xiang2021-spcas9
收藏Hugging Face2026-01-30 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/saiden89/xiang2021-spcas9
下载链接
链接失效反馈官方服务:
资源简介:
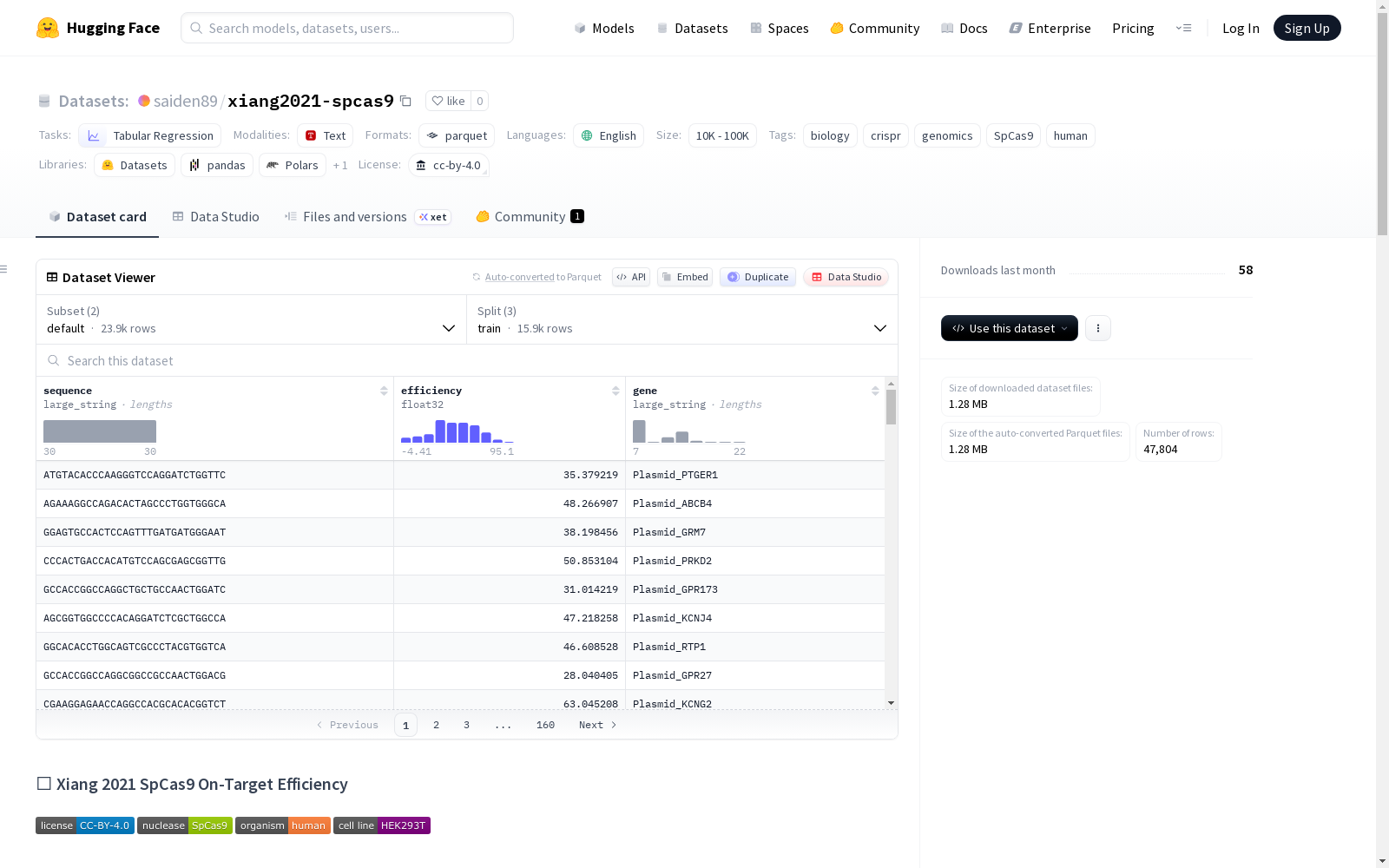
Xiang 2021 SpCas9 On-Target Efficiency 数据集是一个用于预测SpCas9在人类细胞系HEK293T中靶向效率的数据集。该数据集合并了Luo 2020和Kim 2019的研究数据,包含30mer序列及其测量的CRISPR-Cas9切割效率。数据集总共有23,902个样本,分为五个折叠(fold_1至fold_5)和一个测试集(test)。每个折叠包含约3,984个样本,测试集包含3,983个样本。数据效率值范围从0.0到100.0,但有少量样本超出此范围(79个样本,占总数的0.3305%)。数据集适用于表格回归任务,特别是在生物学、CRISPR和基因组学研究中。数据集提供了两种配置:默认的train/validation/test映射和用于嵌套交叉验证的折叠分割。数据集采用CC-BY-4.0许可证发布。
创建时间:
2026-01-27
搜集汇总
数据集介绍
构建方式
在基因组编辑领域,精确预测CRISPR-Cas9系统的靶向效率对于推进基因治疗和功能基因组学研究至关重要。Xiang2021-SpCas9数据集的构建整合了Luo2020与Kim2019两项先前研究的数据,通过系统化合并与清洗,形成了包含23,902个30碱基对序列的标准化集合。这些序列均在人源HEK293T细胞系中经过实验测量,获得了SpCas9核酸酶的切割效率值,数据以五折交叉验证的分区结构组织,并单独保留了测试集,确保了模型评估的严谨性与可复现性。
特点
该数据集的核心特征在于其专注于SpCas9核酸酶在人细胞中的靶向效率预测,为生物信息学模型提供了高质量的基准。数据以表格回归任务形式呈现,每个样本包含长度为30的DNA序列及其对应的效率测量值,效率范围理论上界为100.0,实际数据中存在极少量超出理论范围的观测。数据集提供了两种配置方案:默认的固定训练-验证-测试划分,以及专为嵌套交叉验证设计的五折划分,极大地方便了不同验证范式的机器学习研究。
使用方法
利用Hugging Face的`datasets`库,研究人员可以便捷地加载并使用该数据集。通过指定配置名称,用户可选择加载标准划分或五折划分。对于标准划分,直接调用`load_dataset`函数并指定`name="default"`即可获得训练集、验证集和测试集;若需要进行嵌套交叉验证,则选择`name="folds"`配置,从而获取五个独立的训练折叠和一个独立的测试集。这种设计使得数据集能够无缝集成到现有的机器学习工作流中,用于开发和评估预测gRNA效率的计算模型。
背景与挑战
背景概述
在基因组编辑领域,CRISPR-Cas9技术凭借其高效性与精准性,已成为生物学研究的重要工具。2021年,由Xiang等人发表于《自然通讯》的研究,整合了Luo 2020和Kim 2019的数据,构建了xiang2021-spcas9数据集,专注于SpCas9核酸酶在人类HEK293T细胞系中的靶向效率预测。该数据集包含约2.4万条30碱基对序列及其切割效率测量值,旨在通过融合序列与结构信息的嵌入方法,提升gRNA效率预测的准确性,为基因编辑的优化与应用提供了关键数据支持。
当前挑战
该数据集致力于解决CRISPR-Cas9系统中gRNA靶向效率预测的挑战,其核心问题在于如何准确建模序列特征与生物活性之间的复杂关系,以克服传统方法在泛化性与鲁棒性上的局限。在构建过程中,研究人员面临数据整合的难题,需统一不同来源实验的测量标准与质量控制,同时处理少量效率值超出理论范围的数据异常,确保数据集的可靠性与一致性,为机器学习模型提供稳健的训练基础。
常用场景
经典使用场景
在基因组编辑领域,CRISPR-Cas9技术的靶向效率预测是核心挑战之一。Xiang 2021 SpCas9数据集通过整合Luo 2020和Kim 2019的研究成果,提供了约2.4万条30碱基对序列及其在人类HEK293T细胞系中测量的SpCas9切割效率数据。该数据集最经典的使用场景是训练和评估机器学习模型,以预测gRNA序列的编辑效率,支持交叉验证和独立测试,为算法开发提供了标准化的基准平台。
实际应用
在实际应用中,Xiang 2021 SpCas9数据集被广泛用于开发高效的gRNA设计工具,辅助科研人员在基因功能研究、疾病模型构建和基因治疗中筛选高活性靶点。例如,在癌症基因编辑或遗传病矫正实验中,基于该数据集的预测模型可以显著降低实验成本和时间,提高编辑成功率,从而加速生物医学研究的转化进程。
衍生相关工作
该数据集衍生了一系列经典研究工作,包括基于深度学习的效率预测模型如CNN和Transformer架构的优化,以及多模态融合方法的探索。这些工作进一步拓展了CRISPR-Cas9效率预测的边界,促进了如DeepSpCas9和CRISPR-Net等工具的发展,为后续大规模基因组编辑数据的分析和应用奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


