bifrost-translation-source-classifier-dataset
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/NbAiLab/bifrost-translation-source-classifier-dataset
下载链接
链接失效反馈官方服务:
资源简介:
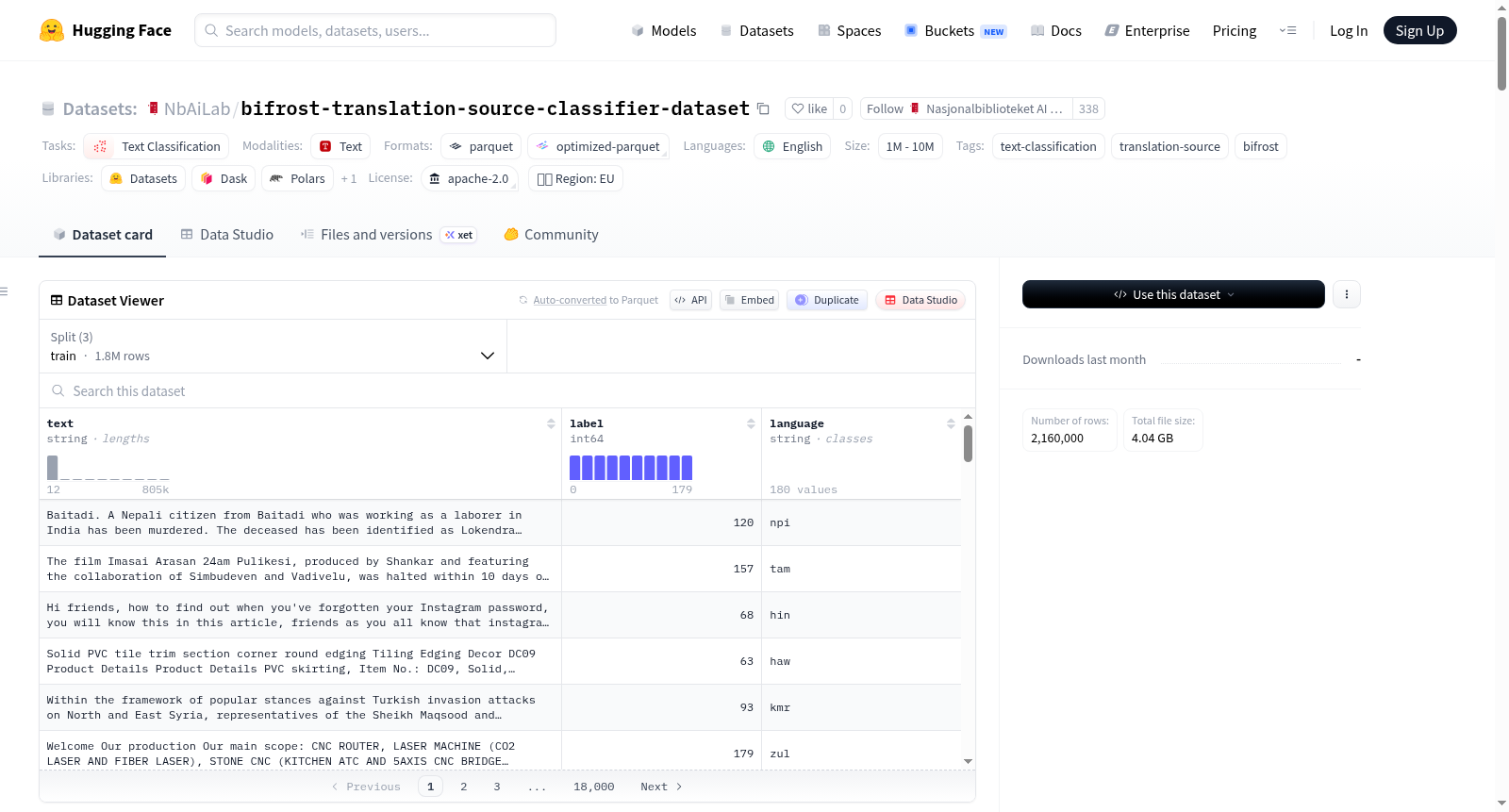
Bifrost翻译源分类器数据集是一个用于训练翻译源分类器的数据集,包含英文文本及其原始翻译来源语言的标签,以及作为控制类的原生英文文本。所有文本均为英文,标签指示文本的原始翻译来源语言(或en表示原生英文)。该数据集旨在帮助分类器学习检测原始语言的文化和风格痕迹。数据集包含180种语言,每种语言有10,000个训练样本、1,000个验证样本和1,000个测试样本,总计2,160,000个样本。数据来源于HuggingFaceFW/finetranslations(翻译文本)和HuggingFaceFW/fineweb(原生英文文本)。数据集包含三个字段:text(英文文本,字符串类型)、label(类别ID,整型)和language(源语言代码,字符串类型)。
The Bifrost Translation Source Classifier Dataset is a curated dataset developed for training translation source classifiers, containing English texts paired with labels indicating their original source languages of translation, plus native English texts serving as control samples. All texts are in English, with labels specifying the original source language of the translation; 'en' is used to denote native English texts. This dataset is designed to enable classifiers to learn to detect cultural and stylistic traces left by the original source languages. The dataset covers 180 distinct languages, with 10,000 training samples, 1,000 validation samples, and 1,000 test samples per language, resulting in a total of 2,160,000 samples. The dataset is sourced from HuggingFaceFW/finetranslations (for translated texts) and HuggingFaceFW/fineweb (for native English texts). It includes three core fields: `text` (English text, string type), `label` (category ID, integer type), and `language` (source language code, string type).
提供机构:
Nasjonalbiblioteket AI Lab
创建时间:
2026-04-27
原始信息汇总
数据集概览:Bifrost Translation-Source Classifier Dataset
基本元信息
- 数据集名称:Bifrost Translation-Source Classifier Dataset
- 语言:英语(en)
- 许可证:Apache-2.0
- 任务类别:文本分类(text-classification)
- 数据集规模:1,000,000 ~ 10,000,000 条样本(实际 2,160,000 条)
数据集描述
该数据集用于训练 Bifrost 翻译源语言分类器。所有文本均为英语,标签表示该文本原始的翻译源语言(即从哪种语言翻译成英语),其中 en 类别代表原生英语文本。分类器通过学习识别原文语言在文化和风格上的痕迹,从而判断英语文本的原始语言来源。
数据来源
- 翻译文本:来源于 HuggingFaceFW/finetranslations
- 原生英语文本:来源于 HuggingFaceFW/fineweb 的 sample-10BT 子集
数据集统计
- 语言数量:180 种语言(含原生英语
eng) - 每语言训练样本:10,000 条
- 每语言验证样本:1,000 条
- 每语言测试样本:1,000 条
- 总样本数:2,160,000 条
数据集拆分
| 拆分 | 样本数量 |
|---|---|
| train | 1,800,000 |
| val | 180,000 |
| test | 180,000 |
数据列说明
- text(字符串类型):英语文本内容
- label(整数类型):类别 ID
- language(字符串类型):源语言代码(如
arb、cmn、eng等)
使用示例
python from datasets import load_dataset
ds = load_dataset("NbAiLab/bifrost-translation-source-classifier-dataset") train = ds["train"] val = ds["val"] test = ds["test"]
支持的语言代码列表(部分示例)
数据集包含 180 种语言,涵盖广泛的语言类型,如阿拉伯语(arb)、中文(cmn)、英语(eng)、法语(fra)、德语(deu)、印地语(hin)、日语(jpn)、西班牙语(spa)等。完整语言代码列表详见 README。
搜集汇总
数据集介绍
构建方式
该数据集专为Bifrost翻译源语言分类器而设计,汇聚了2180万条英文文本,每条文本均被标注出其原始翻译来源语言,并包含原生英文文本作为对照类别。数据集的翻译文本源自HuggingFaceFW/finetranslations语料库,原生英文文本则取自HuggingFaceFW/fineweb的sample-10BT子集。构建时,针对180种语言,每种语言均分配了10,000条训练样本、1,000条验证样本与1,000条测试样本,确保了各类别在数量上的均衡分布,为模型学习不同语言在英文翻译中遗留的文化与风格痕迹提供了坚实基础。
特点
该数据集的显著特点在于其跨越180种语言的广泛覆盖,囊括了从常见语言(如汉语、西班牙语)到小众语言(如阿卡德语、科西嘉语)的多样性文本。每条数据包含text(英文文本)、label(整数类别ID)及language(源语言代码)三列,结构简洁明了。通过将翻译文本与原生英文文本对比,分类器能够精准捕捉不同源语言在词汇选择、句法结构及文化隐喻上的独特印记。这一设计使其在低资源语言鲁棒性与多语言迁移能力上表现卓越,适用于探索翻译文本中隐含的语言特征。
使用方法
使用该数据集可通过HuggingFace Datasets库便捷加载:调用load_dataset("NbAiLab/bifrost-translation-source-classifier-dataset")即可获取训练集、验证集与测试集。数据已按照预设比例划分,支持直接用于文本分类任务的模型训练与评估。用户可基于text字段作为输入特征,label字段作为监督信号,借助Transformer等框架构建分类器。对于希望深入分析源语言痕迹的研究者,也可将language字段用于细粒度评估或跨语言对比实验,从而挖掘翻译过程中保留的原生语言特质。
背景与挑战
背景概述
在神经机器翻译领域,译文质量的评估往往忽视了源语言文化痕迹的干扰,而识别文本是否源自翻译以及原始语言对于理解语言迁移现象至关重要。为此,挪威国家图书馆(NbAiLab)于近期推出了Bifrost Translation-Source Classifier Dataset,这是一个专注于英语文本翻译源语言分类的大规模数据集。该数据集囊括了180种语言,共计216万条英文文本,每条文本均标注了其源翻译语言或母语英语。其核心研究问题在于训练一个分类器,能够敏锐地捕捉不同语言在翻译过程中留下的文化及风格印记。该数据集依托HuggingFaceFW/finetranslations与fineweb两个来源构建,为跨语言文本分析、机器翻译质量评估及语言学研究提供了宝贵的基准资源,推动了机器翻译可解释性与细粒度分析的发展。
当前挑战
该数据集所面临的挑战具有双重性。在领域问题层面,其需要解决的不仅是简单的文本分类任务,更是要精准识别多语言翻译中固有的源语言痕迹,这要求模型能够区分语言风格、文化隐喻及语法结构上的微妙差异,克服翻译过程中源语言特征逐渐淡化的难题。在构建过程中,挑战则更为复杂:首先,从180种语言中采集并平衡高质量翻译文本极具难度,需确保每种语言样本量一致以避免数据偏差;其次,标注系统既要涵盖稀有语言,还需应对多义词或歧义结构带来的标签模糊问题;最后,从fineweb中筛选母语英语文本时,需剔除潜在的翻译污染,保证控制类别的纯净性,这对数据清洗与质量验证提出了极高要求。
常用场景
经典使用场景
在跨语言自然语言处理与机器翻译质量评估的交叉领域中,bifrost-translation-source-classifier-dataset常被用作训练翻译源语言检测的分类器基础数据。该数据集汇集了涵盖180种语言、总计逾216万条英文文本,其中包含从不同源语言翻译而来的文本以及原生英语语料。研究者利用这些标注数据,构建能够从英文译文中敏锐捕捉源语言文化与行文痕迹的模型,从而实现对文本翻译来源的精准识别,为多语言翻译溯源与翻译风格分析提供了坚实的实验基石。
实际应用
在实际应用层面,该数据集训练的翻译源语言分类器可广泛集成于多语言内容审核、机器翻译系统鲁棒性检测以及翻译辅助平台中。例如,在翻译质量保障环节,分类器能够自动甄别翻译文本背后可能的源语言干扰,提示译员或机器系统调整处理策略;在跨语言舆情监控场景中,分析文本的翻译来源可以帮助判断信息的流通轨迹与文化背景。此外,该数据集还为多语言数字人文学者提供了量化分析工具,助力大规模语料库中的翻译文本识别与来源标注工作,显著提升了海量多语言数据处理效率。
衍生相关工作
依托bifrost数据集,学界与工业界衍生出了一系列富有影响力的工作。一方面,研究者基于该数据集优化了多语言分类模型的架构,例如利用对比学习策略增强对细微语言标记的感知能力,或在少样本场景下引入元学习提升分类泛化性能。另一方面,该数据集激发的翻译源语言检测任务被拓展至更广阔的场景,如融合语言指纹特征进行翻译文本的伪造检测,以及结合领域适应技术实现跨语域翻译溯源。这些衍生工作进一步验证了bifrost数据集在促进翻译分析智能化与精细化发展中的核心驱动作用。
以上内容由遇见数据集搜集并总结生成


