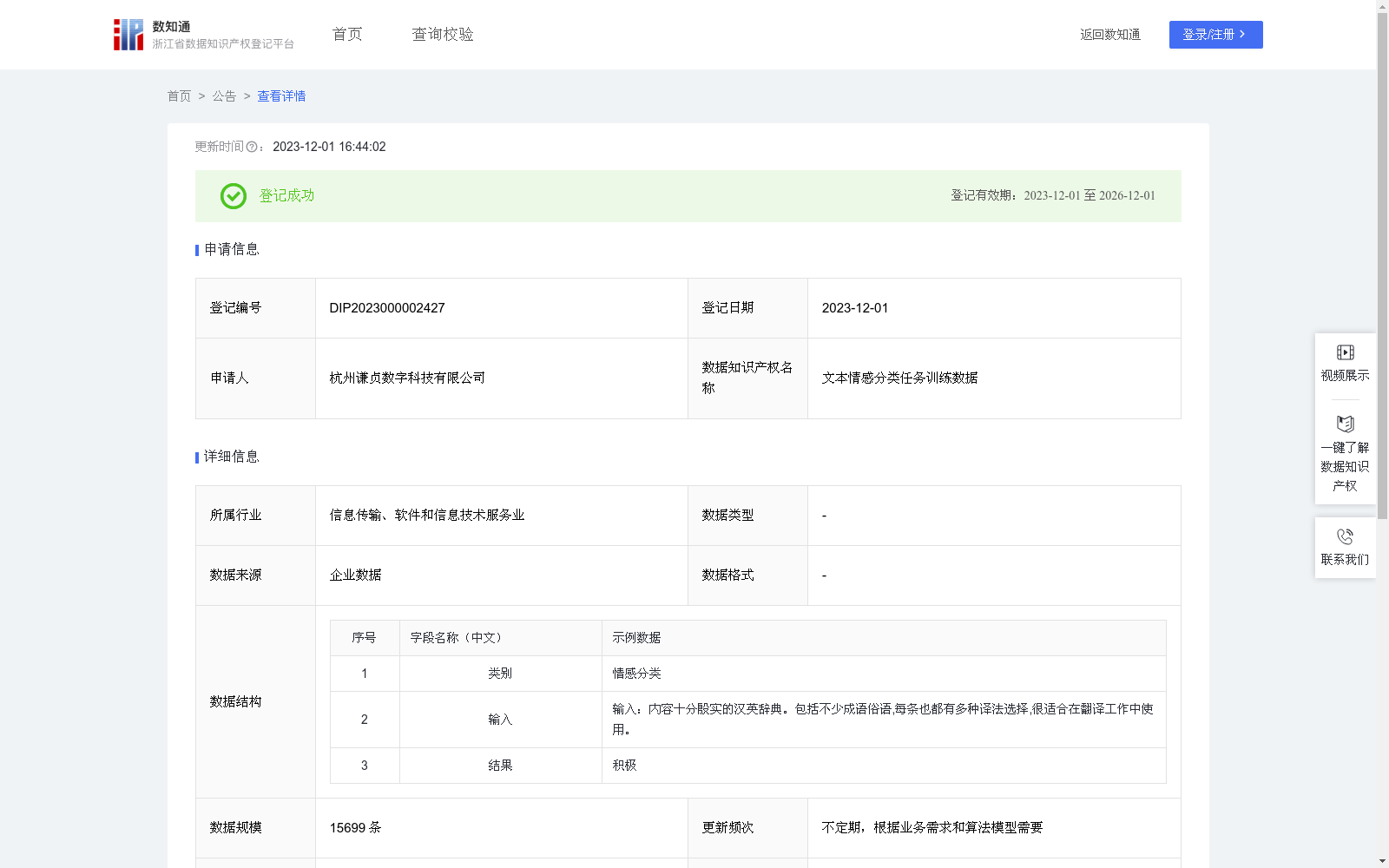
文本情感分类任务训练数据
收藏浙江省数据知识产权登记平台2023-12-01 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/15966
下载链接
链接失效反馈官方服务:
资源简介:
文本情感分类任务是指利用机器学习或深度学习技术对文本内容中的情感倾向进行分类,如“正面”、“负面”。这个任务可以帮助企业、机构和个人更好地理解文本数据中的情感趋势,以做出更为明智的决策。企业、机构和个人可以通过本数据训练自己的文本情感分类模型,用于自动化对文本进行情感分类任务。
具体应用场景:
品牌声誉管理:企业可以使用情感分类技术分析社交媒体、论坛和评论中关于其产品或服务的反馈,以调整策略、改进产品或提供更好的服务。
客户反馈分析:企业可以利用情感分类技术自动筛选用户反馈,快速找出正面或负面的评价,进而进行更深入的分析和响应。
新闻和文章的情感分析:新闻机构和研究者可以通过情感分类技术了解新闻事件或文章的公众情感反应。
金融市场预测:投资者和研究者可以利用情感分类技术分析与金融市场相关的新闻、社交媒体内容等,以预测市场的未来走势。
数据适用的范围、对象:
范围:任何形式的文本数据,如社交媒体帖子、新闻文章、产品评论等。
对象:企业、政府机构、研究机构、个人等。文本情感分类算法是一种文本分析技术,旨在自动判断和分类文本中所表达的情感或情绪,如正面、负面。这通常通过从文本中提取特征并使用机器学习或深度学习模型进行分类实现。
核心组件:
1、文本预处理:涉及到清理和格式化文本,包括去除停用词、标点、数字,进行词干提取或词形还原。
2、特征提取:将文本转换为算法可以识别的特征。常见方法有词袋模型 (BoW)、TF-IDF、Word2Vec、BERT嵌入等。
3、模型训练:使用标注数据训练分类器。常见的算法有朴素贝叶斯、支持向量机、决策树、随机森林、卷积神经网络 (CNN)、递归神经网络 (RNN) 等。
4、评估与优化:使用验证集评估模型的准确性、召回率、F1得分等,并进行必要的参数调整或结构优化。
The text sentiment classification task refers to classifying the emotional tendency in text content using machine learning or deep learning technologies, such as "positive" and "negative". This task enables enterprises, institutions and individuals to better understand the emotional trends in text data and make more informed decisions. Enterprises, institutions and individuals can use this dataset to train their own text sentiment classification models for automated text sentiment classification tasks.
Specific application scenarios:
Brand Reputation Management: Enterprises can use sentiment classification technologies to analyze feedback about their products or services on social media, forums and reviews, so as to adjust strategies, improve products or provide better services.
Customer Feedback Analysis: Enterprises can use sentiment classification technologies to automatically screen user feedback, quickly identify positive or negative reviews, and then conduct in-depth analysis and response.
Sentiment Analysis of News and Articles: News organizations and researchers can use sentiment classification technologies to understand the public emotional response to news events or articles.
Financial Market Forecasting: Investors and researchers can use sentiment classification technologies to analyze news, social media content and other materials related to financial markets to predict the future trend of the market.
Scope and applicable objects of the dataset:
Scope: Any form of text data, such as social media posts, news articles, product reviews, etc.
Objects: Enterprises, government agencies, research institutions, individuals, etc. Text sentiment classification algorithm is a text analysis technology that aims to automatically judge and classify the emotions or sentiments expressed in text, such as "positive" and "negative". This is usually achieved by extracting features from text and using machine learning or deep learning models for classification.
Core components:
1. Text Preprocessing: It involves cleaning and formatting text, including removing stop words, punctuation, numbers, and conducting stemming or lemmatization.
2. Feature Extraction: Convert text into features recognizable by algorithms. Common methods include Bag-of-Words (BoW), TF-IDF, Word2Vec, BERT embeddings, etc.
3. Model Training: Train classifiers using labeled data. Common algorithms include Naive Bayes, Support Vector Machine (SVM), Decision Tree, Random Forest, Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), etc.
4. Evaluation and Optimization: Use validation sets to evaluate the accuracy, recall, F1 score and other metrics of the model, and conduct necessary parameter adjustment or structural optimization.
提供机构:
杭州谦贞数字科技有限公司
创建时间:
2023-10-26
搜集汇总
数据集介绍
特点
该数据集为文本情感分类任务训练数据,包含15699条企业数据,适用于多种文本情感分析场景,如品牌声誉管理和客户反馈分析。数据已在浙江省知识产权区块链公共存证平台存证。
以上内容由遇见数据集搜集并总结生成


