TimeAware
收藏TimeAware: Benchmarking Time-Sensitive Fact Recall in Large Language Models
概述
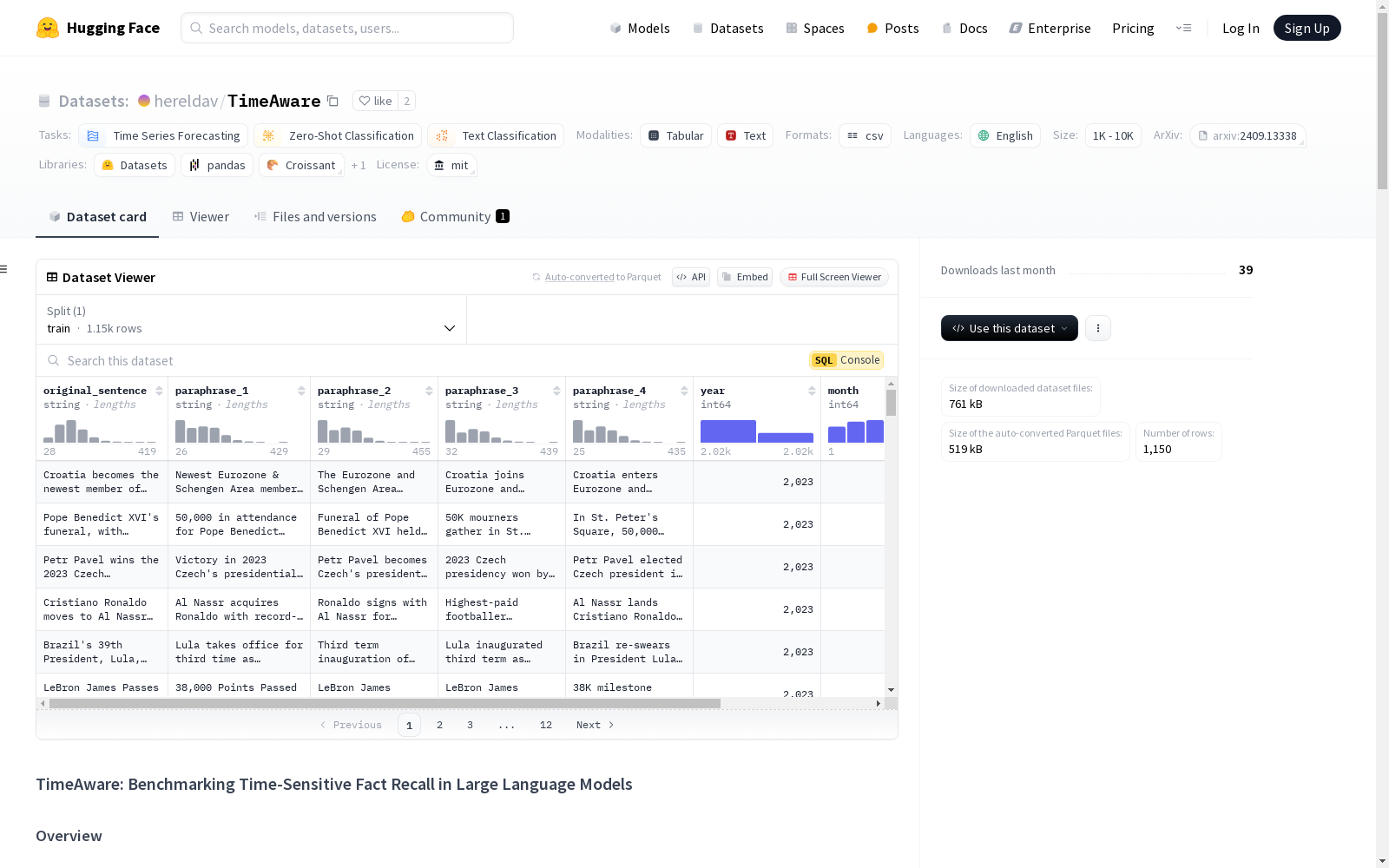
TimeAware 是一个新颖的数据集,旨在严格测试大型语言模型(LLMs)处理时间敏感事实的能力。该基准提供了一种系统的方法来衡量模型如何将其知识与正确的时间上下文对齐,填补了当前评估方法中的关键空白,并为未来模型的实际应用改进提供了宝贵的工具。
关键特性
- 时间特定评估:事件标记有确切的月份和年份,允许精确评估模型随时间跟踪信息的能力。
- 多样领域:事件涵盖广泛领域,从政治到科学,确保全面覆盖现实世界知识。
- 多重释义:每个事件都配对有四个释义,测试模型对重述事实和措辞变化的鲁棒性。
- 全球范围:数据涵盖关键的全球事件,确保数据集反映广泛的文化和地理背景。
- 现实应用:设计用于虚拟助手、事实核查系统和时间问题回答等应用,其中时间依赖的准确性至关重要。
快速开始
可以通过 Hugging Face 的 datasets 库轻松加载数据集:
python from datasets import load_dataset ds = load_dataset("hereldav/TimeAware")
示例数据结构:
json { "event": "Geoffrey Hinton, the Godfather of AI, resigned from Google amidst AI concerns...", "paraphrase_1": "AI concerns lead Godfather Geoffrey Hinton to leave Google...", "year": 2023, "month": 5, "category": "Science & Technology" }
数据集描述
TimeAware 旨在测试模型对时间绑定事实的知识——其中“何时”与“什么”同样重要。每个事件都与以下内容相关联:
- 原始事件:一个精确日期标记的现实世界事件。
- 四个释义:测试模型对措辞变化的弹性的替代表述。
- 标签:事件的确切年份和月份,用于时间敏感的回忆。
- 类别:事件的领域(例如,政治、科学、犯罪)。
数据集包括来自可信来源(如 BBC、Reuters 和 Nature)的 1,150 个事件,这些事件经过交叉验证以确保事实准确性和时间精确性。
结构
json { "event": "...", "paraphrase_1": "...", "paraphrase_2": "...", "paraphrase_3": "...", "paraphrase_4": "...", "year": 2023, "month": 5, "category": "Science & Technology" }
基准测试结果
在 TimeAware 上的初步评估显示,较大的模型在理解和回忆时间敏感事实方面具有明显优势。以下是几个最先进模型的基准测试结果:
| 模型 | Top-1 准确率 | Top-3 准确率 | 释义稳定性 |
|---|---|---|---|
| Llama 3.1 70B | 39.74% | 66.52% | 65.97% |
| Gemma-2 27B | 30.96% | 55.74% | 63.13% |
| Mistral-Nemo 12.2B | 17.83% | 39.48% | 61.71% |
观察结果
- 较大的模型(例如 Llama 3.1 70B)在准确性和释义稳定性方面表现显著更好。
- 在合成数据(例如 Phi 系列)上训练的模型由于缺乏现实世界的时间基础而表现不佳。
引用
如果使用 TimeAware,请引用相关的研究论文:
@inproceedings{herel2025timeaware, title={Time Awareness in Large Language Models: Benchmarking Fact Recall Across Time}, author={David Herel and Vojtech Bartek and Tomas Mikolov}, booktitle={arxiv 2025}, year={2025} }