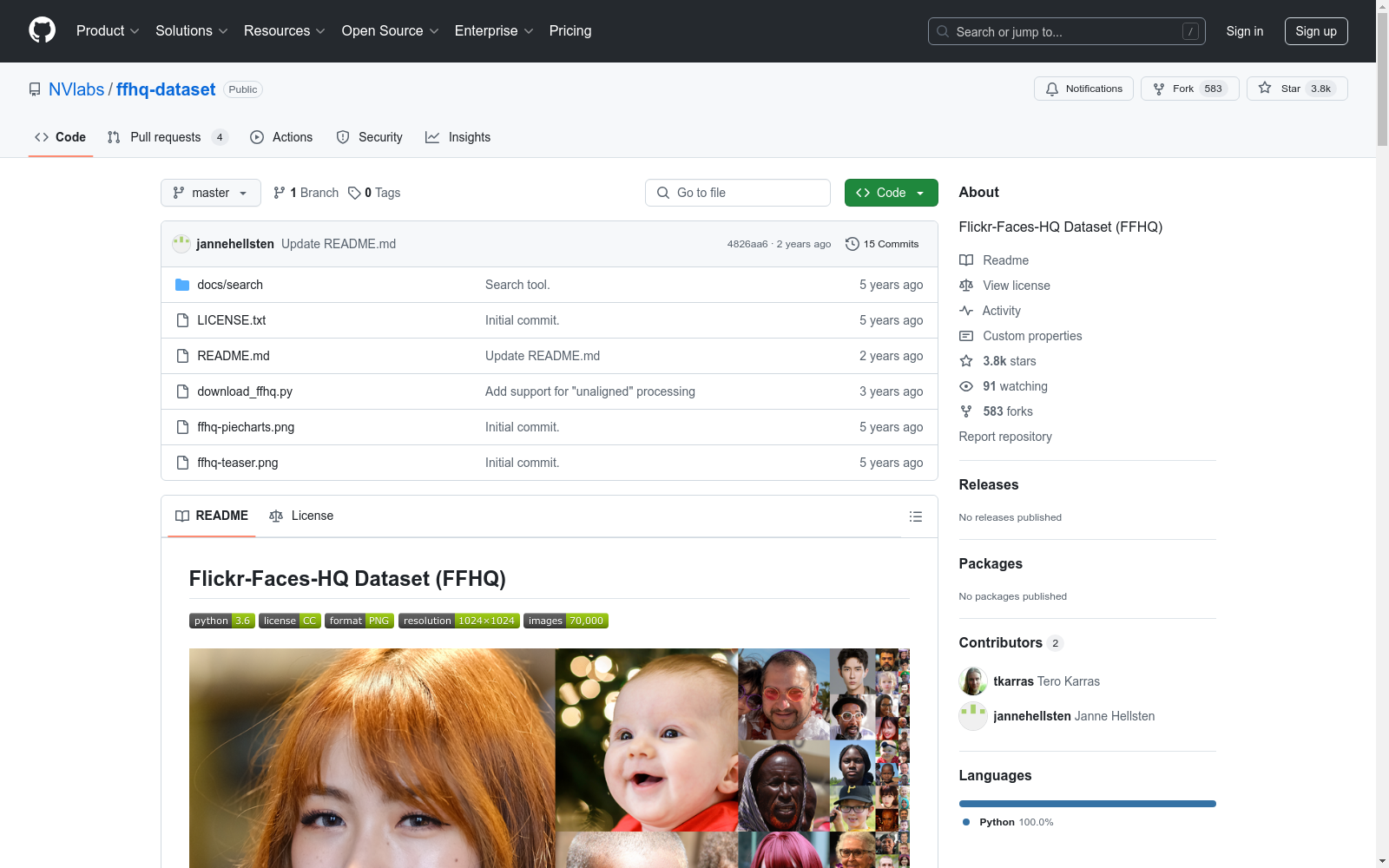
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
UAVDT
UAVDT数据集由中国科学院大学等机构创建,包含约80,000帧从10小时无人机拍摄视频中精选的图像,覆盖多种复杂城市环境。数据集主要关注车辆目标,每帧均标注了边界框及多达14种属性,如天气条件、飞行高度、相机视角等。该数据集旨在推动无人机视觉技术在不受限制场景下的研究,解决高密度、小目标、相机运动等挑战,适用于物体检测、单目标跟踪和多目标跟踪等基础视觉任务。
arXiv 收录
中国车牌识别数据集(7类,33万张)
这是一个高质量、平衡的中国车牌识别数据集,包含了33万张各类中国车牌的图片。数据集经过精心设计,确保了图像质量的优秀和大部分各类车牌类型的平衡分布。这个数据集非常适合用于训练和评估车牌识别模型。
魔搭社区 收录
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录
CE-CSL
CE-CSL数据集是由哈尔滨工程大学智能科学与工程学院创建的中文连续手语数据集,旨在解决现有数据集在复杂环境下的局限性。该数据集包含5,988个从日常生活场景中收集的连续手语视频片段,涵盖超过70种不同的复杂背景,确保了数据集的代表性和泛化能力。数据集的创建过程严格遵循实际应用导向,通过收集大量真实场景下的手语视频材料,覆盖了广泛的情境变化和环境复杂性。CE-CSL数据集主要应用于连续手语识别领域,旨在提高手语识别技术在复杂环境中的准确性和效率,促进聋人与听人社区之间的无障碍沟通。
arXiv 收录